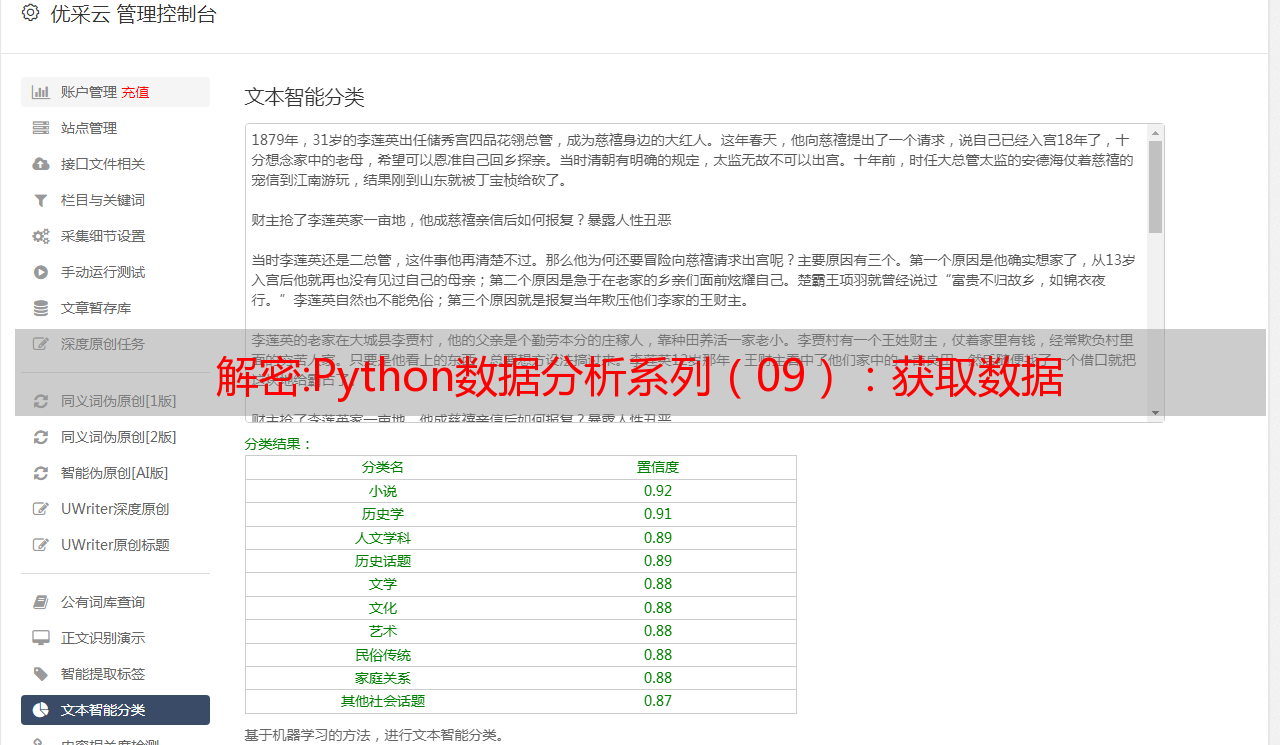
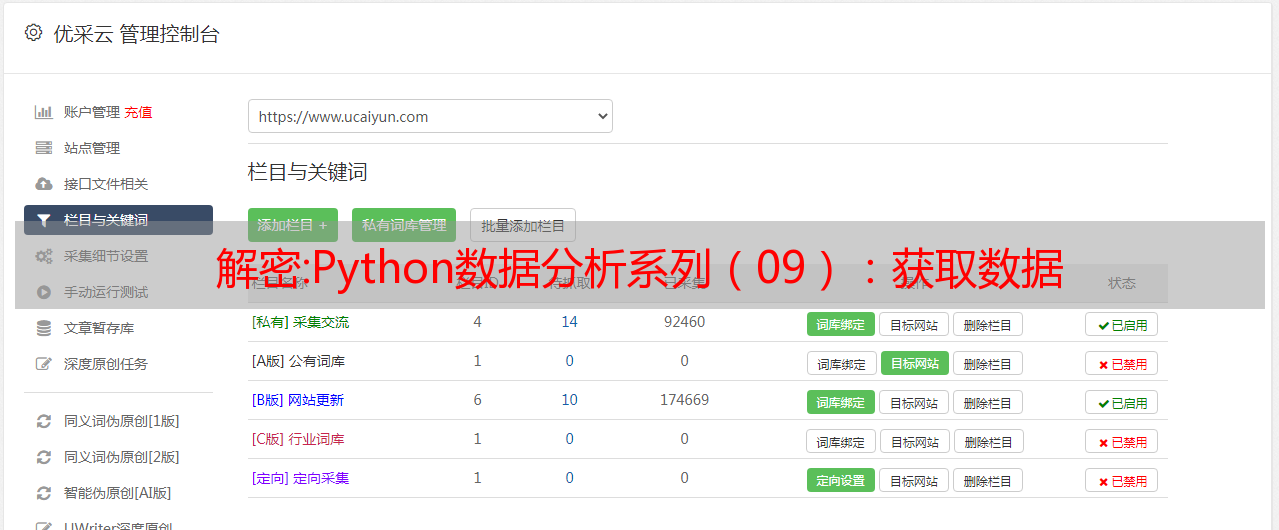
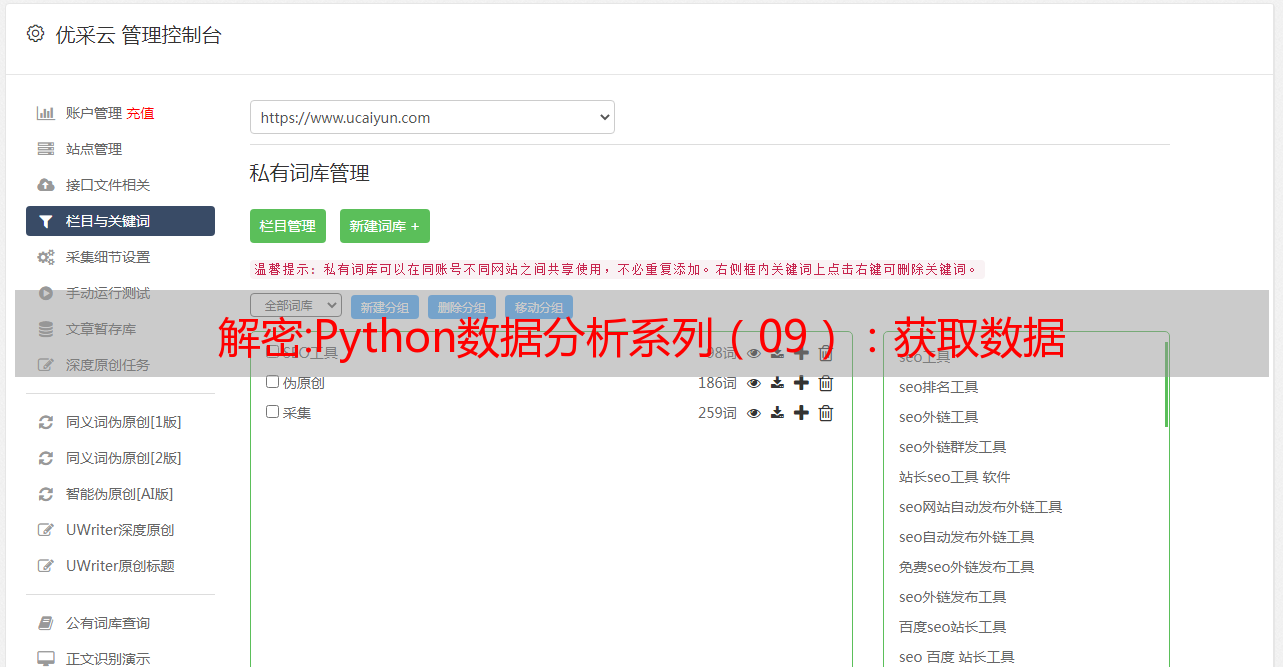
解密:Python数据分析系列(09):获取数据
优采云 发布时间: 2022-09-22 03:09解密:Python数据分析系列(09):获取数据
对于元素中的每个元素,您可以这样做:
仅上述功能就可以帮助我们做很多事情。如果您需要做一些更复杂的事情(或者只是出于好奇),请查看文档。
当然,无论数据多么重要,通常都不会被标记。您需要仔细检查源 HTML,通过您选择的逻辑进行推理,并考虑边缘情况以确保数据的正确性。接下来我们看一个例子。
9.3.2 示例:关注国会
一家数据科学公司的政策副总裁担心数据科学行业的潜在监管,并要求您量化国会对该主题的看法。他特别希望您找到所有发布“数据”新闻稿的代表。
在发布时,有一个页面收录所有代表 网站 的链接
如果您“查看源代码”,所有 网站 链接看起来像:
让我们从采集从此页面链接到的所有 URL 开始:
这将返回太多 URL。如果您查看它们,我们会以 或 中间的某种名称开头并以 . 结尾。或者 。/。
这里是使用正则表达式的好地方:
这仍然太多了,因为只有 435 名代表。如果您查看列表,则有很多重复。我们可以使用 set 来克服这些问题:
