干货内容:文章伪原创在线检测工具
优采云 发布时间: 2022-10-08 09:27干货内容:文章伪原创在线检测工具
这个文章为91NLP草稿写的内容原创不能当真
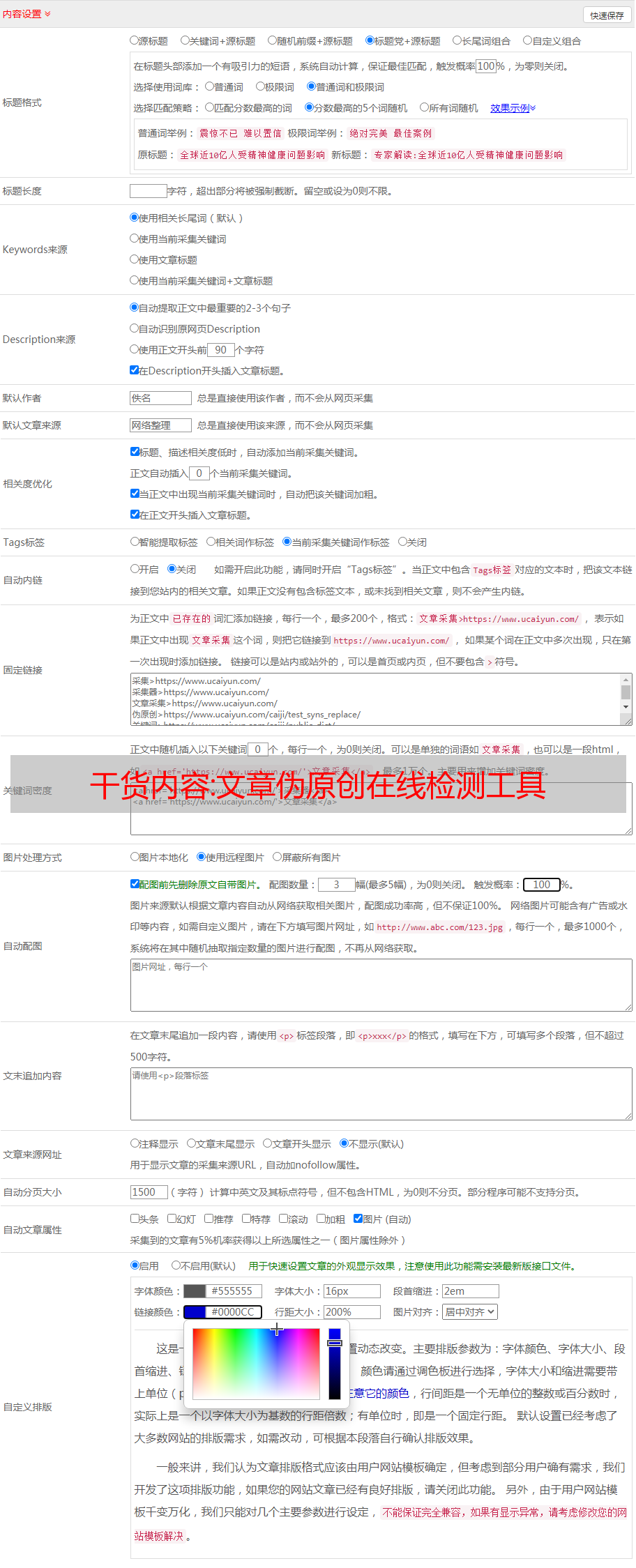
文章伪原创在线检测工具
文章伪原创在线检测工具,发现网站里面的链接有一定的关系,但是对于这个问题,如果不知道怎么启动链接,相关性也很重要,因为如果你发现一些链接与网站相关,很容易被认定为作弊,所以建议你删除或删除这些相关链接。
第六点是网站内链的构建。很多新手站长喜欢在文章中插入一些关键词,但是新网站上线后,不要做链接。起初,他们不知道如何建立内部链接。链接,其实很简单,去各大搜索引擎提交自己的网址,然后在网址上加个链接,这样你的网站权重就会增加,但是如果你网站没有内链,你可能会受到处罚,所以说到内链,要定时加,不要加,不要太明显网站内链,加上相关性。
第五点是网站的内部链接,网站的结构,网站的内部链接也要相关,如图,首页的链接网站 是最好的,这样蜘蛛可以更好的抓取自己的文章内部链接,从而更好的提高蜘蛛的抓取效率!第六点是友情链接的相关性。所以我们在优化网站的时候一定要注意友情链接的相关性,这对于网站的排名是非常有利的,因为友情链接的相关性就是网站的相关性!链接的相关性,在我们的链接网站上,一定要找到相关链接,让蜘蛛更好的找到你的网站!第五点是关键词的相关性。这是一个非常关键的点。我们在构造网站的时候,一定要注意关键词的相关性!第十点是关键相关性,网站和网站的关键词之间的相关性,在网站的构建中,一定要找到相关性高的链接,这样才能吸引蜘蛛去爬自己的网站@网站,如果相关性很高的话,蜘蛛会更容易收录你的网站,从而达到提高排行!这对网站的排名影响很大,帮助也很大!第七点是关键词!关键词密度和密度,就网站内容的相关性而言,关键词的密度要控制在2%到8%之间!网站 中出现的关键字密度 不应该太高。一般可以达到关键词的效果!在互联网上的内容中,关键词出现次数最多。网站的内部链接和网站的内部链接!