归纳总结:SEO优化怎么找关键词?如何建立关键词库?
优采云 发布时间: 2022-09-24 14:15归纳总结:SEO优化怎么找关键词?如何建立关键词库?
什么是关键词同义词库?
因为我们在搜索引擎中的网站排名之一不仅仅是单词排名,会有很多单词,那么这些单词就形成了一个网站关键词词库!
如何找到关键词?如何挖矿关键词?
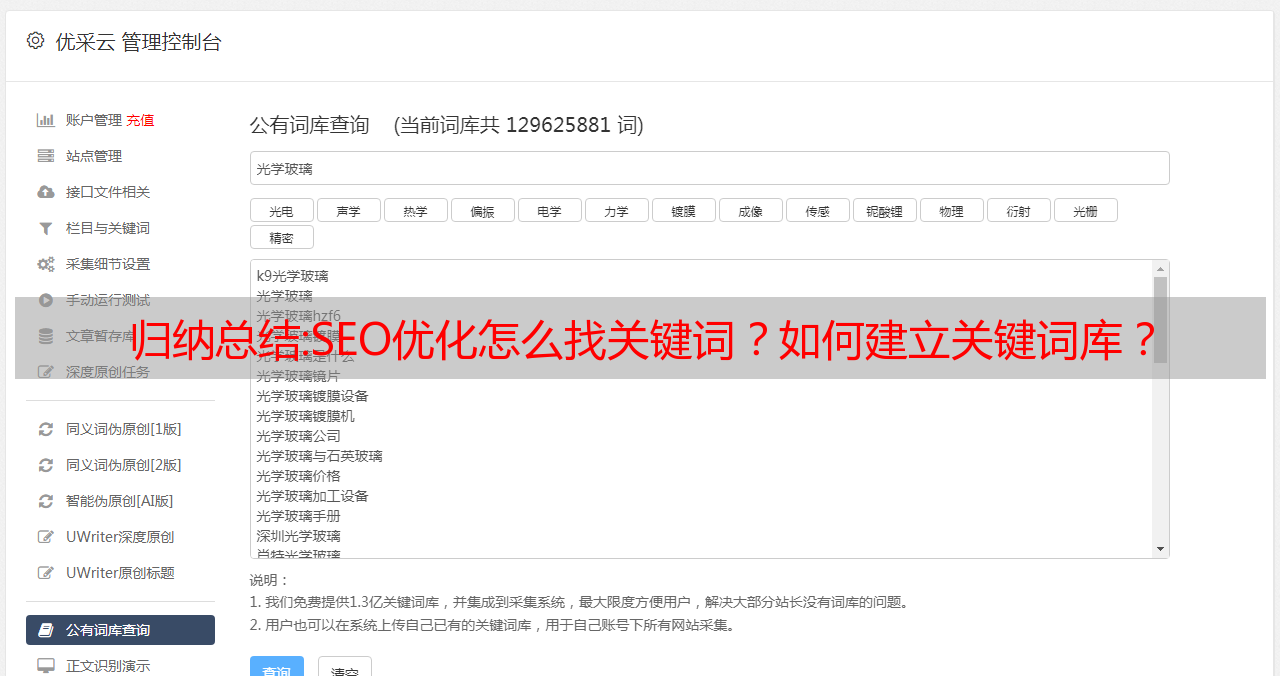
挖矿工具有很多关键词,比如5118关键词挖矿工具,爱站net关键词库,站长关键词挖矿工具,大神战争关键词工具、熊猫关键词挖矿工具等等!
今天以5118为例,教大家如何找到关键词并搭建一个关键词库(以“*敏*感*词*装修”为例)如图!
从上图可以看出,“*敏*感*词*装修”的关键词有15159条长尾关键词,在5118关键词挖矿工具中也显示了相关数据:收录@ > 成交量、竞标公司数量、流量指数、360指数、百度PC搜索量、百度移动搜索量、竞标竞争强度等,然后点击右上角“导出数据”即可(需要VIP会员) )!
根据下载的关键词表格,可以先细分大类,再细分小类,然后把相同的意思整理在一起,见下图:(图为会所装修效果图进一步细分的子类别关键词tables)
这里,我们对这些词进行排序后,就可以合理地关键词将它们布局到网站中(如首页、栏目页、聚合页、内容页)等
在文章的内容中,我简单介绍了网站关键词词库的概念以及如何使用关键词挖掘工具找到关键词,具体操作和表格的整理还有待自己的实践来实现!