总会有一些众议院席位空缺,或者可能有一些没有网站 代表。无论如何,这已经足够了。当我们查看这些 网站 时,大多数 网站 都有新闻稿的链接。例如:
请注意,这是一个相对链接,这意味着我们需要记住原创站点。让我们抓住它:
注意
通常,像这样随便爬一个 网站 是不礼貌的。大多数 网站 都会有一个 robots.txt 文件,指示您可以多长时间抓取一次站点(以及您不应该抓取哪些路径),但由于这是国会,我们不需要特别有礼貌的。
如果您滚动查看它们,您会看到很多 /media/press release 和 media center/press release 以及其他各种地址。其中一个 URL 是 /media/press-releases。
请记住,我们的目标是找出哪些国会议员引用了“数据”。“我们将编写一个稍微通用的函数来检查是否在一页新闻稿中提到了任何给定的术语。
如果您访问该 网站 并查看源代码,似乎
标签中有每个新闻稿的片段,所以我们将使用它作为我们的第一次尝试:
让我们为它写一个快速测试:
最后,我们将找到相关的国会议员,并将他们的名字提供给政策副总裁:
当我运行这个时,我得到一个大约 20 次重复的列表。您的结果可能会有所不同。
注意
如果您查看不同的“新闻稿”页面,它们中的大多数都是分页的,每页只有 5 或 10 个新闻稿。这意味着我们只检索到了每位国会议员最近发布的几篇新闻稿。更彻底的解决方案将遍历页面并检索每个新闻稿的全文。
9.4 使用 API
