最新版:集搜客网页抓取软件了解一下,downloadcapture安装包
优采云 发布时间: 2022-09-23 17:08最新版:集搜客网页抓取软件了解一下,downloadcapture安装包
集搜客网页抓取软件了解一下,downloadcapture安装包,对于初学者非常的友好。python3.6,功能强大,
根据我多年在网站抓取的经验来说,通过百度或者360搜索的抓取方式以及站长平台的优化,满足80%以上的网站都可以搜索到,另外20%网站则在搜索引擎没有收录网页,根据你网站制作的难易程度来决定,最后剩下没有收录的网站你可以找一些猪八戒、淘宝等中介,问他们买买关键词,
可以在phpmyadmin集搜客中的web抓取插件进行抓取。
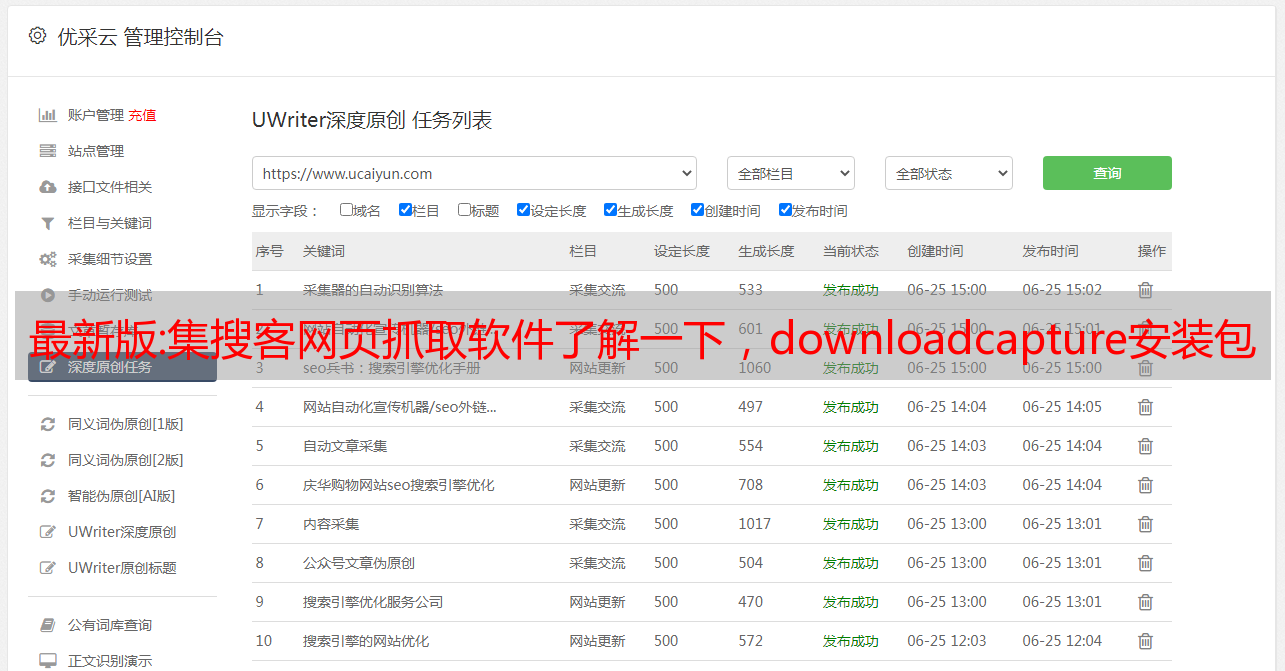
这里简单讲一下,一般网站上一般所有的页面都有,你可以抓取的,再用xxx的抓取代理工具抓取。我之前也试过,效果非常好,几乎可以满足站长的需求。
阿里巴巴商家信息采集器
这两年帮我做过的网站有:淘宝网::
做淘宝的话就用cnzz数据采集器很简单~
如果能抓取,你也知道该如何抓取。大致判断是否能抓取,还是靠一些排名。你有f5的话可以试试。
看看
恩,也不一定需要什么技术,一台电脑就可以做了。原理其实很简单,浏览器每打开网页一次,就会有一个相应的页面库存在硬盘里面。有了页面库之后,一键就可以获取网页数据,想拿什么数据都是可以的。下面给大家总结一下这方面的内容。1.从外网抓取首先登录facebook/twitter/google这些平台,这些平台在你使用浏览器或者浏览器app在本地安装数据采集工具,它们会被动启动一个服务,收集该平台内的每一个网页的html内容,然后再转发给采集机器。
我们需要的抓取工具就是打开浏览器的浏览器插件h5viewer2.从浏览器抓取第二种方法,也是一般网站使用的方法,当你每次打开浏览器,只要关掉网页,也不管是否正在打开下面的网页都是一样的抓取!要点是,别人打开一个新的网页,你要是能够抓取得话,你就要立刻抓取,这样才能把这个当做不正常的网页来对待!3.从html源码抓取随着各种浏览器对于html源码的抓取越来越完善和方便,我们大部分情况下不需要的*敏*感*词*抓取可以用浏览器下载html源码,然后利用网页截取工具截取下来就可以了。
html源码抓取工具screryee-h5/routerli.js源码是从facebook/twitter等网站抓取出来的,按照自己的需求加载出来。一键抓取facebook,youtube,instagram等页面,做爬虫一站式解决!。