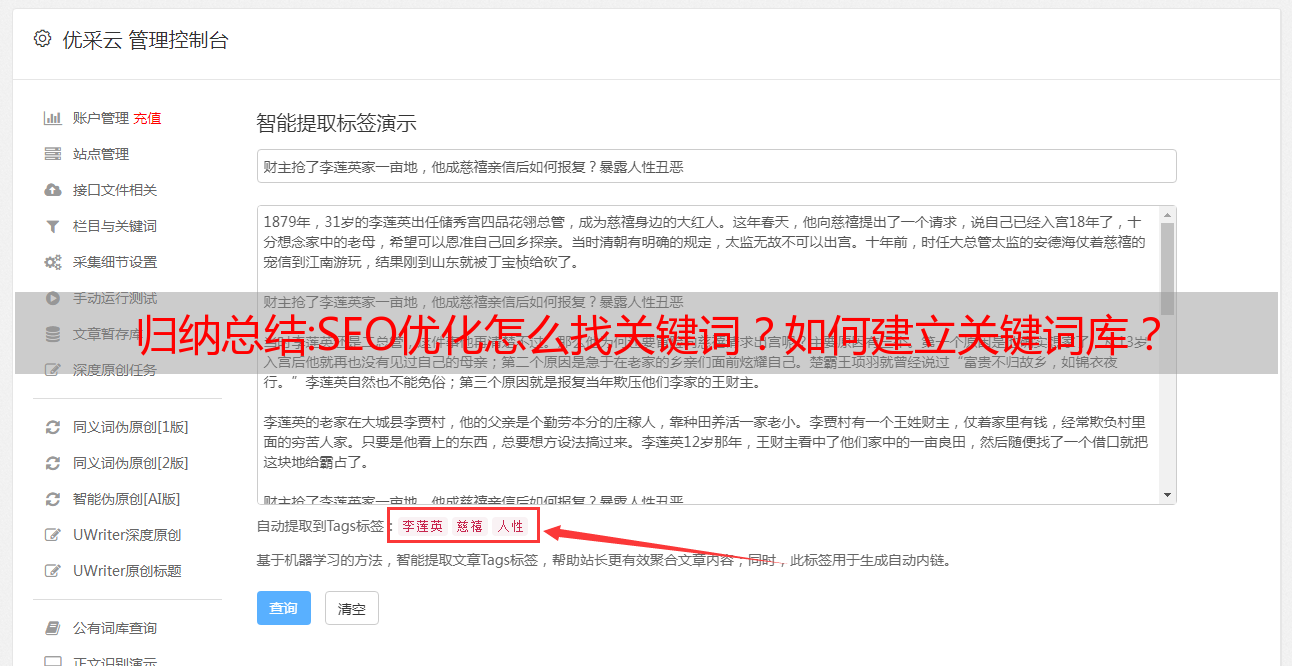
总结:结巴分词,如何基于TF-IDF算法提取文章关键词(标签)?
口吃分词主要用于分词。对于文章seo,一般需要设置关键词。从另一个角度来看,这个关键词也可以称为标签。那么,如何自动提取标签进行口吃分词呢?这就是这篇文章的内容。本文介绍基于TF-IDF算法关键词的提取方法。
口吃分词,如何基于TF-IDF算法提取文章关键词(tags)?(图2-1)
大家好,这里是苏南大叔的程序so smart博客,这篇文章介绍了如何提取标签(关键词)进行口吃分词,其实就是基于TF-IDF算法对分词结果进行加权。测试环境:win10、python@3.6.8、jieba@0.42.1。
口吃提取标签的原理
口吃分词自动提取标签的原理是将分词结果按权重排序,然后将权重较高的作为标签(关键词)。
所以,让我们先回顾一下口吃分词并添加自定义短语。
import jieba.posseg
sentence = "苏南大叔最近心情很好,所以满世界瞎溜达。"
jieba.add_word("苏南大叔",999,"nr")
words = jieba.posseg.lcut(sentence)
print(words)
运行的结果是:
[pair('苏南大叔', 'nr'), pair('最近', 'f'), pair('心情', 'n'), pair('很', 'd'), pair('好', 'a'), pair(',', 'x'), pair('所以', 'c'), pair('满', 'a'), pair('世界', 'n'), pair('瞎', 'v'), pair('溜达', 'v'), pair('。', 'x')]
最终的 关键词 是从这些列表中过滤出来的。
口吃分词,如何基于TF-IDF算法提取文章关键词(tags)?(图2-2)
口吃分词提取标签功能
keywords=jieba.analyse.extract_tags(sentence)
print(keywords)
这将列出所有可用的单词,按权重排序,显然这个结果是按停用词过滤的。
['苏南大叔', '溜达', '心情', '最近', '世界', '所以']
选择前几个标签
keywords=jieba.analyse.extract_tags(sentence, topK=3)
<p>
print(keywords)</p>
运行结果:
['苏南大叔', '溜达', '心情']
显示标签权重
keywords=jieba.analyse.extract_tags(sentence, withWeight=True)
print(keywords)
权重是相对的。对于同一个句子,参数不同时权重不同,并不是固定值。
[('苏南大叔', 1.9924612504833332), ('溜达', 1.7391569582), ('心情', 1.0581609061033335), ('最近', 0.9612306317916667), ('世界', 0.727921567595), ('所以', 0.7053377915566666)]
按词性过滤
keywords=jieba.analyse.extract_tags(sentence, allowPOS=("n","nr"))
print(keywords)
运行结果:
['苏南大叔', '心情', '世界']
在上面的例子中,n 代表一个名词,nr 代表一个人的名字。更多词性表示,请参考:
最完整的例子
keywords=jieba.analyse.extract_tags(sentence, topK=5, withWeight=True, allowPOS=())
print(keywords)
运行结果:
[('苏南大叔', 1.9924612504833332), ('溜达', 1.7391569582), ('心情', 1.0581609061033335), ('最近', 0.9612306317916667), ('世界', 0.727921567595)]
迭代加权结果
for w in keywords:
print(w[0],w[1])
或者
list = [ w[0]+str(w[1]) for w in keywords ]
print(list)
最有可能的 SEO 用途
seo的本次提取文章关键词的结果使用stuttering分词,句子可以设置成文章的内容。您可以设置 jieba.analysis.extract_tags 的“topK”和“allowPOS”参数以获得满意的结果。
keywords=jieba.analyse.extract_tags(sentence, topK=5, allowPOS=("n","nr"))
print(keywords)
运行结果:
['苏南大叔', '心情', '世界']
对于 SEO,此结果用于下面的标签中。
相关链接摘要
使用stuttering分词提取文章关键词操作,仅此而已。更多口吃分词文字请点击:
微信助手
微信奖励码
微信公众号
微信小程序
【源码】本文代码片段及相关软件,详情请点这里
【绝密】秘籍文章的入口,只传授给命中注定的人
蟒蛇解霸