许多 网站 和 Web 服务提供相应的应用程序编程接口 (APIS),允许您以结构化格式显式请求数据。这样可以省去抓取数据的麻烦!
9.4.1 JSON(和 XML)
因为 HTTP 是一种用于转换文本的协议,所以您通过 Web API 请求的数据需要序列化为字符串格式。通常,此序列化使用 JavaScript Object Notation (JSON)。JavaScript 对象看起来很像 Python 字典,使得字符串表示非常容易解释:
我们可以使用 Python 的 json 模块来解析 JSON。特别是,我们将使用它的加载函数,它将表示 JSON 对象的字符串反序列化为 Python 对象:
有时 API 提供者可能不是那么友好,只给你 XML 格式的响应:
我们也可以使用 BeautifulSoup 从 XML 中获取数据,就像从 HTML 中获取数据一样;有关更多详细信息,请参阅文档。
9.4.2 使用API无需认证
今天的大多数 API 都要求您在使用它们之前进行身份验证。如果我们不想强迫自己遵守这个政策,API 会给出许多其他陈词滥调来阻止我们的浏览。所以,让我们看一下 GitHub 的 API,我们可以用它做一些简单的事情,而无需身份验证:
这里的 repos 是一个 Python 字典列表,其中每个字典代表我 GitHub 帐户中的一个代码存储库。(请随意替换您的用户名以从您的存储库中获取数据。您有一个 GitHub 帐户,对吗?)
