干货内容:SEO站外优化,我对外链的思路分享
优采云 发布时间: 2022-09-25 11:19干货内容:SEO站外优化,我对外链的思路分享
站内优化提高用户粘性、人气和权重。
检查和检查网站的稳定性,提高速度,然后加强引导蜘蛛的逻辑爬行,增强文章的内链。
比如你觉得网站速度可以再提一下,图片可以换两张更清晰更好看的。
修改修改你的文章里面的内容,改变模板按钮,网站里面的内容就是网站上的优化。
优质的原创内容是不可替代的,这是现场优化的基础。
目的是增加用户粘性、网站可见度和权重。
Ps:简单来说,现场优化就是改变网站的内部结构,让引擎蜘蛛快速爬取。
站外是发送外部链接——“反向链接”给蜘蛛一个渠道来抓取你的网站。
2.如何区分外链质量好坏?
1.什么是外部链接?
外部链接是在其他网站上插入你自己的网站链接。
入站链接是网站优化的一个非常重要的过程,入站链接的质量会影响我们在搜索引擎中的权重。 (所以不要引导任何乱七八糟的链条)
外部链接的作用可大可小,有好有坏。
不仅仅是为了增加网站的权重,一个真正优质的外链可以给你的网站带来非常大的精准流量。
我给你举个例子,或许你能很快理解什么是外链:
您写了一篇文章 文章 并将其发布在社交媒体上。朋友看了觉得写的不错,在下方评论“好文章”。
然后鲁迅先生也看到了你写的文章,觉得不错,于是在下方评论“好文章”。
你觉得谁更重?或者谁的外链更好?
那么当用户看到鲁迅的评论时,他们就会想看到你的文章——网站
总之,大家给你的评论(外链)越多,不管是你的朋友还是鲁迅先生,评论(外链)越多越好。
但我们最需要的是什么?像鲁迅先生一样是很重磅的评论(外链)
2.如何查询网站的权重?
通过上面的文章,你会明白什么是站外优化,什么是外链以及外链对网站的好处。
那么在做外链之前我们需要明白一点,那就是网站适合我们做外链吗?这些 网站 权重如何?
网站加权故事示例说明:
小王创建了一个博客网站,刚刚发了两个帖子文章。和他的网站和亚马逊官网相比,谁的权重更高?
毫无疑问,它一定是亚马逊。我们可以很快分辨出区别,因为我们了解这两个 网站 之间的区别。
那如何在不知情的情况下查询网站的权重?
