技巧干货:C# 爬虫 、 网页数据抓取 随记[通俗易懂]
优采云 发布时间: 2022-09-23 02:07技巧干货:C# 爬虫 、 网页数据抓取 随记[通俗易懂]
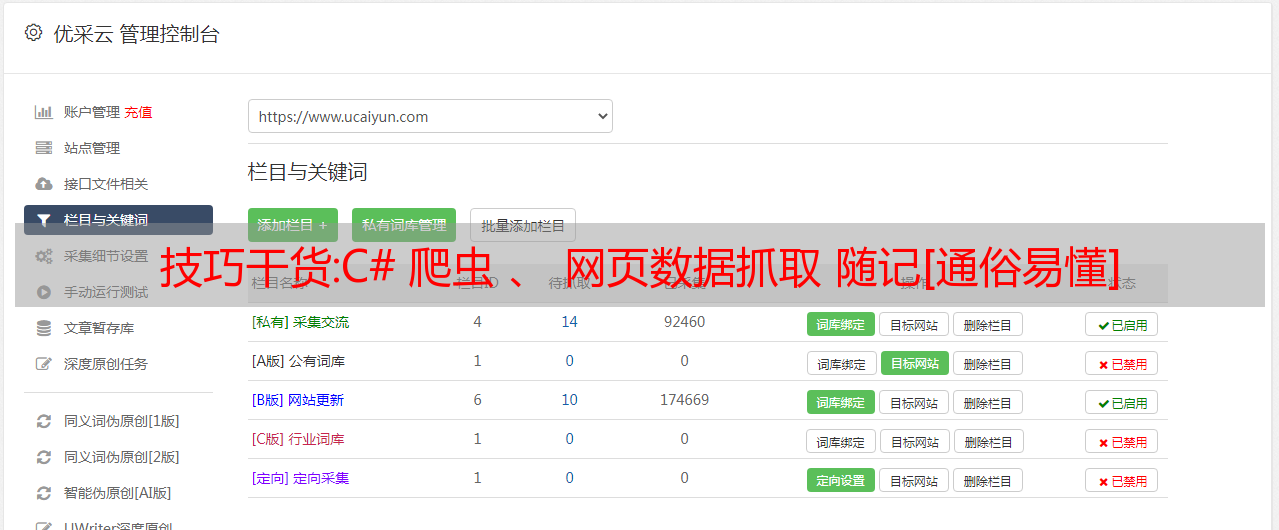
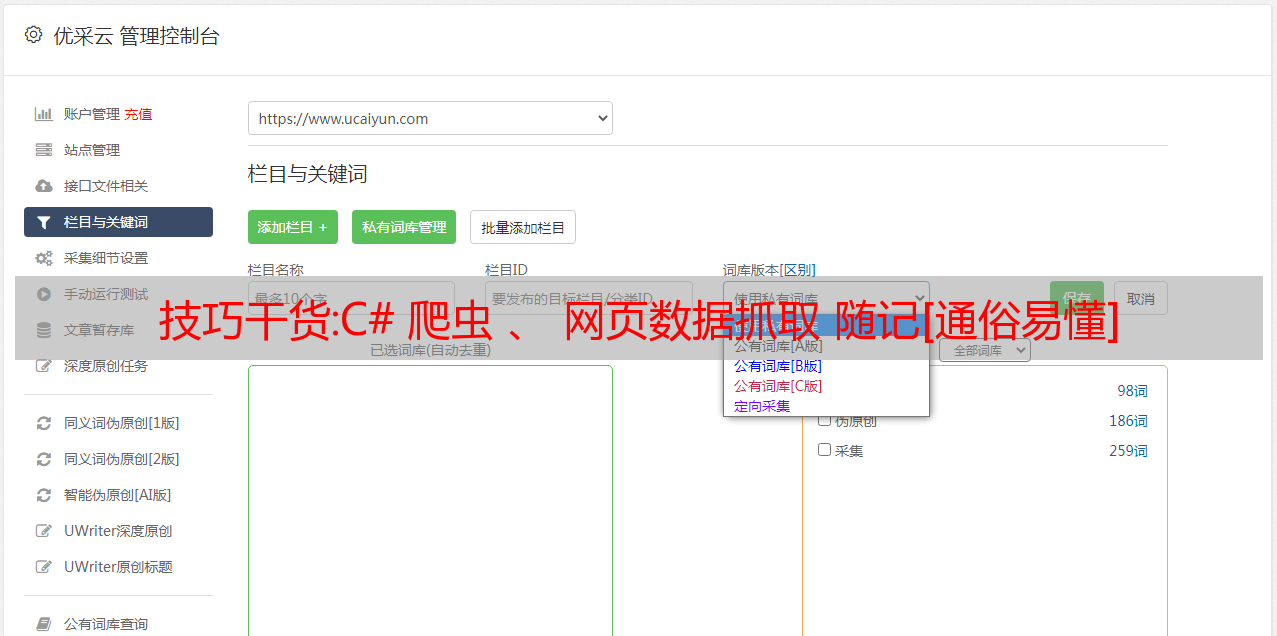
C#爬虫,网页数据抓取笔记【通俗易懂】第一次写数据抓取,
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说C#爬虫,网页数据抓取笔记【通俗易懂】,希望可以帮助大家进步!!!
