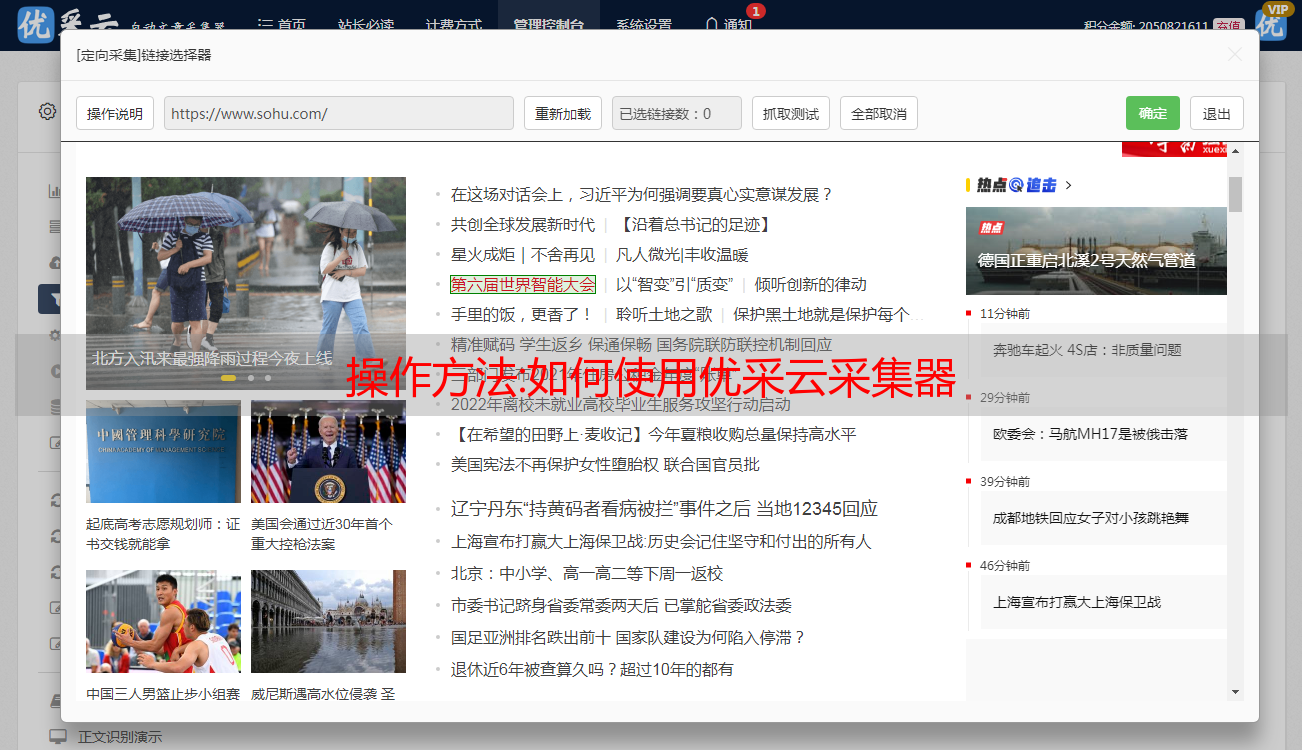
操作方法:如何使用优采云采集器
优采云 发布时间: 2022-10-09 14:18操作方法:如何使用优采云采集器
优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率。
主要功能
简而言之,使用 优采云 可以轻松采集从任何网页中精确获取所需的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1、财务数据,如季报、年报、财务报告,包括每日最新净值自动采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、关注各大地产相关网站、采集新房、二手房的最新行情;
7、采集主要汽车网站具体新车和二手车信息;
8、发现和采集潜在客户信息;
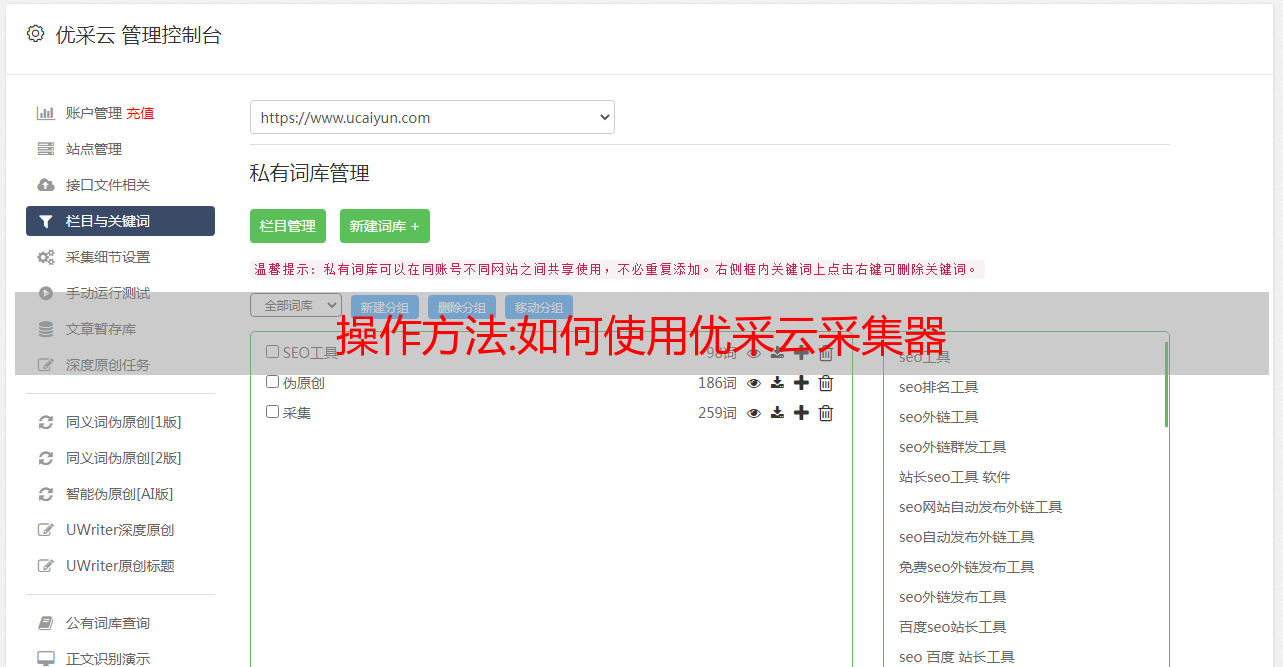
9、采集行业网站的产品目录和产品信息;
10. 同步各大电商平台商品信息,可在一个平台发布,在其他平台自动更新。
产品优势
便于使用
