直观:网页数据采集难点
优采云 发布时间: 2022-10-11 06:07直观:网页数据采集难点
摘要:随着网页制作和网站技术的发展,ajax、html5、css3等新技术层出不穷,给网页数据采集的工作带来了很大的困难。让我们来看看常见的。网页数据采集有什么难点。
随着网页制作的发展,网站技术、ajax、html5、css3等新技术层出不穷,给网页数据采集的工作带来了很大的困难,让我们来看看看看常见的网页数据采集有哪些难点?
1、网站结构复杂多变
网页本身基于html这种松散的规范,经历了各大浏览器混战的时代,每个IT巨头都有自己的标准,互不兼容,导致网页非常复杂多变结构体。从专业上讲,网页是半结构化数据,也就是说不是结构化的,而网页数据采集本身就是计算机完成的工作。众所周知,计算机最擅长执行重复性任务。工作,也就是必须有严格规则的东西,所以网页结构的多变意味着web采集工具必须能够适应变化才能做好。这说起来容易,但实现起来却非常困难。优采云采集器 使用一个非常简单的原则来实现这一点:自定义流程。我们认为,只有定制做一件事的整个过程,才能说软件能够适应变化,因为不同的处理需要根据不同的情况进行,不同的过程就是不同的处理。但仅仅拥有自定义流程是不够的。为了真正适应变化,组合过程需要能够处理各种情况。该网页是供人们查看的。因此,只要每个流程步骤都可以模拟人的操作,那么在将人连接到互联网时的各个操作步骤都是根据情况而定的。结合起来,可以模拟在电脑中操作网页的情况。优采云采集器 考虑到计算机和人类处理网络数据的特点,
2.各种网络数据格式
网页上显示的内容,除了有用的数据外,还有各种无效信息、广告、链接等。即使是有效信息,也有各种显示方式、列表、表格、自定义结构、列表-明细页面、分页显示,甚至鼠标点击显示、鼠标滑动显示、输入验证码显示等,网页上出现的数据格式多样化也是一个难点。因此,为了能够处理好,提取数据的逻辑必须非常智能,必须对提取的数据进行一定程度的处理。
3.使用ajax异步加载数据
异步加载,也称为ajax,是一种使用脚本更新部分页面数据而不重新加载整个页面的技术。这对现在几乎所有 采集器 来说都是一个致命的障碍。因为现在几乎所有的采集器都使用post方式,也就是向web服务器发送请求,获取响应字符串,然后解析字符串截取数据。ajax会导致获取到的字符串中根本没有数据,只有脚本程序,执行脚本时会加载数据。对于 post采集器 来说,这是一个无法逾越的障碍,因为先天的原则不足以处理这种情况。对于这种问题,可以使用优采云采集器来处理,因为优采云采集器模拟人为操作,没有post,也没有解析字符串, 只是模拟人类操作网页的行为,无论网页后端以何种方式加载数据,当数据显示在网页上时,优采云采集器都可以将数据提取到一种视觉方式。所以它可以轻松处理ajax加载的数据。一句话,只要你能打开一个网站看到数据,就用优采云采集器捕获这个数据。
4. 网站访问频率限制
现在几乎所有的网页数据采集工具都是单机程序,也就是说他能使用的最大资源就是单台电脑的所有资源,比如内存、cpu、带宽等,当处理更少的网页这个没问题,但是如果你想采集大量的网页,就得采用多线程等技术来加快访问网页的速度。当然,对方网站一般都有一些安全措施来保证单个IP,也就是不能太快访问单个电脑,否则会造成太大压力。当访问速度过快时,一般会封锁IP,限制其继续访问,从而导致采集中断。优采云采集器使用云采集,每个云采集
