完整的解决方案:网页数据抓取系统解决方案
优采云 发布时间: 2022-09-24 06:06完整的解决方案:网页数据抓取系统解决方案
1.简介
项目背景
在互联网时代,信息像大海一样无边无际。甚至我们获取信息的方式也发生了变化:从传统的书籍和字典查找到搜索引擎检索。我们已经从信息匮乏的时代走到了信息极其丰富的今天。
今天困扰我们的问题不是信息太少,而是信息太多,太多让你分辨和选择。因此,提供一种能够自动抓取互联网上的数据,并自动对其进行排序和分析的工具非常重要。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息人工阅读自然友好,但计算机难以处理和重用。而且检索到的信息量太大,我们很难从大量的检索结果中提取出最需要的信息。
本方案所涉及的数据聚合系统就是由此而生。系统按照一定的规则对指定的网站中的信息进行采集,对采集的结果进行分析整理,并保存在结构化的数据库中,为数据的复用做准备。
中国人才网是知名的大型招聘类网站。为了全面详细地了解招聘市场的整体容量,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软和中华英才网市场信息资源。
2.方案设计原则
我们在设计系统方案时充分考虑以下两个原则,并始终贯穿于设计开发过程中:
系统的准确性
系统需要从互联网庞大的信息海洋中获取信息。如何保证其捕获的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理分析外,当目标网站的内容和格式发生变化时,能够智能感知,及时上报和调整也是保证准确性的重要手段系统的。
系统的灵活性
虽然该系统是为少数用户提供服务并监控固定站点的内部系统,但仍需要具有一定的灵活性和较强的可扩展性。
因为目标网站的结构、层次和格式是不断变化的;并且系统需要爬取的目标站点也在不断调整;因此,系统必须能够适应这种变化,当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决办法:
1.功能*敏*感*词*
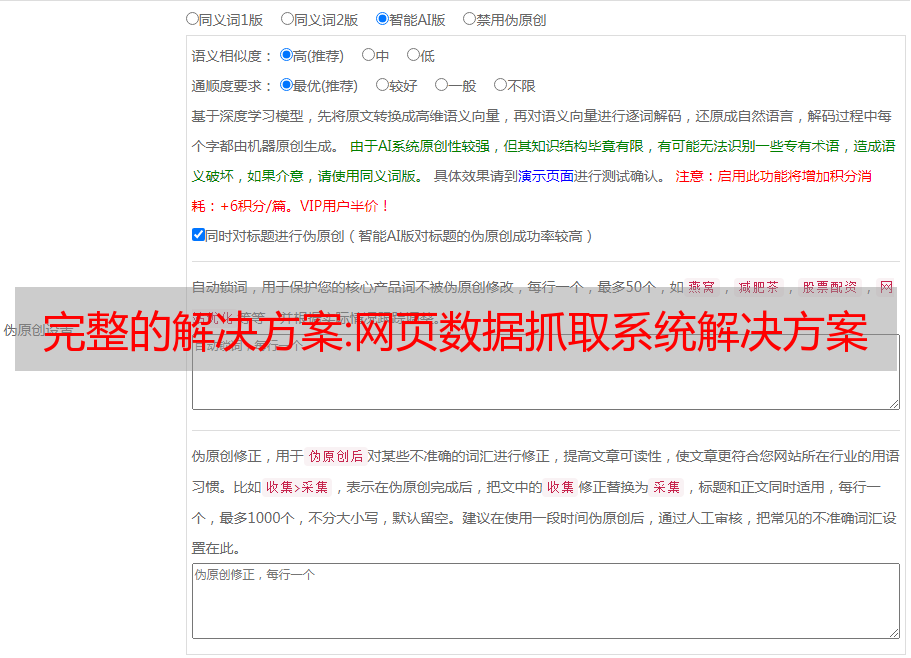
2.定义格式,制作脚本
首先,我们需要根据要抓取的目标网站的特性,编写一个抓取的脚本(格式)。包括:
目标的URL路径网站;
如何获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数,模拟提交);也可以从头到尾遍历序号(需要找到当前最大的序号值);
为每个 网站 功能编译(标准、脚本);
3.捕获数据
系统提供的rake程序会按照预先定义好的XML格式执行数据采集任务。为了防止目标网站的检测程序发现,我们建议直接保存捕获的页面,然后进行处理。而不是一拿到信息就处理,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,使用循环遍历列表中的每个值。用查询结果模拟页面上的翻页操作,获取其所有查询结果;
如果作业数据库或业务目录数据库使用一个自增的整数作为其唯一ID,那么我们可以想办法获取最大值,然后通过遍历的方式全部抓取;
定期进行爬取操作,增量保存抓取到的数据;
4.简单分析
在外网的服务器上,对采集收到的数据进行简单的分析处理。内容主要包括:
结构化数据:结构化获取的数据可以方便未来的数据传输,以及下一步的去重、故障排除和检查任务。
排除重复;使用模拟查询的方式进行遍历时,系统抓取到的数据肯定会出现重复。重复数据会造成重复的分析处理过程,不仅占用系统资源,降低系统处理效率,还会给系统带来大量垃圾数据。为了避免出现大量重复和冗余的数据,我们首先要做的处理工作就是去重。
排除错误;由于目标站点的内容、结构和格式的调整,系统将无法抓取,或抓取大量错误信息。可以获取目标站点是否发生变化的信息,及时向系统发出预警通知。
5.数据返回内部
系统将处理后的数据通过Web Service发送回企业。唯一需要考虑的是如何实现增量更新,否则每天都会有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析和上面描述的在远程服务器上进行的分析操作是不一样的。后者是对数据进行简单有效的过滤,防止数据冗余导致处理速度过慢。或者网络拥塞等问题;前者是为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l按地区划分;