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
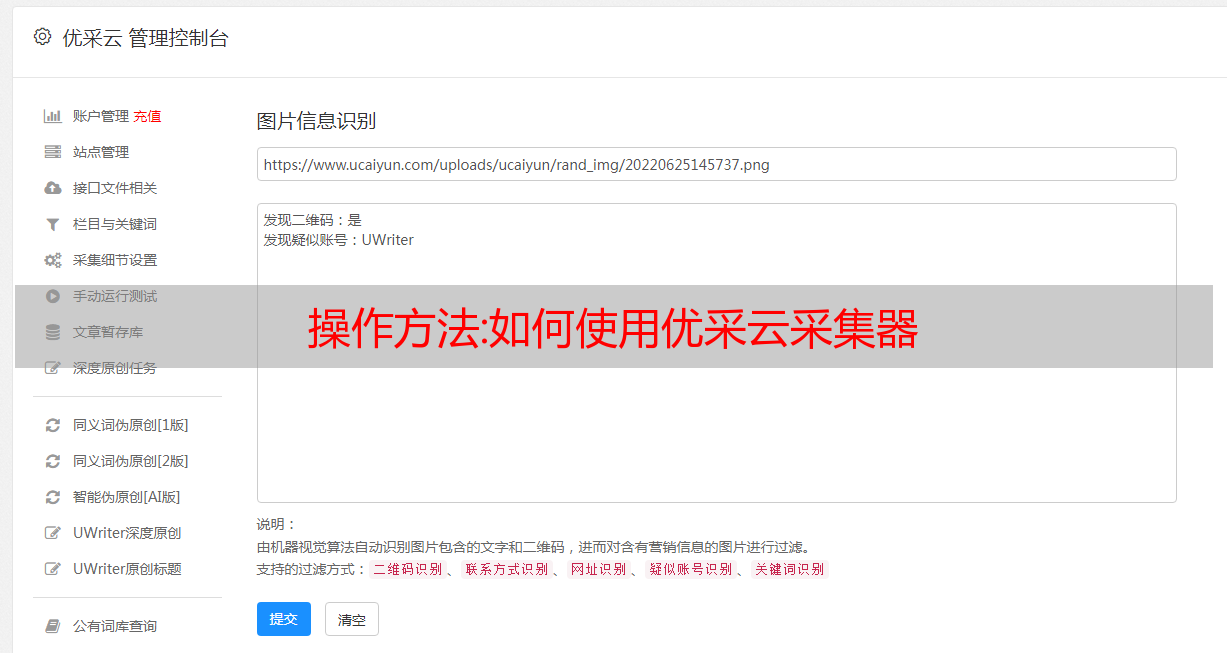
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
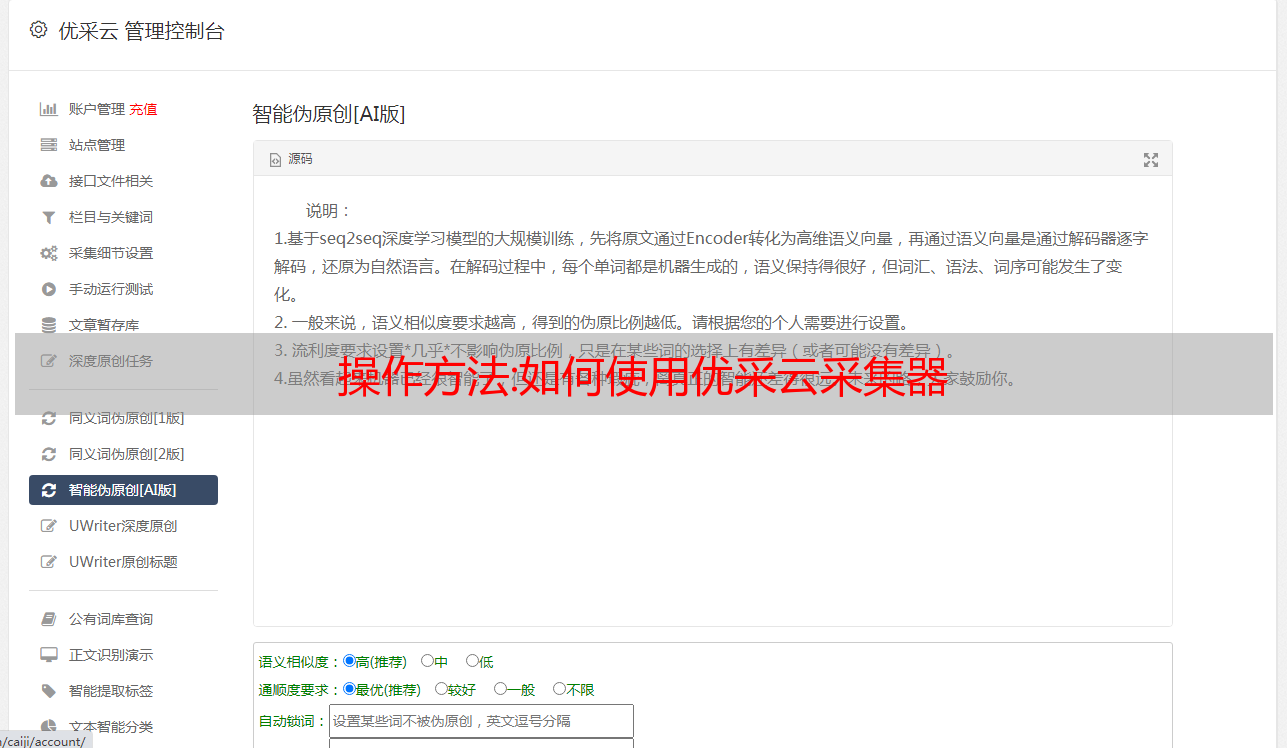
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
云端采集器 科学的方法:这些不用编程的爬虫工具,你一定要知道
随着Scrapy等框架的火爆,用编程语言编写爬虫已经成为一种时尚,看来网上的每个人都对爬虫略知一二。
大神使用爬虫将学校所有重要的在线服务整合成一套JSON API,然后开发成一个App;
爬取了知乎 120,000个用户的头像,把长得像的头像放在一起方便浏览: 然后我采集了朋友的点击量,预测你(平均)最喜欢的人长什么样;
网友写了一个爬虫,根据标签爬下豆瓣上的所有书籍,根据已有的标签对豆瓣书籍进行排序检索,并按照分数从高到低排序。
……
这些有趣的故事都来自知乎上的一个热门话题:爬虫技术可以做哪些酷、有趣、有用的事情?
每个人都可以是爬行动物
在互联网的早期,编写爬虫是一项技术活动。总的来说,爬虫技术是搜索引擎不可或缺的一部分。
随着互联网技术的发展,编写爬虫的门槛一降再降,一些编程语言甚至直接提供了爬虫框架,比如python的Scrapy框架,让编写爬虫进入了“老百姓的家”。
我们发现写爬虫是一件很酷的事情,但即便如此,学习爬虫还是存在一定的技术障碍。
目前主流的爬虫方式是使用Python编程。Python 的强大是毋庸置疑的,但是初学者学习 Python 还是需要一两个月的时间。
有没有更简单的方法来抓取数据?答案是肯定的。
一些可视化爬虫工具使用策略来爬取特定数据。尽管它们不如自己的爬虫操作准确,但学习成本要低得多。下面介绍几个可视化爬虫工具。
家用工具
01 微软Excel
首先教大家一个使用Excel爬取数据的方法。此处使用 Microsoft Excel 2013 版本。让我们一步一步开始教学吧~
(1)新建一个Excel并打开,如下图
(2) 点击“数据”-“来自网站”
(3)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击Go,然后导入
选择导入位置,OK
(4) 结果如下图,怎么样,是不是很棒?