第一次用C#写数据采集,遇到各种问题。开始写模拟登录的时候,发现有验证码。我必须突破验证码才能得到它。嗯,那我去找验证码激活成功教程的代码。我尝试了很多代码,发现它们并不通用。后来,我明白了其中的原理。首先去除噪点、干扰线等,然后将彩色验证码转换成黑白。字体切割,如果字体是粘的,对于我们初学者(外行)来说,那就放弃吧。裁剪后,每个像素都编码,白0,黑1,好像是这样的,不是太懂,然后读取字体库模型中的文字进行对比。如果达到百分比或更多,它会识别验证码是什么,一一比较,最终形成一个完整的验证码。折腾了一天,发现自己既无法完成验证码激活成功教程,也放弃了激活成功教程,另谋出路。
网上说验证码可能会保存在cookie中。嗯,抱着试试的态度去吧,模拟浏览器发送数据,请求验证码,FF调试,发现cookie中有验证码。就这样,验证码到此结束,我们重新登录。
要登录,首先跟踪目标页面的逻辑,看看它是如何传递参数成功登录的。我只是先发送一个请求对用户名和密码进行加密,然后将加密后的发送到后台进行登录。这没什么好说的。这期间遇到的问题是发送请求,半天不成功。原因是当时发送了一个ajax请求,需要设置调用哪个方法。网站 一般直接要求后台,而不是发出ajax请求,所以这里又是一团糟。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
只听到建筑师办公室传来建筑师的声音:
将你的身体投掷给主,并像全国哀悼一样死去。谁将向上或向下匹配?
登录成功后,就到了抓取页面的时间了。首先获取抓取页面的html,然后分析它如何提交数据,如何返回,传递了什么参数等等。爬取页面没有问题,然后是模拟查询数据,那个网站写的,隐藏字段控件很多,所以发送请求的时候参数很多,不知道它是干什么用的,反正我觉得只查询订单号是有用的。模拟发送很长时间后,报500错误。这是因为模拟参数有问题,服务器无法读取。我已经完成了所有设置。我发现它没有任何问题。2天后,它卡在这里。没有办法。之后,无意中发现提交的数据和页面隐藏字段的数据有点不一样。输入特殊字符。转码后想了想之前写的代码传输参数,发现传输数据的时候,都需要通过UrlEncode转码,然后传输。虽然隐藏字段的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说就开始转码参数了
此代码由Java架构师必看网-架构君整理
HttpUtility.UrlEncode(string);
居然成功了,太烧脑了,虽然对于一些老手来说,这些可能不知道,但第一次接触还是很难写。
对了,还有一个问题,就是读取html后获取字符串html中的参数的问题,当然在页面上很容易获取,但是现在都是一堆字符串,这真的很难,所以我找到了一个非常好用的dll,支持xpath,和xmlDocument一样的用法,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
<p>
var tempId = htmlNode.Attributes["id"].Value;
}</p>
红色部分是xpath规则,
也可以根据属性获取对应的节点:
此代码由Java架构师必看网-架构君整理
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是: HtmlAgilityPack 下载地址:
点击打开链接
最好阅读此 网站 评论。里面有很多人的问题,说不定能帮上忙。
好了,写了这么多,接下来我整理一下代码发上来,然后开始循环爬取数据。
我想你会喜欢:
详细数据:近7年上海天气数据抓取和分析(含代码)--爬虫部分
上一个文章系列讲了python的基础,下一个讲可视化。对于可视化,Python和R语言,我还是很喜欢用R语言的,因为用她做图简洁高效。今天分享一个使用R语言抓取上海近7年天气数据的案例。
我们先来看看我们需要抓取的网站内容,如图:
