教程:帝国cms仿站详细过程,帝国cms如何做网站?
优采云 发布时间: 2022-09-24 00:19教程:帝国cms仿站详细过程,帝国cms如何做网站?
Empirecms是很多站长建站的首选。那么今天晨阳seo仿站就来给大家介绍一下帝国cms仿站的详细流程,帝国cms是怎么做网站的?
1.目标网站分析
分析目标网站,哪些页面应该被模仿,哪些页面共用一个模板,哪些页面布局是什么,哪些页面是公共部分,这些都要有印象。
2.仿站工具的准备
我们通常在上线前在本地调试网站。这需要下载本地服务器环境。这里我们推荐phpstudy。这个界面简单易用。
二是下载仿网站小部件,方便我们下载目标网站的静态代码和css、js等文件。
最后一个是代码编辑工具,方便模板创建和代码修改。这里推荐使用 Notepad++。
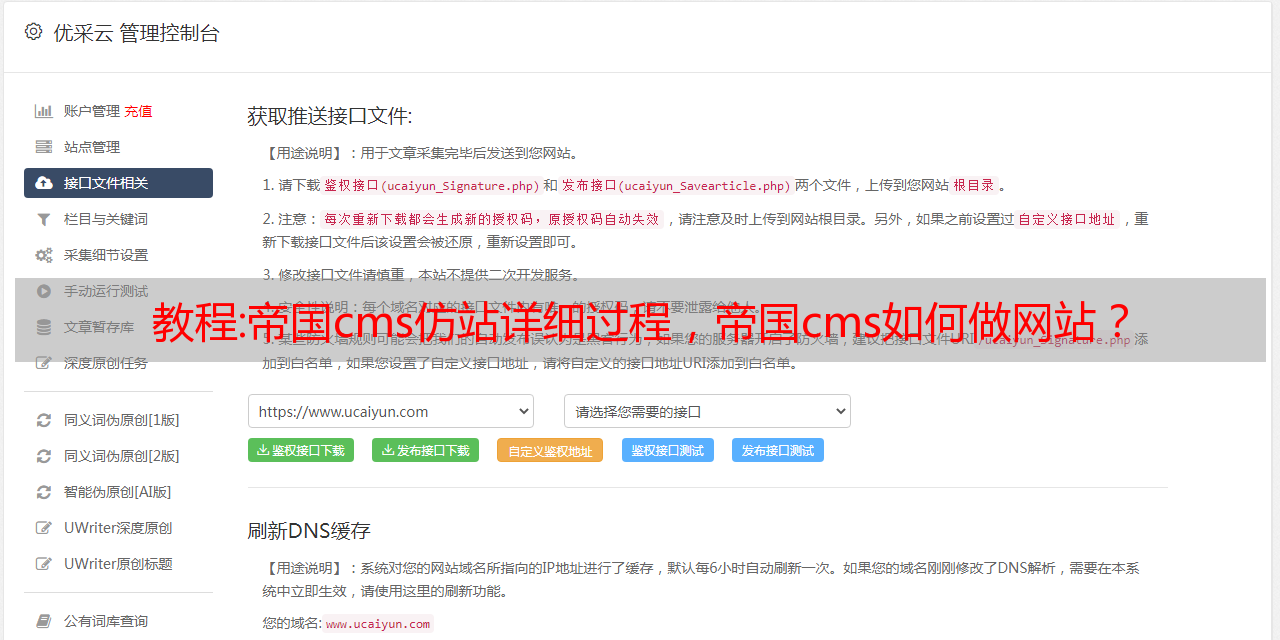
3.目标网站源码下载
使用仿站小部件下载目标网站的代码文件。
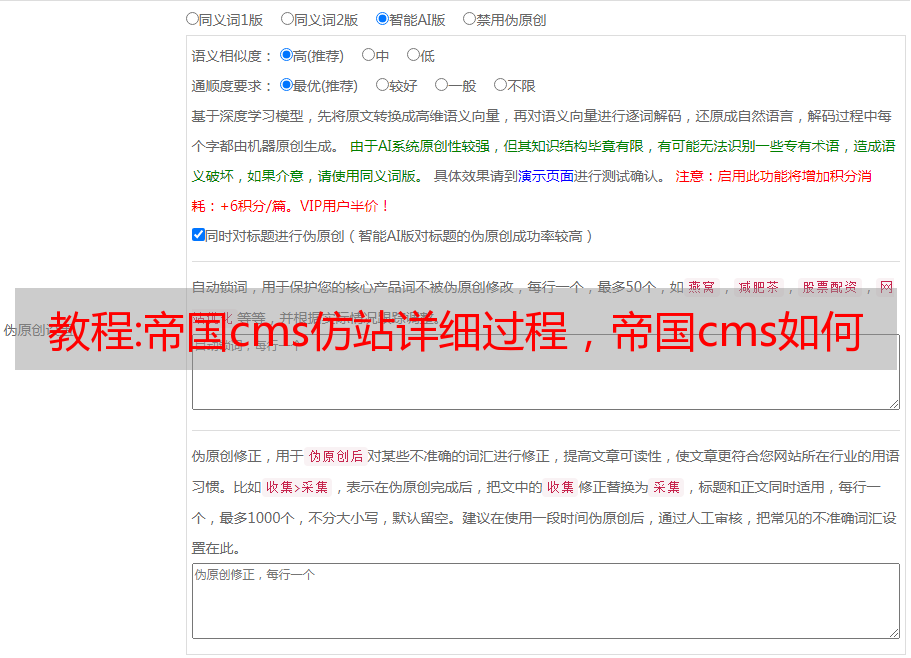
4.模板制作
phpstudy配置好后,去Empire官网下载Empirecms7.5安装包,记得下载utf-8版本。然后将安装包放到本地服务器根目录下,在浏览器输入域名/e/install,按照提示安装Empirecms程序。
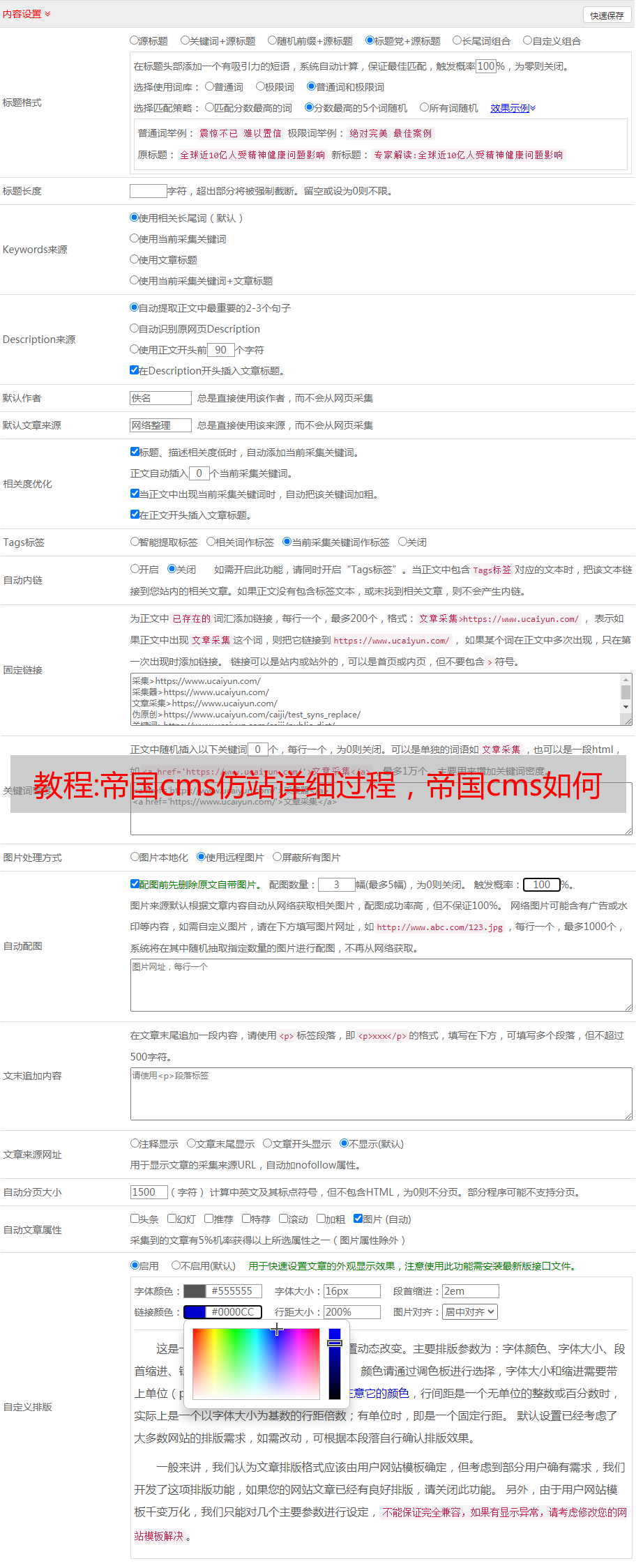
您可以在安装后创建模板。对于简单的文章信息类网站,只需要创建三个模板,分别是首页模板、列表页模板、内容页模板。
然后将public部分分开,使用Empire支持的标签动态调用代码cms。
5.网站包装
网站数据库备份后,网站代码压缩后即可上传到服务器并上线。
以上是模仿帝国的过程cms。当然,里面有很多细节,篇幅有限,所以没有说太多细节。如果还不清楚,记得模仿晨阳seo站留言。
教程:python+selenium+PhantomJS抓取网页动态加载内容
环境建设
准备工具:pyton3.5、selenium、phantomjs
我的电脑已经安装了python3.5
安装硒
pip3 安装硒
安装 Phantomjs
根据系统环境下载phantomjs。下载完成后,将phantomjs.exe解压到python的脚本文件夹中
使用 selenium+phantomjs 的简单爬虫
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com') #加载网页
