整套解决方案:自动实时抓取网页数据-定时网页数据采集定时网页发布免软件
优采云 发布时间: 2022-09-22 23:13整套解决方案:自动实时抓取网页数据-定时网页数据采集定时网页发布免软件
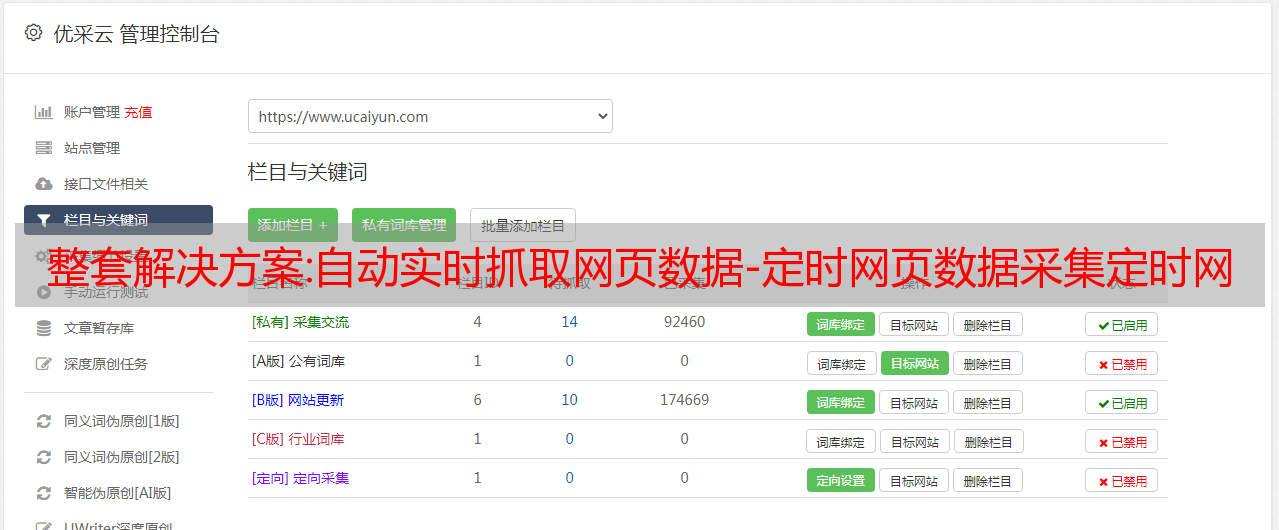
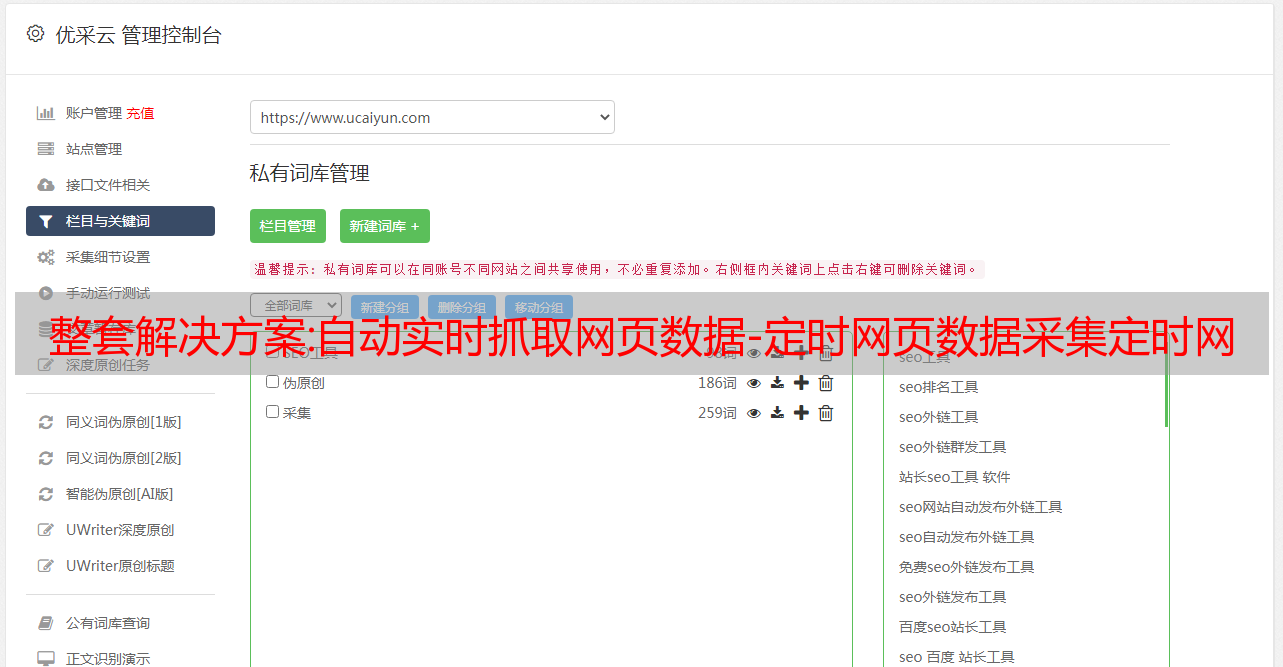
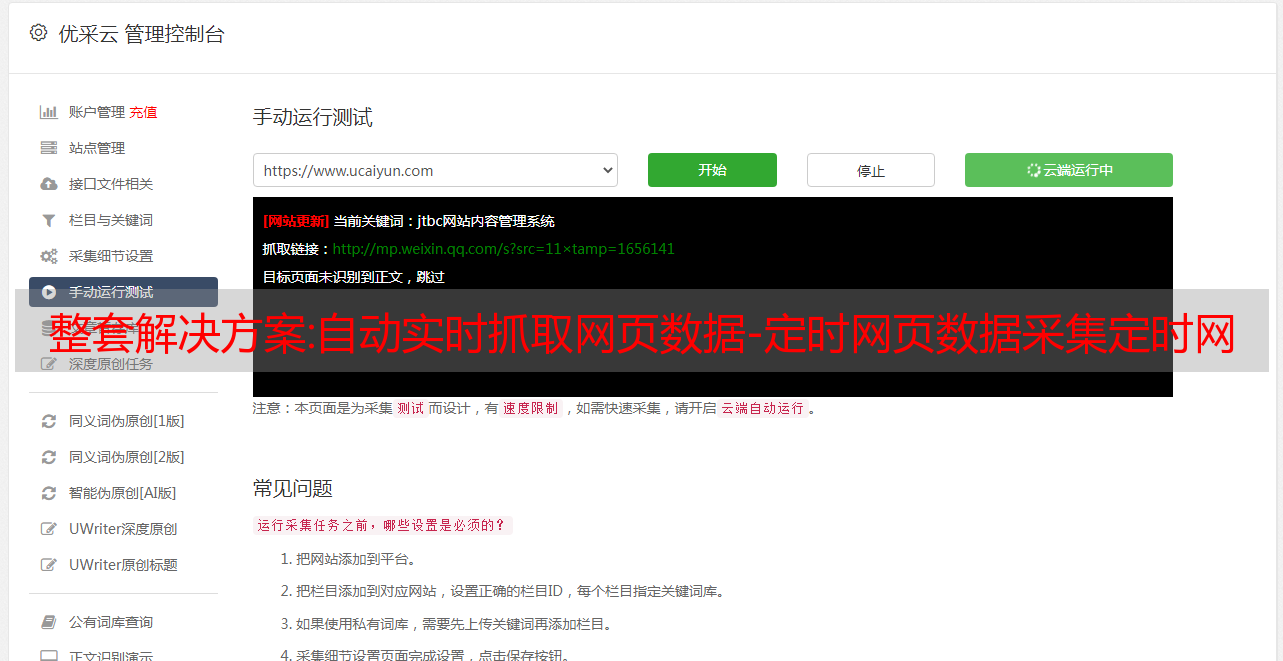
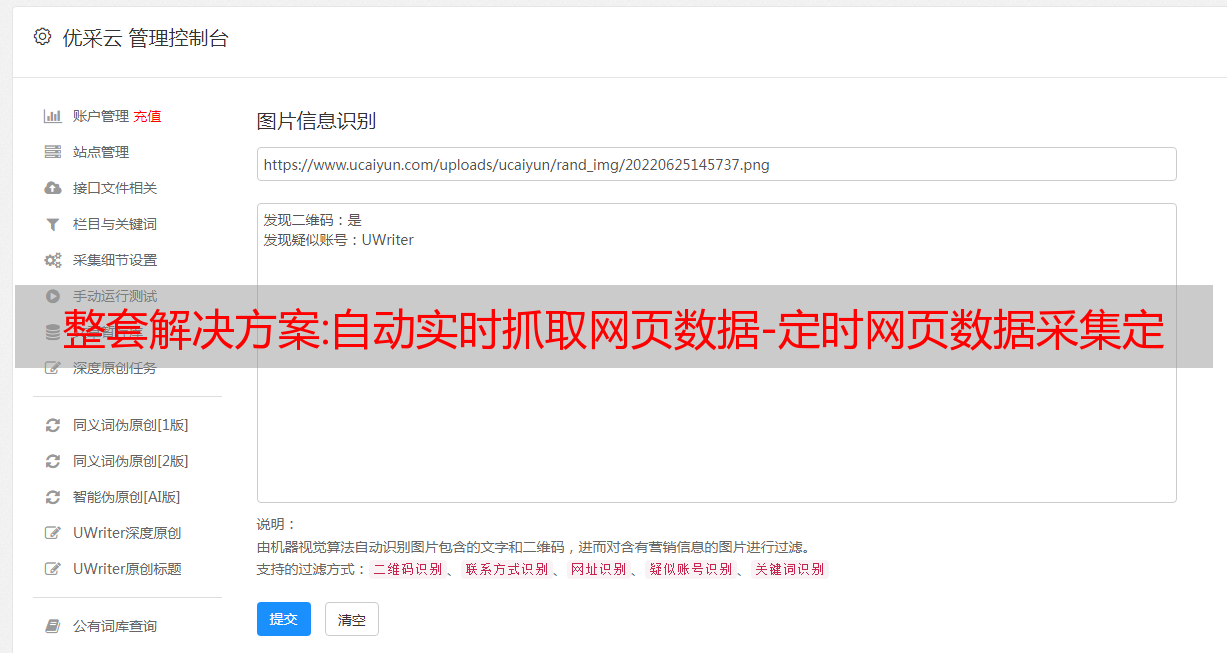
网页数据抓取,什么是网页抓取。如何快速抓取网络数据。今天给大家分享一款免费的网页数据抓取软件,只需要输入网站域名自动抓取网站页面数据,自动抓取网页数据+自动网站< @k6@ > 发帖,详情请看图片。
选择域名很重要,因为这是网站优化的第一步。注册域名时,我们首先要找一个与主题相关的域名。首选是中文拼音,其次是英文。如果不是,请选择一个域名较短的域名。它是衡量SEO效果的必要因素,虽然它对SEO的效果影响不大。很大,不过还是要跟上,一定的水平有利于后期的优化和传播。
1)注册的域名越短越好。域名越短,越容易记住。域名注册可以去万网或者其他大品牌,因为安全性会更好。
2)为网站的主题选择一个域名
注册域名时需要定位网站主题,根据网站主题选择相关域名
3)关键字优先使用中文拼音,关键字优先使用英文。现在指定的域名不用直接选择双拼了,推荐双拼+号的方式。另外,建议一次性注册一组域名,以免其他域名被别人注册,日后要天价。 , 如果英语语言注册最好针对目标群体,如果是大众群体,不利于优化交流。比如网页数据爬虫群的站长对英文比较熟悉,包括bbs、news、blog,而且好记。
4).Com .Cn .Org . . . .net .gov .edu