我在这里为你推荐两个工具
首先推荐 - Ahrefs
基本上,SEO 营销专家一直在使用它。
如果您想深入了解网站,此工具适合您。
在主页面左上角,找到站点资源管理器,输入你要查询的网址,就可以看到域名级别了。
第二个推荐工具——MozBar(简称moz)
许多人称其为良好的 SEO 营销武器。它的主要功能是对关键词、网站SEO实力排名和分析。
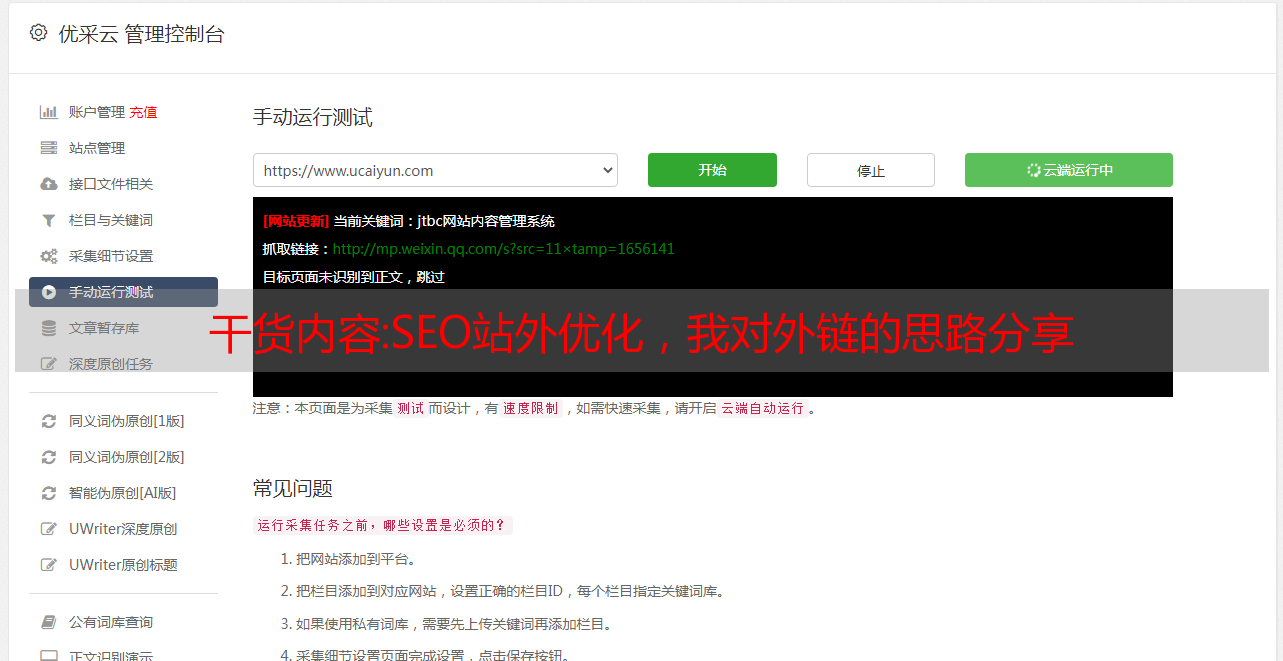
1.
DA(Domain Authority):DA的最大值为100,DA的值代表这个网站的权重。
2.
PA(Page Authority):最高的PA值也是100。根据MOZ的数据分析,判断网站在搜索引擎中的排名和链接数。
3.
那么当你遇到DA和PA值都很高,内容又比较接近的时候网站,你可能会有做外链的想法
那么请在这个时候继续阅读!注意SPAM值,如果超过5%就不需要再考虑了。 (除非内容非常相关)
4.
查看网站最近的网站文章流量的收录时间是为了验证网站是活跃的。
对于非活动网站,Google 不会每天抓取。
例如我搜索了 关键词:smart phone
根据网站配置文件下方的DA和PA值,可以判断出哪个网站的权重更高。
3.内容相关性
当用户使用搜索引擎进行搜索时,谷歌会通过用户输入的关键词推送关键词最相似的内容。
再举一个例子,你的 网站 是一个蓝牙耳机。
在其他3c电子产品上做外链是正常的网站,谷歌也允许。
那如果一个卖农产品的网站给你做个外链,谷歌发现后,肯定会减轻你网站的分量。
在避免这样的SEO黑帽雷区时,可以参考:
/znqRN76 黑帽SEO的雷区
以下是 Google 工程师的意见:
“不仅如此,还以 PR 为例,从高 PR 页面获取链接过去总是很有价值,今天更多的是网站主题与您的主题的相关性,相关性是新的 PR。”
p>
“不仅如此,以公关为例,从高公关页面获取链接过去总是有价值的,今天更多的是关于 网站 主题与您的相关性,相关性是新的公关。”
4.竞争对手有丰富的外链资源怎么办?
当你在做外链的时候,发现有很多来自竞争对手的外链,你会焦虑和嫉妒怎么办?