l根据准确程度分类;帮助用户优先考虑哪些信息更有效;
l除以发布的职位数量;
l记录各企业发布职位的变化过程;
7.手动确认
本节重点介绍两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、与英财网的仓位数据库对比,提取差异进行人工确认:
通过与市场人员的沟通和沟通,了解他们关心的信息,按照他们期望的方式提供数据,完*敏*感*词*工确认工作。
8.统计汇总
汇总统计功能也是数据聚合系统的重要组成部分,它将提供以下几种统计汇总功能:
以网站为单位,统计每网站日新增公司、职位等信息;
跟踪大型企业,统计每个网站的发帖记录;
以时间为单位,按日、周、月对各种信息进行统计汇总;
按地区、公司、职位统计汇总;
其他;
模拟统计汇总界面
【引用】
解决方法:这些网络爬虫能有效地跟踪页面之间的链接,以查找要添加到索引中
什么是搜索引擎优化?SEO(搜索引擎优化)是通过有机搜索结果增加网站流量的实践它涉及到关键词研究、内容创建、链接构建和技术诊断等内容,然后再开始学习SEO,让我们先了解一下如何搜索引擎工作。搜索引擎使用称为蜘蛛的爬虫程序进行爬取。
这些网络爬虫有效地跟踪页面之间的链接以查找要添加到索引的新内容。使用搜索引擎时,会从索引中提取相关结果并使用算法进行排名。
如果这听起来很复杂,那是因为它很复杂。但是如果你想在搜索引擎中排名更高以获得更多的流量到你的网站,你需要了解搜索引擎是如何查找、索引、排名的,对原理有一个基本的了解在介绍技术之前,首先要确保我们了解搜索引擎的真正含义、它们存在的原因以及它的重要性。
什么是搜索引擎?搜索引擎是一种用于查找和排名与用户搜索匹配的 Web 内容的工具。每个搜索引擎都由两个主要部分组成:一个搜索网页信息的数字图书馆。匹配搜索并对其进行排名的搜索算法。热门搜索引擎有谷歌、必应,还有百度、搜狗、360等。
搜索引擎的目的是什么?每个搜索引擎都旨在为用户提供最好、最相关的结果,至少在理论上,这是他们获得或保持市场份额的方式 搜索引擎如何赚钱?搜索引擎有两种类型的搜索结果: 自然排名结果 您不能为付费排名结果付费。
您可以付费获得它 为什么您应该关心搜索引擎的工作方式?
了解搜索引擎如何查找内容、索引、排名可以帮助您更好地优化和排名是蜘蛛(例如百度蜘蛛)找到的页面被访问和下载的地方。
需要注意的是,Baiduspider 并不总是按照页面被发现的顺序抓取页面。百度蜘蛛根据以下因素对要抓取的 URL 进行排名: URL 的 PageRank URL 更改的频率。
这是新的吗?这很重要,因为这意味着搜索引擎可能会先于其他页面抓取和索引某些页面。如果你的网站很大,搜索引擎可能需要一段时间才能完全爬取。百度蜘蛛在处理过程中会从爬取的页面中提取关键信息。
搜索引擎之外没有人知道这个过程的细节,但我们认为重要的部分是提取链接以及存储和索引内容。搜索引擎必须渲染页面才能完全处理它,搜索引擎运行页面的代码来了解外观如何影响用户。
索引 索引是将已爬网页面中的信息添加到称为搜索索引的大型数据库中。本质上,这是一个收录数万亿网页的数字图书馆,搜索引擎的搜索结果来自于这些网页。这一点很重要,当您在搜索引擎中搜索时,您并不是直接匹配 Internet 上的结果。
相反,它在搜索引擎中匹配。如果页面不在搜索索引中,搜索引擎用户将找不到它。这就是为什么让您的 网站 在 Google 和百度发现等主要搜索引擎中被索引如此重要的原因,抓取和索引内容只是该过程的第一部分。搜索引擎还需要一种方法来匹配用户执行搜索时的结果排名。
这就是搜索引擎算法有用的地方。每个搜索引擎都有独特的网页排名算法。然而,由于搜索引擎是迄今为止在国内使用最广泛的引擎,在本指南的其余部分,我们将重点介绍引擎搜索引擎有 200 多个排名因素,没有人知道所有这些排名因素,但关键因素是已知的。
让我们讨论其中的一些:链接相关性新鲜度主题权威页面速度移动友好
主题测试文章,仅供测试使用。发布者:147采集,转载请注明出处:

