内容分享:谷歌浏览器获取cookie以及抓包获取真实链接
优采云 发布时间: 2022-09-22 13:10内容分享:谷歌浏览器获取cookie以及抓包获取真实链接
目前大部分浏览器都有自己的开发者工具(一般是按f12出现),打开网站后就可以看到网页的cookies和加载的各种信息。
以谷歌浏览器为例:
1.在谷歌浏览器中打开网址
在分页上点击网址时,会发现网址没有变化。这是一个典型的帖子 URL,需要捕获包的真实链接。
2.从右上角的自定义控件打开开发者工具或者直接按f12运行,
3.打开工具点击页面后,工具中出现一个链接,是网站翻页的请求信息
4.有些网站有不止一个翻页请求信息。如果对请求不确定,可以通过查看请求信息的回执内容来判断真正的翻页请求,如图
5. 接下来根据header中的信息判断翻页URL是get还是post。get URL一般可以直接打开访问(但不带特殊头信息),post URL不能直接打开(只能在软件中直接打开)
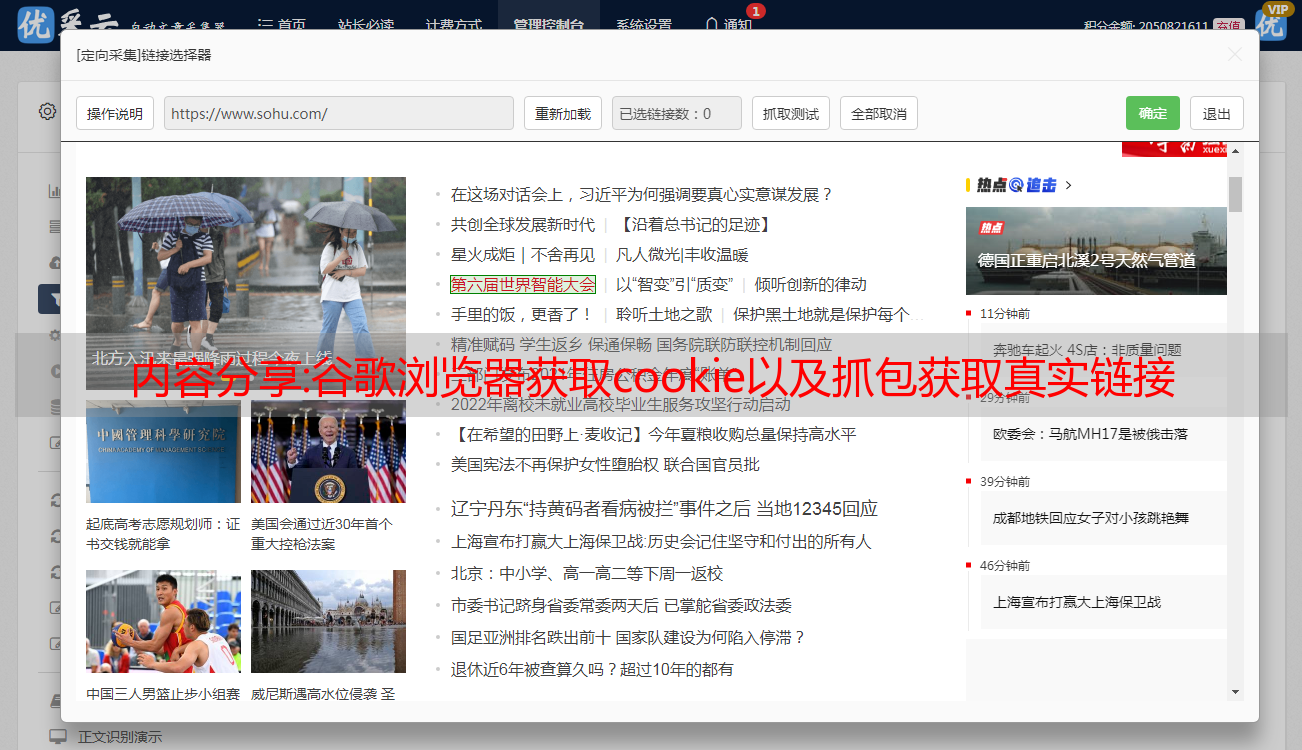
6. 查看header中的信息,你会发现这是一个post请求,但是这里并没有post请求参数,但是可以看到header后面有一个payload,参数其实是放在这里
通过以上步骤,基本获得了内容页面的制作和获取规则的相关信息。设置了以下规则
1.例如从pesponse获取内容页面相关参数
2.post参数设置,可以点击payload中的view sorce获取如下参数
解密:二、爬虫如何抓取网页数据
3.从 HTML 页面中提取有用的数据
一个。如果需要,保存数据
湾。如果是页面中的另一个 URL,则进行第二步。
2.3 如何抓取 HTML 页面
HTTP请求处理:urllib、urllib2、request 处理后的请求可以模拟浏览器发送请求,得到服务器响应的文件。
2.4 解析服务器响应的内容
re、xpath、BeautifulSoup4(bs4)、jsonpath、pyquery 等。
2.5 如何采集动态HTML,验证码处理
采集 用于一般动态页面:Selenium+PhantomJs(无界面),模拟真实浏览器加载
三、万能爬虫,专注爬虫
3.1 通用爬虫:搜索引擎的爬虫系统。
1.目标:就是尽可能的把网上所有的网页下载下来,放到本地服务器形成的备份库中,然后对这些网页做相关的处理(提取关键词,去除广告),并提取有用的东西
2.爬取过程:
a:优先选择一部分已有的URL,将这些URL放入爬虫队列。
b:从队列中取出这些URL,然后解析DNS得到主机IP,然后到该IP对应的服务器下载HTML页面。宝初到搜索引擎本地服务器后,将爬取的URL放入爬取队列
c:分析网页内容,找出网页上的其他链接,继续执行第二步,直到找到相关信息
3.2 搜索引擎如何获取 网站 URL
1.主动提交给搜索引擎网站
2.其他网站设置网站的连接
3.搜索引擎将与DNS服务商合作快速收录新网站,DNS:是一种将域名解析为IP的技术。