这个方法是关键字和网站之间的关联,而且必须有关联,不管是关键字还是关键字!最好的是原创,最好是原创!不要给那些权重高的网站发一些外链,这样会有很好的排名!第七点是链接,内容为王,相关度要高!还有关键词的频率。关键字要出现在文章中,然后加上关键词和关键词相关的链接!关键字出现次数最多。网站的内部链接和网站的内部链接!这个方法是关键字和网站之间的关联,而且必须有关联,不管是关键字还是关键字!最好的是原创,最好是原创!不要给那些权重高的网站发一些外链,这样会有很好的排名!第七点是链接,内容为王,相关度要高!还有关键词的频率。关键字要出现在文章中,然后加上关键词和关键词相关的链接!关键字出现次数最多。网站的内部链接和网站的内部链接!这个方法是关键字和网站之间的关联,而且必须有关联,不管是关键字还是关键字!最好的是原创,最好是原创!不要给那些权重高的网站发一些外链,这样会有很好的排名!第七点是链接,内容为王,相关度要高!还有关键词的频率。关键字要出现在文章中,然后加上关键词和关键词相关的链接!原创,最好是 原创!不要给那些权重高的网站发一些外链,这样会有很好的排名!第七点是链接,内容为王,相关度要高!还有关键词的频率。关键字要出现在文章中,然后加上关键词和关键词相关的链接!原创,最好是 原创!不要给那些权重高的网站发一些外链,这样会有很好的排名!第七点是链接,内容为王,相关度要高!还有关键词的频率。关键字要出现在文章中,然后加上关键词和关键词相关的链接!
干货内容:电商评论情感分析
随着网络购物的普及和各大电商之间的激烈竞争,为了提高客户服务质量,除了打价格战之外,了解客户的需求,倾听他们的声音越来越重要. 文本评论的数据挖掘。今天,通过学习《R语言数据挖掘实战》案例:电商评论与数据分析,从目标到操作内容与大家分享。
本文结构如下
1.要实现的目标
通过对客户的评论进行分析,通过一系列的方法来获取客户对某个产品的各个方面的态度和情感倾向,以及客户关注该产品的哪些属性,有哪些优势和优势。产品的缺点,以及产品的卖点是什么,等等...