我们可以使用它来找出最有可能创建存储库的月份和星期几。唯一的问题是响应中的日期是一个字符串:
Python 本身并没有非常强大的日期解析器,所以我们需要安装一个:
您所需要的可能是 dateutil.parser.parse 函数:
同样的,你可以得到我最近五个仓库的语言:
通常我们不需要在“自己发出请求并解析响应”的低级别使用 API。使用 Python 的好处之一是,有人已经构建了库,可以让您访问几乎所有您感兴趣的 API。这些库可以完成工作,并为您省去查找 API 访问的许多繁琐细节的麻烦. (如果这些库不能很好地完成它们的工作,或者它们依赖于相应 API 的失效版本,那么您将遇到巨大的麻烦。)
尽管如此,有时您仍需要操作自己的 API 访问库(或者,更常见的是,调试其他人没有的库),因此了解一些细节是件好事。
9.4.3 查找 API
如果您需要特定 网站 的数据,请查看其开发人员部分或 API 部分以获取详细信息,然后使用 关键词“python api”在 Web 上搜索相应的库。
有 Yelp API、Instagram API、Spotify API 等库。
如果您想查看具有 Python 包装器的 API 列表,可以在 GitHub (/realpython/list-of-python-api-wrappers) 上找到来自 Real Python 的 API 列表。
如果最后还是找不到自己需要的API,还是可以通过抓取来获取的。这是数据科学家的最后一招。
9.5 示例:使用 Twitter API
Twitter 是一个非常好的数据源。您可以从中获取实时新闻,可以使用它来衡量对当前事件的反应,还可以使用它来查找与特定主题相关的链接。只要您可以访问其数据,您几乎可以使用 Twitter 做任何您能想到的事情。数据可以通过其API获取。
要与 Twitter API 交互,我们需要使用 Twython 库(python -m pip install twython)。Python Twitter 实际上有很多库,但这是我用过的最好的一个。您也可以尝试其他库。
获取凭据
为了使用 Twitter 的 API,首先需要获取一些文档(无论如何,您必须拥有一个 Twitter 帐户,这样您才能成为活跃和友好的 Twitter #datascience 社区的一部分)。
注意
就像我无法控制的所有 网站 指令一样,它们在某个时候会过时,但现在仍然可以工作一段时间。(虽然在我写这本书的时候它们至少改变了一次,但祝你好运!)
以下是步骤:
1. 找到链接/。
2. 如果您还没有注册,请点击“注册”并输入您的 Twitter 用户名和密码。
3.单击应用申请开发者帐户。
4.请求访问以供您自己使用。
5.填写申请表。需要 300 个字(真的)来解释你为什么需要访问数据,所以为了通过审查,你可以告诉他们这本书以及你有多喜欢它。
6.等待不确定的时间。
7.如果您认识在 Twitter 上工作的人,请给他们发电子邮件并询问他们是否可以加快您的申请。否则,请继续等待。
8.批准后,返回应用程序部分并单击创建应用程序。
9.填写所有必填字段(同样,如果描述需要额外的字符,您可以讨论这本书以及如何找到它)。
10.单击创建。
您的应用现在应该有一个“Keys and Tokens”选项卡,其中收录一个“Consumer API Public Key”部分,其中列出了“API Public Key”和“API Key”。“注意这些钥匙;你需要它们。(并且,保守秘密!它们就像密码。)
当心
不要分享它们,不要将它们打印在书籍中,也不要将它们记录在公共 GitHub 存储库中。一种简单的方法是将它们存储在不会签入的 credentials.json 文件中,然后使用 json.loads 检索它们。另一种解决方案是将它们存储在环境变量中并使用 os.environ 检索它们。
使用 Twython
使用 Twitter API 最棘手的部分是身份验证。(事实上,这是使用大量 API 中最棘手的部分。)API 提供者希望确保您有权访问他们的数据并且您不会超出他们的使用限制。他们还想知道谁在访问他们的数据。