data = driver.page_source #获取网页文本
driver.save_screenshot('1.png') #截图保存
print(data)
driver.quit()
selenium+phantomjs的一些使用方法
在请求头中设置 user-Agent
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
dcap = dict(DesiredCapabilities.PHANTOMJS) #设置useragent
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0 ') #根据需要设置具体的浏览器信息
driver = webdriver.PhantomJS(desired_capabilities=dcap) #封装浏览器信息
driver.get('http://www.baidu.com') #加载网页
<p>
data = driver.page_source #获取网页文本
driver.save_screenshot('1.png') #截图保存
print(data)
driver.quit()</p>
请求超时设置
webdriver类中有三个与时间相关的方法:
1.pageLoadTimeout 设置整页加载的超时时间。完全加载意味着完全渲染,同步和异步脚本都被执行。
2.setScriptTimeout 设置异步脚本的超时时间
3.implicitlyWait 智能等待时间识别对象
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.set_page_load_timeout(5) #设置超时时间
driver.get('http://www.baidu.com')
print(driver.title)
driver.quit()
设置浏览器窗口大小
调用启动的浏览器不是全屏的,有时候会影响我们的一些操作,所以我们可以设置全屏
driver.maximize_window() #设置全屏
driver.set_window_size('480','800') #设置浏览器宽度为480,高度为800
元素定位
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.set_page_load_timeout(5)