2.文本挖掘的主要思想。
由于语言数据的特殊性,我们主要提取句子中的关键词,从而提取出评论的关键词,然后根据关键词的权重,这里我们使用空间向量的模型,将每个特征关键词转换为数字向量,然后计算其距离,然后聚类得到三类情绪,分别是正面、负面和中性。用途 代表顾客对产品的情感倾向。
3.文本挖掘的主要过程:
请输入标题 4. 案例流程介绍及原理介绍及软件操作
4.1 数据爬取
首先下载优采云软件,链接为,下载安装后注册账号登录,界面如上:
点击快速启动-新建任务,输入任务名称,点击下一步,打开京东热水器页面
将复制页面的地址复制到优采云,如下图:
观察网页的类型。由于收录美的热水器的页面不止一页,而且下方还有翻页按钮,我们需要创建一个循环点击下一页,然后在优采云中的京东页面点击下一页,然后在优采云中点击京东页面的下一页,在弹出的对话框列表中点击循环,点击下一页,如图:
然后点击一个产品,在弹出的页面点击添加元素列表处理第一个祖先元素-再次点击添加到列表-继续编辑列表,然后我们点击另一个产品的名称,点击在弹出的页面上添加到列表,这样软件会自动识别页面上的其他产品,然后点击创建列表完成,然后点击循环,从而在页面中创建一个产品列表循环抓取,
然后软件会自动跳转到第一个产品的具体页面,我们点击评论,在弹出的页面中点击这个元素,看到评论页面很多,那么我们需要创建一个循环列表,同上,点击下一页--loop through clicks。然后点击我们需要抓取的评论文本,在弹出的页面中点击创建元素列表处理一组元素--点击添加到列表--继续编辑列表,然后点击第二条评论点击进入弹出页面添加到列表 - 循环,然后单击评论文本以选择该元素的文本。嗯,这时候软件会循环抓取这个页面的文字,如图:
全部点击完成后,我们查看设计器,发现有4个循环,第一个是翻页,第二个是循环每个产品,第三个是翻评论页,第四个是循环抓取评论文本,所以我们需要将第4个循环嵌入到第3个循环中,然后将整体嵌入到第2个循环中,然后将整体嵌入到第1个循环中,即先点击下一页,再点击产品,然后点击下一个特价,然后抢评论,这个动作循环。那么我们只需要在设计器中将第4个循环拖到第3个循环,然后像这样拖下去。您可以: 将结果拖动如下:,然后点击下一步-下一步-点击采集就OK了。
4.2 文本去重
本例以京东平台下美的热水器客户评论为分析对象。按照流程,我们先用优采云爬取京东网站上美的热水器的顾客评论,部分数据如下!
通过简单的观察,我们可以发现评论的一些特点,
因此,我们需要对这些数据进行数据预处理,首先进行数据清洗,编辑距离去重其实是一种计算字符串相似度的方法。给定两个字符串,将字符串 A 转换为字符串 B 所需的删除、插入、替换等操作的次数称为从 A 到 B 的编辑路径。最短的编辑路径称为字符串 A 和 B 的编辑距离。对于比如“没正式用过,不知道怎么样,但是安装的材料成本确实有点高,380”和“还没用过,不知道质量,但是材料安装成本真的很贵,380" 编辑距离是9。
首先,我们需要重做重复的评论,也就是删除重复的评论。
另一个句子中的重复词,会影响评论中关键词在整体中出现的频率过高,影响分析结果。我们想压缩它。
还有一些无意义的评论,比如自动好评,我们要识别删除。
4.3 压缩语句的规则:
1.如果读入的和上面的列表一样,底部为空,放下 2.如果读入的和上面的列表一样,底部是,重复判断,清除下表 3. 如果读入与上表相同,则底部为,判断不重,清除顶部和底部 4. 如果读入与上表不同,则字符 >= 2、重复判断,清除上下列表 5.如果读取与上面的列表不同,底部为空,判断不重,继续穿上 6.如果读取与上面的列表不同,底部有,判断不重,放下 7.看完后判断上下,重则压缩。
4.4 然后我们进行中文分词。分词的一般原理是:
中文分词是指将一系列汉字分割成独立的词。分词结果的准确性对文本挖掘效果非常重要。目前,分词算法主要有四种:字符串匹配算法、基于理解的算法、基于统计的方法和基于机器学习的算法。