域名的后缀对于SEO也很重要。一般来说,.gov .edu 非政府和教育机构无权注册,但.gov .edu 域名拥有最高权限,.com .org .gov 国际域名更适合国内域名。 . . ,主要是声誉成本问题。
注:国际域名升值空间更大。 .cc .tv .me 等其他域名使用相对较少。除非您专门从事域名研究,否则不建议注册一些不常见的声誉后缀。是的,否则就是浪费钱。
5)域名注册时间越长越好
搜索引擎无论是否抓取网络,都会抓取域名的whois信息。网页数据爬取包括域名的whois信息,如注册时间、过期时间等。
既然seo是网站的收录,那么它和数量有直接关系,原因是由于网站的搜索效果的概率。更何况长尾关键词,长尾关键词的排名优化会直接影响长尾关键词的排名次数,网页数据抓取而网站的排名有数百个因素影响网站收录。
那我给大家讲讲影响网站收录的因素,首先是网站的开启速度,网站的开启速度大家都知道速度不仅影响你的网站,对用户体验也不利。网页数据爬取,那你觉得如果网站打开慢会影响蜘蛛的阅读,所以网站打开速度很重要,关于影响网站@打开速度> 原因包括服务器提供商、服务器宽带速度、服务器硬件质量、服务器操作系统、服务器软件操作、DNS等。
接下来是网站权重的影响。每个人可能都不知道网站的重量。这个权重问题将直接关系到搜索引擎对网站的信誉值的评价。 网站 如果权重高,那么搜索引擎的抓取会更及时,有时会秒到。这也是由于该站点的权重相对较高。相反,如果网站的权重很低,则证明搜索引擎对网站的声誉值的评价很低。蜘蛛对站点的爬取频率会低,一旦站点正常,灰腕很可能直接被K驻扎。
其次要说一下网站结构的结构设置,结构外观美观,小场地多规划为平面结构,大场地多规划为树结构。网页数据抓取是我们的网站结构和规划复杂,复杂的内部链规划会导致网站收录慢,尤其是二级栏目和三级内容页面收录 更慢甚至无效收录。比如我们要建一栋楼,每一层都要一样,每一层的结构都要非常坚固。因此,当我们规划网站的构建时,不同的列可以直接链接内部链。同时网站的目录深度最好限制在三层,以免影响蜘蛛对收录爬得太深。