driver.get('http://www.baidu.com')
try:
driver.get('http://www.baidu.com')
<p>
driver.find_element_by_id('kw') # 通过ID定位
driver.find_element_by_class_name('s_ipt') # 通过class属性定位
driver.find_element_by_name('wd') # 通过标签name属性定位
driver.find_element_by_tag_name('input') # 通过标签属性定位
driver.find_element_by_css_selector('#kw') # 通过css方式定位
driver.find_element_by_xpath("//input[@id='kw']") # 通过xpath方式定位
driver.find_element_by_link_text("贴吧") # 通过xpath方式定位
print(driver.find_element_by_id('kw').tag_name ) # 获取标签的类型
except Exception as e:
print(e)
driver.quit()
</p>
向前或向后移动浏览器
from selenium import webdriver
driver = webdriver.PhantomJS()
try:
driver.get('http://www.baidu.com') #访问百度首页
driver.save_screenshot('1.png')
driver.get('http://www.sina.com.cn') #访问新浪首页
driver.save_screenshot('2.png')
driver.back() #回退到百度首页
driver.save_screenshot('3.png')
driver.forward() #前进到新浪首页
driver.save_screenshot('4.png')
except Exception as e:
print(e)
driver.quit()
至此,这篇关于python+selenium+PhantomJS爬取网页动态加载内容的文章文章就介绍到这里了。更多相关python PhantomJS爬取内容请搜索之前的文章或继续浏览下方文章希望大家以后多多支持!