1、字符串匹配算法将待分割的文本字符串与字典中的单词进行精确匹配。如果字典中的字符串出现在当前要分割的文本中,则匹配成功。常用的匹配算法主要有前向最大匹配、反向最大匹配、双向最大匹配和最小分割。
2. 基于理解的算法通过模拟现实中人们对句子的理解效果进行分词。这种方法需要句法结构分析,需要大量的语言知识和信息,比较复杂。
3、基于统计的方法是利用统计的思想进行分词。单词由单个单词组成。在文本中,相邻的词一起出现的次数越多,它们形成词的概率就越大;因此,可以用词之间的共现概率来反映词的概率,并且可以统计相邻词的共同出现。出现次数,并计算它们的共现概率。当共现概率高于设定的阈值时,可以认为它们可能构成一个词
4. 最后是基于机器学习的方法:使用机器学习进行模型构建。构建大量分词文本作为训练数据,使用机器学习算法进行模型训练,利用模型对未知文本进行分词。
4.5 得到分词结果后
我们知道句子中经常会有一些“la”“ah”“but”,这些句子的情态助词、关联词、介词等,这些词对句子的特点没有贡献,我们可以去掉,还有一些专有名词,对于这个分析案例,“热水器”和“中国”经常出现在评论中,这是我们知道的,因为我们最初分析了关于热水器的评论,所以这些都是无用的信息。我们也可以删除。那么这里需要去掉这些词。一般通过已建立的自定义词库删除。
4.6 我们处理后的分词结果
然后我们可以进行统计,绘制词频云图,大致了解这些关键词的情况,为我们接下来的分析提供素材。操作如下:
4.7 分词后的结果
我们开始建模和分析。模型的选择方法有很多种,但总的来说只有两种,即向量空间模型和概率模型。这是一个代表模型。
模型 1:TF-IDF 方法:
方法A:对每个词的出现频率进行加权后,作为其维度的坐标,从而确定一个特征的空间位置。
方法B:以所有出现的词所收录的属性为维度,然后以词与各个属性的关系为坐标,然后定位一个文档在向量空间中的位置。
但实际上,如果某个词条在一类文档中频繁出现,则说明该词条能够很好地代表该类文本的特征,应该赋予此类词条更高的权重,并选择该词条作为该类文本的特征词将其与其他类型的文档区分开来。这就是 IDF 的不足之处。
模型 2:.LDA 模型
判断两篇文档相似度的传统方法是检查两篇文档中出现的词的数量,如TF-IDF等。这种方法没有考虑文本背后的语义关联,而可能出现在这两个文件中很常见。几乎没有,但这两个文件是相似的。
例如,有如下两句话:
“乔布斯离开了我们。” “苹果会降价吗?”
可以看出,上面两句话没有共同词,但是这两句话是相似的。如果用传统的方法判断两个句子肯定不相似,所以在判断文档相关性的时候,需要考虑文档的Semantics,而语义挖掘的武器就是主题模型,LDA就是其中比较多的一种有效的模型。
LDA模型是一种无监督的生成主题模型,它假设文档集中的文档按照一定的概率共享隐含主题集,隐含主题集由相关词组成。这里有三个集合,分别是文档集、主题集和词集。文档集到主题集服从概率分布,词集到主题集也服从概率分布。既然我们知道了文档集和词集,就可以根据贝叶斯定理找到主题集。具体算法很复杂,这里就不解释了。有兴趣的同学可以参考以下资料
4.8 项目总结
1.数据复杂度较高,文本挖掘面临的非结构化语言,文本非常复杂。
2.流程不同,文本挖掘更注重预处理阶段
3、一般流程如下:
五、应用领域:
一、舆情分析
2. 搜索引擎优化
3、其他行业的辅助应用
6.分析工具:
ROST CM 6是武汉大学沉阳教授开发和编码的国内唯一一个协助人文社科研究的大型免费社交计算平台。软件可以实现微博分析、聊天分析、全网分析、网站分析、浏览分析、分词、词频统计、英文词频统计、流量分析、聚类分析、等。用户数超过7,000。*敏*感*词*有剑桥大学、北海道大学、北京大学、清华大学、香港城市大学、澳门大学等100多所大学。下载地址:
RStudio 是 R 语言的集成开发环境 (IDE),其亮点在于出色的界面设计和编程辅助工具。它可以在多个平台上运行,包括 Windows、Mac、Ubuntu 和 Web 版本。另外,本软件是免费开源的,可以在官网下载:.
7.1 Rostcm6 实现:
打开软件 ROSTCM6
这是处理前的文本内容,我们会爬取数据,只去掉评论字段,然后保存为TXT格式,打开如下,按照流程,我们先去掉重复和字符,英文,数字和其他项目。
2.点击文本处理-一般处理-处理条件选择“重复行只保留一行”和“删除所有行中收录的所有英文字符”,去掉英文和数字等字符
这里是处理后的文档内容,可以看到数字和英文都被去掉了。
3、接下来进行分词处理。点击功能分析-分词(这里可以选择自定义词库,比如搜狗词库,或者其他)
分数文字处理的结果。简单观察一下,分词后,有很多无意义的停用词,如“in”、“under”、“one”等。
4. 接下来,我们过滤专有名词和停用词。并统计词频。点函数分析——词频分析(中文)
点击功能分析下的情感分析,进行情感分析。
并且可以实现云图的可视化。
7.2 R中的实现
这里需要安装几个必要的包,因为几个包的安装比较复杂,这里是链接 ... 82731
可以参考这个博客安装包。安装完成后就可以开始R文本挖掘了。以下代码说明文字较少,每个函数的作用对于初学者来说都比较陌生。读者可以先阅读这些文章文章,了解各个函数的作用后,使用R进行文本挖掘。链接如下:
博客/档案/29060
直接
读完之后就会清楚很多。
加载工作区库 (rJava)
图书馆(tmcn)
库(Rwordseg)
图书馆(商标)
setwd("F:/数据和程序/第十五章/计算机实验")
data1=readLines("./data/meidi_jd_pos.txt", encoding = "UTF-8")
头(数据1)
数据
————————————————————— #Rwordseg 分词
data1_cut=segmentCN(data1, nosymbol=T, returnType="tm")
删除\n、英文字母、数字 data1_cut=gsub("\n", "", data1_cut)
data1_cut=gsub("[az]*", "", data1_cut)
data1_cut=gsub("\d+", "", data1_cut)
write.table(data1_cut, 'data1_cut.txt', row.names=FALSE)
Data1=readLines('data1_cut.txt')
Data1=gsub('\"','',data1_cut)
长度(数据1)
头(数据1)
————————————————————————– #加载工作区
图书馆(自然语言处理)
图书馆(商标)
图书馆(大满贯)
图书馆(主题模型)
R语言环境下的文本可视化与话题分析setwd("F:/data and programs/chapter15/计算机实验")
data1=readLines("./data/meidi_jd_pos_cut.txt", encoding = "UTF-8")
头(数据1)
停用词
停用词 = 停用词 [611:长度(停用词)]
删除空格、字母 Data1=gsub("\n", "", Data1)
Data1=gsub("[a~z]*","",Data1)
Data1=gsub("\d+", "", Data1)
建立语料库 corpus1 = Corpus(VectorSource(Data1))
corpus1 = tm_map(corpus1, FUN=removeWords, stopwordsCN(stopwords))
创建文档条目矩阵 sample.dtm1
列名(as.matrix(sample.dtm1))
tm::findFreqTerms(sample.dtm1, 2)
unlist(tm::findAssocs(sample.dtm1, 'install', 0.2))
——————————————————————————
#主题模型分析
Gibbs = LDA(sample.dtm1, k = 3, method = "Gibbs", control = list(seed = 2015, burnin = 1000, thin = 100, iter = 1000))
最有可能的主题文档 Topic1
表(主题1)
每个主题的前 10 个术语术语1
条款1
—————————————————————-- #使用vec方法进行分词
图书馆(tmcn)
图书馆(商标)
库(Rwordseg)
图书馆(wordcloud)
setwd("F:/数据和程序/第十五章/计算机实验")
data1=readLines("./data/meidi_jd_pos.txt", encoding = "UTF-8")
d.vec1
wc1=getWordFreq(unlist(d.vec1), onlyCN = TRUE)
wordcloud(wc1$Word, wc1$Freq, col=rainbow(length(wc1$Freq)), min.freq = 1000)
#
8.结果展示与说明
这是分析结果的一部分。可以看出,大部分客户的评价都带有正面情绪,说明客户对美的热水器比较满意。对于哪些方面满意,哪些方面不满意,哪些方面可以保持,哪些方面需要改进,这就需要我们的成果再一次展示。
点击可视化工具,获取词频云图。根据云图,我们可以看到客户最关心的点,也就是评论里说得比较多的点。从图中我们可以看到“安装”、“大师”、“配件”、“加热”、“快捷”、“便宜”、“速度”、“品牌”、“京东”、“送货”“服务”“价格”“加热”等。关键词 出现的比较频繁,我们大致可以猜到26
此外,值得注意的是,在云图中,还有一些“好”、“大”、“满意”等字眼。我们还不知道这些词背后的语义,这需要我们找到相应的注释。,提取这些词对应的话题点。然后添加优化分析的结果
正文 | @白加黑治感冒
来源 | PPV 课程
原来的:
R语言公众号是运营的公众号。数据人网络是数据人学习、交流和分享的平台。点击【阅读原文】进入【数据人脉】学习、分享、传播数据知识。
我们都是数据人,我们致力于从数据中学习,努力发现数据的洞察力,积极利用数据的价值!