总结:简易数据分析(五):Web Scraper 翻页、自动控制抓取数量 & 父子选择
Tuque 社区推荐搜索关键词列表:简单数据分析 Nest.jsAsync
本文介绍了一种控制网页链接批量抓取数据的方法。
但是当你预览一些网站的时候,你会发现随着网页的下拉,需要点击类似“加载更多”的按钮来获取数据,而网页链接并没有改变了。
此时控制链接批量抓取数据的方案无效,需要模拟点击“加载更多”按钮抓取更多数据。
我们今天说的就是利用网络爬虫中的Element点击来模拟点击“加载更多”来加载更多数据。
在本次练习网站中,我们以小众网站中流行的文章作为我们的练习对象,对应的URL链接为:
%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0#home
为了查看内容,这次我们模拟点击翻页,同时抓取多条内容,包括作者、标题、点赞数和评论数。
在下面开始我们的数据之旅采集。
1.创建站点地图
老规矩,第一步是创建一个少数sitmap,命名为sspai_hot,起始链接为:
%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0#home
2.创建容器选择器
从上一节的内容我们知道,如果要在网络爬虫中抓取多种类型的数据,首先要创建一个容器(container),里面收录多种类型的数据,所以我们的第二步就是到要为其创建容器的选择器。
需要注意的是,这个选择器的Type类型选择为Element click,翻译成中文模拟点击元素。顾名思义,我们可以使用这种类型来模拟点击“加载更多”按钮。
这种类型的选择器会有更多的选项。第一个是点击选择器,即选择“加载更多”按钮。选择操作可以在下面的*敏*感*词*中看到。
