解决方案:自动采集网站内容-自动化网站建设流程图详解!
优采云 发布时间: 2022-09-30 17:38解决方案:自动采集网站内容-自动化网站建设流程图详解!
自动采集网站内容
一、通过原始站长api进行抓取访问网站,
二、通过原始站长api进行抓取流程图详解
1、手工单独下载图片地址
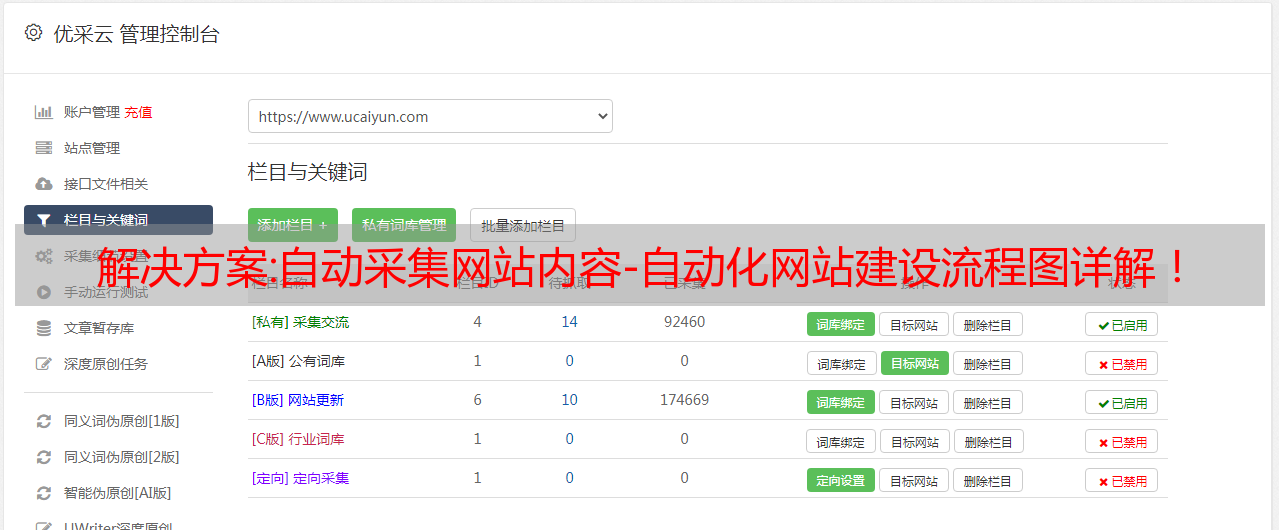
2、设置post地址、参数
3、推荐使用postman进行开发
4、不要过多于提交附件以上代码参考站长工具
给个建议,可以根据链接抓取内容,参考newbg的微博抓取,当然,
使用jsoup就可以的
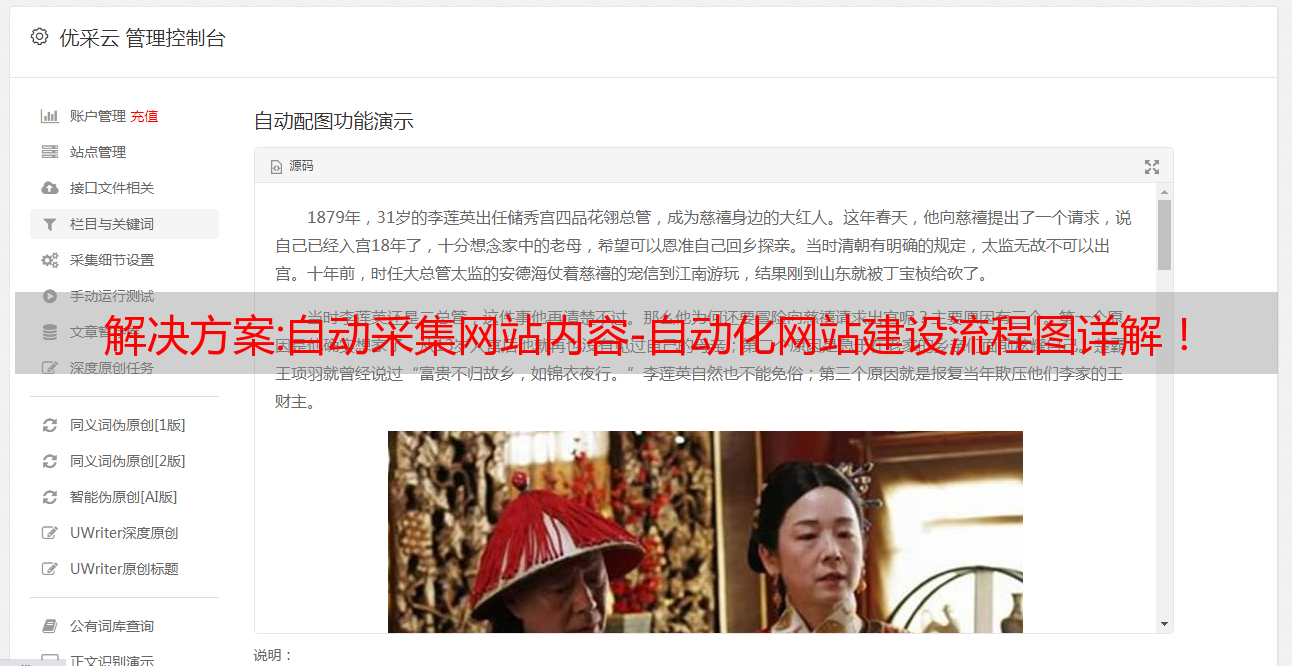
据老师说原始站长api-imageandwebstructures,
360的图片中心就可以抓取图片,如下图所示:
用了今号sq的接口,但是是抓原始图片。不知道能不能抓取包括网站目录以及之后跳转目录。另外还有一个就是,很多地方的图片都是有版权的。我目前的想法,就是抓取一个图片,查看某个链接上有哪些图片,然后看一下都有哪些图片是经过同一个编码。然后数据太麻烦了。从地址上就能看出来哪些是网站的,哪些是图片本身。
如果不加加密,抓取原始数据的违法问题。
这种工具叫做爬虫,只抓取网站数据,不接受参数,也不存储数据。好一点的爬虫工具会给每个页面配置一个客户端上传,以达到保存数据,存储数据,传播文件的目的。比如我写过的goldeneflect,用浏览器抓取网站数据,每个页面配置一个客户端上传实现数据存储,随时查看。可以看一下这个:阅读、输入访问不是本机实时抓取【goldeneflect-获取网站数据】。