首先查看对方网站每个链接的域名总数,如果外部链接数与链接总域名的差值大于1:100。
对方的外链都是一些博客的评论网站,所以无论他的总外链多高,都没什么好怕的。
在排除对手黑帽的情况下,你追上的概率非常高。 (这样的新网站太多了)
下图为示例:
一个新网站,我的习惯是半个月看对手的流量。上次看的时候一直在上升的趋势,而且流量很稳定,非常好。
这次流量暴跌,估计是被谷歌惩罚了。
4.外部链接的几种形式
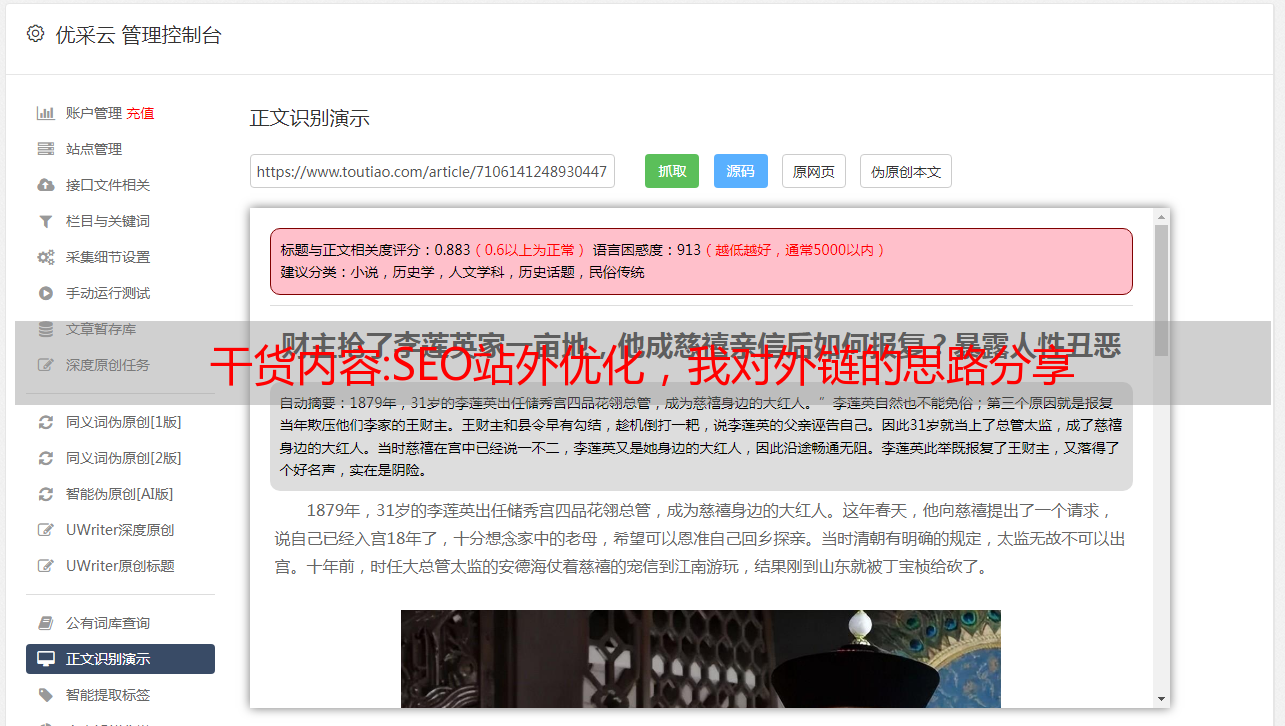
1.锚文本链接
锚文本是从一个网页到另一个网页的链接上的可点击文本。
就是把一个关键词做成一个链接,点击这个关键词可以到达另一个页面。
我在下图中用红色箭头标记的所有链接都是锚文本链接。
锚文本的优点:
你可以直接告诉搜索引擎他指向什么页面,最想表达什么。
关键词的排名、文章页面的收录、网站的权重都非常有帮助。
网站中合理的锚文本可以引导蜘蛛抓取更多的页面,展示我们对搜索引擎的友好。
同时,网站上的锚文本对于提供用户体验有很好的引导作用。
用户通常可以通过锚文本准确快速地找到他们需要的信息。如果没有这些锚文本,用户通常会关闭页面。
雷区:
在 网站 或 文章 中使用 关键词 作为锚文本是非常慎重的。
2.超链接表单
跳转到页面的超链接的形式与锚文本链接的形式不同。不需要指定跳转的页面,可以直接从一个页面指向目标页面。
如果网站的有效相关域有很多,说明这个网站广为流传,广为人知。
而且这种有效的相关域是可以点击的。如有需要,用户可直接点击进入网站。
像这样的有效相关域也是一种有效的反向链接形式。但在关键词的排名中,大多不如锚文本。
注意:超链接可以是图像、文档、电子邮件、应用程序。
3.纯文本链接
纯文本链接是本身,没有超链接,所以点击后不会跳转。
在优化影响和用户体验方面,所有超链接都无法比较。
优点是稳定性强。作为长期积累,与网站数量扩大时的优化成正比。
纯文本链接的构建成本非常低,而且很容易在很短的时间内实现多样化和扩展。
纯文本链接:
4.图片链接
点击图片跳转页面,对我们的跨境卖家来说,这是一个久经考验的技巧。
把网站链接到产品图片,上传产品图片,然后埋掉关键词。
通过搜索点击我们图片的用户关键词非常准确。
比如我搜索了关键词——James,下图中所有红框标注的都是图片链接:
获取图片网址(此方法适用于 Google)
1.点击图片进入网页,确保图片无链接。
2.在单击图像时右键单击并按住控件 (Ctrl)
3.会弹出一个选项菜单,选择“复制图片URL”
技巧干货:年轻人,不讲武德?Loki告警日志内容的骚方法_KubeGems的博客
很多朋友在使用洛基尺子配置日志报警规则时会有一个大胆的想法:
“如果你能把日志的内容报告出来就好了”
在LogQL V1时代,受限于简单的日志过滤解释器的影响,我们往往只能通过简单的聚合函数将日志转换为区间向量来进行警告,其规则大改如下:
p>
rules:
- alert: xxx告警
expr: sum(count_over_time({} |~ "xx关键字或者正则匹配字符串"[1m])) by (xxx) > 0
for: 0
labels:
service: xxx服务
annotations:
summary: "xxx服务出现xx错误{
{ $labels.value }}次"
可以看出,使用V1语法将日志转换为区间向量后,只保留了日志流中的原创标签,其中的信息量非常少。对于我们希望在收到日志警报时看到的关键信息是不够的。
有同学说,“那我为什么不把关键信息放在日志流的标签里呢?”
当然可以,但是考虑到两个成本,我相信你很快就会放弃这个想法。
1.日志采集端的逻辑太复杂了
直接在日志采集端提取日志的关键信息作为标签。虽然理论上是可行的,但是在不同的业务和实例中维护这套规则会带来大量的运维配置操作。与直接查询中心 Loki 实例相比,时间成本大于收益。
2. 太多的日志流标签会降低 Loki 的性能
稍微了解Loki的人应该都知道,Loki并不是索引日志内容,而是索引日志流,这样就可以通过日志流的标签快速查询到对应的日志内容。所以之前小白文章提到过《Loki Best Practices》的无界Label会造成高base,严重的话直接拖累集群。
那么有没有办法解决上面的矛盾呢?经过小白的测试,我们真的可以通过LogQL V2的语法来解决这个问题。
1.主要思想