还有几个附加选项,我们一一解释:
1.点击类型
点击类型,点击更多表示点击多次,因为我们要采集批量数据,这里我们选择点击更多,还有一个点击一次选项,点击一次
2.点击元素唯一性
此选项控制 Web Scraper 何时停止抓取数据。例如 Unique Text,即当文本发生变化时停止获取数据。
我们都知道一个网站的数据不可能是无穷无尽的,总会有加载的时候。这时“加载更多”按钮的文字可能会变成“没有更多”、“没有更多数据”、“已加载”等字样,当文字发生变化时,网络爬虫会知道没有更多数据,并会自动停止抓取数据。
3.多个
这是我们的老朋友,意思是是否多选,这里我们要抓取多条数据,当然要勾选多项。
4.丢弃初始元素
是否丢弃初始元素,这个主要是用来去除一些网站重复的数据,不是很重要,我们这里不需要,选择Never discard,从不丢弃数据。
5.延迟
延迟时间,因为点击加载更多后,数据加载需要一段时间,延迟是等待数据加载的时间。一般我们设置为大于等于2000,因为2s的延迟是比较合理的数据。如果网络不好,我们可以设置一个更大的数字。
3.创建子选择器
接下来,我们创建几个子选择器来捕获四种类型的数据:作者、标题、点赞数和评论数。详细的操作我在之前的教程中已经讲解过了,这里就不详细讲解了。 整个爬虫的结构如下,可以参考:
4.捕获数据
按照站点地图spay_hot的操作路径->刮取数据。
今天我们学习了如何使用 Web Scraper 抓取更多类型的点击加载网页。
在实践过程中,你会发现这种网页无法控制爬取次数,不像豆瓣TOP250,明明是250条数据,不多也不少。
在下一篇文章中,我们将讨论如何使用 Web Scraper 自动控制抓取次数。
今天我们来说说Web Scraper的一些小功能:自动控制Web Scraper的爬取次数和Web Scraper的父子选择器。
如何只抓取前100条数据?