5. 网站访问不稳定
网络不稳定,这种现象很常见,网站也不稳定。如果网站一次访问压力太大,或者服务器有问题,可能无法正常响应用户查看网页的请求,对于人来说,问题不大偶尔出错,重新打开网页或者等待一段时间,然后对于网页数据采集工具,对于突发情况比较麻烦,因为不管发生什么,人都会来根据情况制定应对策略,但程序只能按照既定逻辑运行。一旦出现意外情况,很可能会因为不知道如何处理而崩溃或者逻辑中断。为了处理这些情况,优采云采集器 内置了一套完整的逻辑判断方案,允许用户自定义网站访问不稳定时如何处理各种情况。因此,当网站发生错误时,优采云采集器可以等待、重试,或者采集任何其他用户定义的流程逻辑,比如skip、back、然后刷新等,甚至重新打开登录页面,重新登录等,用户可以自定义判断条件和处理流程,从而应对各种不稳定的情况。
6.预防采集措施
除了上述困难之外,一些网站为了屏蔽一些恶意采集、复制内容、不尊重版权的做法,并采取一些技术措施防止他人采集,例如,验证码、点击显示数据等可以识别人和机器,在一定程度上防止了恶意采集行为,但也给正常浏览和采集带来了障碍。优采云采集器内置了一些功能,比如识别验证码、点击元素等,可以帮助用户突破这些限制。但是优采云团队一直主张采集数据需要授权,即如果你需要采集一个网站数据,那么你应该先联系网站
本文是网页数据采集系列原创文章的第五篇。网页数据采集系列将对网页数据采集这个话题进行全面深入的探讨。欢迎大家讨论,互相学习。
讨论请进群:web data采集,群号:254764602,加群密码:web data采集
本文于2013年11月9日首发于“优采云采集器”,转载请注明出处。
直观:新手独立站卖家篇之-商品采集/同步
上一篇文章给大家分享了如何在SHOPYY后台上传商品。今天给大家分享一下如何快速采集产品,提高效率。
今天给大家介绍三个非常实用的插件。
1. Shopyy后台采集速卖通产品(含属性带图、组合号、发布小语种产品)
(更新 210506)SHOPYY采集,通过 Google Chrome 扩展程序,采集阿里巴巴,TB 1688,亚马逊,SHOPIFY。
2.速卖通采集(你可以采集速卖通国际站的产品,输入你要的产品id到采集,系统会自动上架几分钟在商场的仓库,方便进行二次编辑上架)
3. Shopify备份(Shopify备份站,绑定店铺后可以实时同步Shopify的产品和会员)
如图:教程在SHOPYY后台应用,在应用商店搜索关键词采集,即可免费安装使用。
1. Shopyy采集平台帮助:
点击下载操作指南中的压缩包:
下载后,先解压压缩包,解压后打开文件夹,可以看到一个文件(文件名和外面的文件夹一样),然后拖到谷歌浏览器扩展应用中。
chrome://extensions/ 这是扩展的URL,直接复制粘贴打开,然后加载解压后的扩展。
然后就可以打开目标站点的采集产品页面,点击谷歌浏览器扩展列表,找到Shopyy采集平台,打开配置页面,以亚马逊为例。