(5)如果要实时更新数据,可以在“数据”-“全部更新”-“连接属性”中设置,输入更新频率。
02 优采云
一款无需可视化编程的网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化采集、编辑和归一化数据,降低工作成本。
简易模式采集 步骤
是一款适合新手用户试用的采集软件。云功能强大。当然,爬虫老手也可以开发它的高级功能。
03 优采云
优采云是一款互联网数据采集、处理、分析、挖掘软件,采集功能齐全,不限网页和内容,任何文件格式均可下载,已知能采集99% 网页。
软件定位更专业、更精准。用户需要具备基本的 HTML 基础,能够理解网页的源代码和结构。不过软件提供了相应的教程,新手可以学习上手。
04 采集客户
一款简单易用的网页信息采集软件,可以采集网页文字、图表、超链接等网页元素。
操作比较简单,适合初级用户,在功能上没有太多特色,后续支付需求也很多。
05 优采云云爬虫
一种新颖的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化网页数据。
类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,这需要代码基础。
06 优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛<有三个类别:采集器、cms采集器 和博客采集器。
专注于论坛和博客文字内容的抓取,采集全网数据通用性不高。
外国工具
01 谷歌表格
使用Google Sheet爬取数据前,必须保证三点:使用Chrome浏览器、有Google账号、电脑翻墙。满足这三个条件就开始吧~
(1) 打开谷歌表格网站:/sheets/about/
(2)在首页点击“Go to Google Sheets”,然后登录自己的账号,可以看到如下界面,然后点击“+”新建一个sheet
新建的表格如下:
(3)打开要爬取的目标网站,一个全国实时空气质量网站pm25.in/rank,目标网站上的表结构如下图所示
(4)回到Google sheet页面,使用函数=IMPORTHTML(URL, query, index),“URL”为抓取数据的目标网站,在“Query”中输入“list”或“table” ",这取决于数据的具体结构类型。“索引”用阿拉伯数字填充,从1开始,对应网站中定义的哪个表或列表
对于我们要抓取的网站,我们在Google sheet的A1单元格中输入函数=IMPORTHTML("pm25.in/rank","table",1),然后回车即可获取数据.
(5) 将爬取的表保存到本地
是不是感觉超级简单?
02 你得到
这是一个程序员基于python 3开发的项目,已经在github上开源,支持64个网站,包括优酷、土豆、爱奇艺、B站、酷狗音乐、虾米……总之你可以想想它网站!
还有一个黑科技的地方,就算不在列表里网站,当你输入链接的时候,程序就会猜测你要下载什么,然后帮你下载。
当然you-get需要安装在python3环境下。用pip安装后,在终端输入“你得到+你要下载的资源的链接”,就可以等待采集资源了。
这里有中文说明书给你-get,按照说明书上写的步骤操作即可。
03 *敏*感*词*.io
Import.io 是一个基于 Web 的 Web 数据采集 平台,允许用户在不编写代码的情况下生成提取器。与国内大部分采集软件相比,Import.io更加智能,可以匹配生成相似元素列表,用户在输入网址时也可以一键采集数据。
Import.io 智能开发,采集简单,但是在处理一些复杂的网页结构方面比较薄弱。
04章鱼
Octoparse是优采云的海外版,采集页面设计简洁友好,全可视化操作,适合新手用户。
运行并获取数据
Octoparse功能齐全,价格合理,可应用于复杂的网页结构。如果你想在不翻墙的情况下使用 Amazon、Facebook、Twitter 等平台,Octoparse 是一个选择。
05 视觉网络开膛手
Visual Web Ripper 是一个支持各种功能的自动化网页抓取工具。
适用于一些高级和采集困难的网页结构,用户需要有较强的编程能力。
06 内容抓取器
Content Grabber 是最强大的网络抓取工具之一。它更适合具有高级编程技能的人,并提供了许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
Content Grabber 网页适用性强,功能强大。它们不完全为用户提供基本功能,适合具有高级编程技能的人。
07 莫森达
Mozenda是一款基于云的数据采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
适合有基本爬行经验的人。
- 数据城堡 -