LogQL v2 的主要更新点是将之前的 log-filter 替换为 log-pipeline。在日志管道中,我们可以使用 Parser Expression 将日志内容解析成标签进行聚合处理。其主要变化过程如下:
日志流 -> 日志解析器 > 日志流(包含新label)> 日志过滤器 > 聚合函数
目前的日志解释器支持三种格式处理:regexp、logfmt和json。接下来小白会对这三种格式的日志做一个简单的处理。
regexp - 正则解析
大部分情况下,我们的日志并没有特别格式化,就像下面这样的格式,这里我以kubelet杀死nginx容器失败的日志作为告警示例
日志格式
E1217 23:38:52.832192 142923 kubelet_pods.go:1093] Failed killing the pod "nginx: failed to "KillContainer" for "nginx" with KillContainerError: "rpc error: code = Unknown desc = operation timeout: context deadline exceede
警报规则
rules:
- alert: kubelet faild killing pod
expr: |
sum by (systemd,level,alert_time,method,message,pid)
(count_over_time(
{systemd="kubelet"}
|~ "Failed killing the pod"
| regexp "(?P\w)(?P\d{4}\s\d{2}:\d{2}:\d{2}.\d{6})\s+(?P\d+) (?P.*)] (?P.*)$"[1m]))
> 0
for: 0
labels:
severity: high
annotations:
summary: "服务: {
{ $labels.systemd }}
进程: {
{ $labels.pid }}
时间:{
{ $labels.alert_time }}
级别: {
{ $labels.level }}
方法:{
{ $labels.method }}
内容:{
{ $labels.message }}"
<p>
</p>
我们可以在grafana的Expolre中使用expr中的语句进行验证,如果能得到如下指标,说明语句正常
logfmt 格式
logfmt 格式的日志是结构化格式,可读性更好。 LogQL V2 的解释器可以直接提取 logfmt 的日志。下面我们以docker的日志为例。报错内容提示:
日志格式
time="2020-12-17T04:09:13.227200674+08:00" level=error msg="Handler for POST /containers/7912b27694555c0d6645011ad901d94425b032cd48fe3f2f3c9d0e631e1cee79/start returned error: OCI runtime create failed: container_linux.go:345: starting container process caused \"process_linux.go:303: getting the final child's pid from pipe caused \\"EOF\\"\": unknown"
警报规则
rules:
- alert: Docker OCI runtime exec faild
expr: |
sum by (time,level,systemd,msg)
(count_over_time(
{systemd="docker"}
| logfmt
| level = "error"
|~ "OCI" [1m]))
> 0
for: 0
labels:
severity: high
annotations:
summary: "服务: {
{ $labels.systemd }}
时间:{
{ $labels.time }}
级别: {
{ $labels.level }}
内容:{
{ $labels.msg }}"
我们也在探索中验证
json格式
json是一种轻量级的数据交换格式,虽然可读性不如logfmt,但好在它简单易解析,而且很多开源服务也使用这种格式。 LogQL 中 json 解释器的用法与 logfmt 相同。小白改造后,大家就明白了:
日志格式
{"time":"2020-12-17T04:09:13.227200674+08:00","level":"error","msg":"Handler for POST /containers/7912b27694555c0d6645011ad901d94425b032cd48fe3f2f3c9d0e631e1cee79/start returned error: OCI runtime create failed: container_linux.go:345: starting container process caused \"process_linux.go:303: getting the final child's pid from pipe caused \\"EOF\\"\": unknown"}
警报规则
rules:
- alert: Docker OCI runtime exec faild
expr: |
sum by (time,level,systemd,msg)
(count_over_time(
{systemd="docker"}
| json
| level = "error"
|~ "OCI" [1m]))
> 0
for: 0
labels:
severity: high
annotations:
summary: "服务: {
{ $labels.systemd }}
时间:{
{ $labels.time }}
级别: {
<p>
{ $labels.level }}
内容:{
{ $labels.msg }}"
</p>
2.启用 RulerRuler 配置
目前启用Loki的Ruler组件比较简单,只要引入以下相关配置,在Loki启动参数中加入-target=ruler即可。
ruler:
# 触发告警事件后的回调查询地址
# 如果用grafana的话就配置成grafana/explore
external_url:
# alertmanager地址
alertmanager_url:
enable_alertmanager_v2: true
# 启用loki rules API
enable_api: true
# 对rules分片,支持ruler多实例
enable_sharding: true
# ruler服务的一致性哈希环配置,用于支持多实例和分片
ring:
kvstore:
consul:
host: :8500
store: consul
# rules临时规则文件存储路径
rule_path: /tmp/rules
# rules规则存储
# 主要支持本地存储(local)和对象文件系统(azure, gcs, s3, swift)
storage:
type: local
local:
directory: /loki/rules
# rules规则加载时间
flush_period: 1m
想快速体验Ruler的同学可以在小白之前用docker-compose启动的loki-cluster-deploy部署demo
调整限制
由于我们使用聚合函数将日志转换成系列,Loki对于将日志内容提取到标签中是有默认长度限制的,我们需要在limits_config中进行合理的调整。
limits_config:
#label的name长度
max_label_name_length: | default = 1024]
#label的value长度,这里就是日志内容的最大长度
max_label_value_length: | default = 2048]
#label的name个数,如果解释器内容太多则需要调整此配置
max_label_names_per_series: | default = 30]
#最大查询series的个数,解释器提取的键值对对应一个唯一的series
max_query_series: | default = 500]
limits_config的合理调整会影响我们LogQL v2语句的查询结果。使用时请根据实际场景灵活调整
3.总结
LogQL v2 的语法给我们带来了很多棘手的操作,但目前还是单行处理日志。预计在发出警报时会一起打印该行的日志上下文。目前无法实现,我们只能根据报警的时间和内容,去Loki查询当时的日志场景。
关注“云原生小白”,进入Loki学习群