在弹窗中打开“店铺管理”,添加店铺信息。
添加新店铺信息时请注意以下操作:先将这三栏一次性填好,将API地址复制到Api Token栏中,设置保存,然后返回此弹窗修改Api 令牌。
平台:根据当前打开的页面自动识别并展示
类别:默认other_categery,用户可自定义修改
专辑名称:必须与当前打开的产品中的专辑名称相同为采集
添加新的同步商店,并填写商店名称,方便您识别;
store API地址和store Api Token可以直接在插件介绍页面复制(见教程第一张截图)。
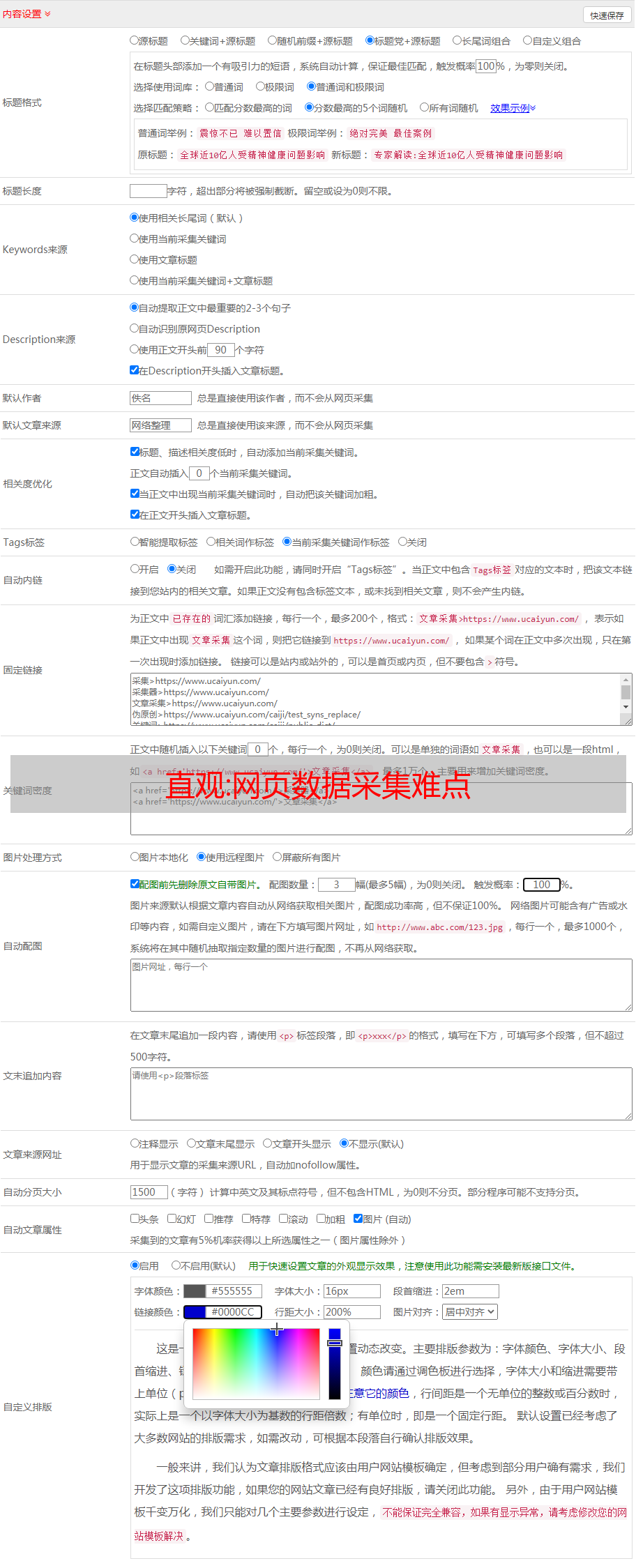
修改店铺信息后,可以启动采集产品,采集时会在弹窗中自动识别当前平台和产品链接,并可自定义分类和专辑名称并编辑。
当前产品页面加载完成后,在弹窗点击“确定”,将产品采集添加到后台插件中(注意:一定要在当前产品页面后执行采集已加载)
采集成功了,店名右边会有打勾。
插件“爬取任务”列表手动同步,商品同步到主商城后台商品管理列表(商品默认同步到下架列表)。
后端产品管理下架列表显示同步的产品。
2.速卖通采集教程
安装应用,点击“访问”跳转到设置页面。
点击“速卖通产品管理”进入列表页面,列表中显示了所有已经采集的产品。
点击右上角“添加速卖通产品”,进入入口信息页面。
【速卖通产品ID】从速卖通网站复制需要采集的产品ID,获取产品ID的方法如下图所示。
注意:如果有多个产品一起采集,每个产品ID应该用逗号或换行符分隔
【产品发布语言】 下拉选择要发布的语言
【商品发布市场】 根据之前选择的发布语言选择对应国家
以上信息设置好后,点击“保存信息”,产品进入列表,您可以点击手动同步。
同步成功后,列表中会显示同步状态。
同步成功的商品会自动显示在SHOPYY后台商品列表中,方便二次编辑再上架。
同步到SHOPYY后台的时候,因为图片采集需要时间,所以这里的商品图片过几分钟就不会显示了。
3. Shopify Backup 同步备份。
安装插件后,点击访问,点击“配置列表”,点击右上角“添加配置”。
编辑配置
1)Shopify店铺名称:填写shopify店铺名称(shopify店铺左上角显示的店铺名称)
2)Shopify店铺地址:请填写临时域名,格式参考问号()中的提示
3)默认分类:导入shopyy的默认分类前缀(也可以理解为上级分类)。用户还可以自定义前缀
例如:如果shopify产品类别名称为“shoes”,可以在这里自定义插件的默认前缀,也可以直接使用默认的“shopify categroy”,同步的产品类别会变成shopify categroy->shoes
提交保存后,进入列表操作“授权”
点击授权后,跳转到shopify页面,点击“安装未列出的应用”按钮,操作完成,页面提示授权成功。
列表中的状态显示“已授权”
Shopify授权成功后,系统会每隔一小时自动同步Shopify产品和用户数据。(大约一小时同步1000~1500个项目。)
商品同步记录(库存同步为shopify的库存)
用户同步记录。
注意:如果在shopify商店修改了产品信息或用户信息,已经同步到插件的产品将不再自动同步到插件。