红框是我们需要采集的上海天气信息,包括日期、最高气温、最低气温、天气、风向和风向。这些内容可以在网页源代码中查询。您可以按键盘上的 F12 快捷键。我以自己的Chrome浏览器为例,可以返回下图所示的信息:
点击红框内的按钮,然后返回左侧或上方的原网页,点击任意日期值或其他指标值,立即返回下图所示内容:
发现没有,网页中8.1天的天气数据都收录在ul标签中,而这个标签的父标签就是红框中的div标签。只要锁定这两个标签,就可以快速抓取网页中的天气数据。
从源码知道了如何查询网页数据所在的标签,那么只需要使用R语言的rvest包就可以轻松抓取数据了。关于这个包,我只介绍以下三个重要的功能:
下面以2017年8月的上海天气链接为例,讲解一下上述三个功能的应用原理:
网址
# 发送请求并获取源代码
图书馆(rvest)
页
# 查看请求结果
页$响应
# 根据标签抓取目标数据
信息')
信息
看,除了第一行是原创网页中的标题,第二行是我们需要的数据。接下来,使用 html_text 函数去除 ul 等标签。
# 取消标记
内容
内容
红框内的内容为去掉标签后的目标数据,非红框内的\t\n\r代表空白。接下来,我们使用这些空白作为分隔符来清理数据。
库(字符串)
# 通过正则表达式 \\s,使用空格作为分隔符
细胞
细胞
你会发现每个日期对应的天气数据在列表元素中的位置相同,所以可以通过索引获取指定的值。你可能会问,把这些空字符串删掉,剩下的不就是需要的数据了吗?其实我试过了,但是有错误,原因是某些日期的索引值缺失。如果,8月1日,最高温度缺失35度,此时第二个值和剩余的值会前移一个位置,最终会导致采集到的数据错位。
# 获取日期
日期
# 获取最高温度
高的
# 获取最低温度
低的
# 获取天气
天气
# 获取风向
方向
# 得到风
力量
# 将数据合并到数据框中
df
头(df)
是不是很简单,这样就可以爬取2017年8月的网页数据了。如果需要爬取更多的历史数据,只需要更改爬取的URL链接即可。对比不同月份的网址,发现链接中的日期在变化,其他部分没有变化。因此,我们可以循环生成这些常规 URL。
# 生成爬取的链接
细绳
网址
对于(2011 年:2017){
对于(1:1 中的月份2){
如果(月
urls = c(urls,paste0(string,year,0,month,'.html'))
} 别的{
urls = c(urls,paste0(string,year,month,'.html'))
}
}
}
接下来,只需在循环中抓取上面生成的链接。
# 从上述每个链接中获取天气信息
tot_info
对于(网址中的网址){
# 发送请求并下载网页源代码
页面 = html_session(url)
# 根据源码标签获取数据
info = html_nodes(page, 'div.tqtongji2 > ul') %>% html_text()
# 数据清理 -- 删除所有空格
info = sapply(info, str_split, '\\s', USE.NAMES = FALSE)[-1]
# 获取日期
日期 = sapply(信息,'[',1)
# 获取最高温度
高 = sapply(信息,'[',15)
# 获取最低温度
低 = sapply(信息,'[',23)
# 获取天气
天气 = sapply(info,'[',31)
# 获取风向
方向 = sapply(info,'[',39)
# 得到风
force = sapply(info,'[',47)
# 构建数据框
df = data.frame(日期、高、低、天气、方向、力)
# 数据合并
tot_info = rbind(df, tot_info)
}
# 观察数据集的前6行
头(tot_info)
很快,我们就捕捉到了上海过去7年的天气数据,包括总共2422天的数据。接下来就可以按照上面的步骤,使用R语言来实现数据抓取了。
下一期,我们将继续利用这个数据,通过ggplot2包对数据进行可视化,完成对数据的探索性分析。我们期待您的加入和学习。
每天进步一点点 2015