如果你按照步骤一步一步来,你会发现爬虫会继续运行,根本不会停止。如果一个网页有1000条数据,他会抓取1000条数据,如果有10W条数据,他会抓取10W条数据。如果我们的需求很小,只想抓取前 200 个怎么办?
如果手动关闭抓取数据的网页,会发现数据全部丢失,数据也没有保存,所以这种暴力行为是不可取的。我们目前有两种方法可以阻止 Web Scraper 抓取。
1.断线大法
当你感觉数据快要被捕获时,直接断开计算机的网络。一旦断网,浏览器无法加载数据,Web Scraper会误认为数据已被抓取,然后自动停止自动保存。
断网的方法简单粗暴。虽然不优雅,但很有效。缺点是要盯着旁边看,关键点都是手动操作的,不是很智能。
2.通过数据号控制记录数
比如流行的小众文章爬虫,容器的Selector是dl.article-card,它会抓取网页中所有编号为dl.article-card的数据。
我们可以在这个Selector后面加一个:nth-of-type(-n+100),意思是抓取前100条数据,前200条是:nth-of-type (-n +200), 1000 是:nth-of-type(-n+1000),依此类推。
这样,我们可以通过控制数据的个数来控制需要抓取的数据。
抓取链接数据时页面跳转怎么办?
在抓取数据时,可能会遇到一些问题。比如爬取标题时,标题本身就是一个超链接。点击圈出的内容后,又打开了一个新的网页,干扰了我们对圈出内容的判断和体验。不是很好。
其实网页爬虫提供了相应的解决方案,就是通过键盘选择元素,这样就不会触发点击打开新网页的问题。具体操作面板如下图所示,就是我们点击Done Selecting所在的控制栏。
我们选中单选按钮后,会出现三个字符S、P、C,含义如下:
S:选择,按键盘的S键选择被选元素
P:Parent,按键盘上的P键选择被选元素的父节点
C:Child,按键盘C键选择被选元素的子节点
我们分别演示一下,先用S键选择标题节点:
对比之前的*敏*感*词*,我们会发现当节点被选中并变红时,并没有打开新的网页。
如何抓取被选元素的父节点或子节点?
使用 P 和 C 键选择父节点和子节点:
按下P键后,我们可以明显看到我们选择的区域变大了,再次按下C键后,选择区域又变小了。这就是父子选择器的作用。
本期介绍使用 Web Scraper 的两个技巧。下一期我们会讲Web Scraper是如何抓取无限滚动网页的。
<p style="margin-top: 10px;margin-bottom: 5px;padding-right: 0em;padding-left: 0em;letter-spacing: 1.5px;line-height: normal;">● 简易数据分析(三):Web Scraper 批量抓取豆瓣数据与导入已有爬虫
● 简易数据分析(二):Web Scraper 初尝鲜,抓取豆瓣高分电影
● 简易数据分析 (一):源起、了解 Web Scraper 与浏览器技巧
<br /></p>
·END·
图克社区
精彩的免费实用教程合集