身份验证有点痛苦。有一种简单的方法,OAuth 2,当您只想进行简单的搜索时就足够了。还有一种复杂的方式,即 OAuth 1,当您想要执行某个操作(例如 twitter)或(尤其是对我们而言)连接到 twitter 流时,它是必需的。
所以我们坚持使用更复杂的方法,我们将尽可能地自动化。
首先,您需要您的 API 公钥和 API 密钥(有时分别称为消费者公钥和消费者密钥)。我可以从环境变量中获取它,如果需要,您可以随时替换它们:
现在我们可以实例化客户端:
暗示
此时,您可能需要考虑将 ACCESS_TOKEN 和 ACCESS_TOKEN_SECRET 保存在安全的地方,这样下次您就不必经历这个严格的过程。
一旦我们有了一个经过验证的 Twython 实例,我们就可以开始执行搜索:
如果您运行上述程序,您应该会收到一些推文,例如:
这并不是那么有趣,主要是因为 Twitter 搜索 API 只是向您显示了一些最近的结果。当你在做数据科学时,你经常想要很多推文。这就是流 API 有用的地方。它允许您连接到一个很棒的 Twitter“消防水带”。要使用它,您需要使用访问令牌进行身份验证。
为了使用 Twython 访问流 API,我们需要定义一个继承自 TwythonStreamer 并覆盖其 on_success 方法和可能的 on_error 方法的 on_success 方法:
MyStreamer 将连接到 Twitter 流并等待 Twitter 向其发送数据。每次它接收到一些数据(这里,一条推文表示为一个 Python 对象)它都会传递给 on_success 方法,如果推文是英文的,这个方法会将推文附加到推文列表中,在采集到 1000 条推文后文本后将断开与流的连接。
剩下的就是初始化并开始运行:
它将一直运行,直到采集到 1000 条推文(或直到它遇到错误),此时是时候开始分析这些推文了。例如,您可以找到最常见的标签:
每条推文都收录大量数据。您可以自己尝试各种方法,或仔细阅读 Twitter API 文档。
注意
在正式项目中,您可能不想依赖内存列表来存储推文。相反,您可能希望将推文保存在文件或数据库中,以便永久拥有它们。
9.6 扩展学习
• pandas 是数据科学用来处理(尤其是导入)数据的主要库。• Scrapy 是一个强大的库,可用于为跟踪未知链接等任务构建更复杂的网络爬虫。• Kaggle 拥有庞大的数据集。
官方数据:(16)UiBot:智能化软件机器人(以头歌抓取课程数据为例)
文章目录
一、实验平台——UiBot
官网下载链接:
UiBot 是一个机器人流程自动化服务平台。其产品包括三个模块:创造者、工人和指挥官。用户可以记录过程,通过平台一键自动生成机器人。支持可视化编程和专业模式,浏览器、Desktop、SAP等控制抓取和C、Lua、Python、.Net扩展插件和第三方SDK接入,实时监控和调整业务和权限。
UiBot产品主要包括创造者、工作者、指挥官、魔法师四大模块,为机器人的生产、执行、分发、智能提供相应的工具和平台。
Creator 是一款用于构建过程自动化机器人的机器人开发工具。
劳动者是机器人运行工具,用于运行搭建好的机器人。
指挥官是部署和管理多个机器人的控制中心。
Sorcerer 是一个 AI 能力平台,可为机器人提供执行流程自动化所需的各种 AI 能力。
二、项目功能及实现1、项目介绍
机器人的主要目标是自动捕获热门歌曲页面上提交的学生培训。
机器人会打开头曲页面,点击我的头像查看课程,进入“XX课程”。点击进入过期培训计划,我的账号可以查看每个学员的培训过关状态。
为了遍历物品列表,机器人抓取过期页面上的所有物品名称。因为页面太长,无法智能识别抓取,提取的数据也无法直接转成字符串。因此,将所有训练项写入Excel,然后读出,在网络搜索栏中依次搜索,遍历所有训练项。
在培训详情中,所有学生提交的信息都会被抓取并输出到Excel表格中。一般来说,学员应在培训项目结束后按时通关。对于异常提交,如延迟通关、未通关、未开通等,将在Excel中以不同颜色突出显示,并在处理过程中保留各种异常情况的学生。号码。
最后,将统计结果写入 Excel 单元格,以捕获未完成作业的学生组。
最终的Excel效果如图。
2、 项目流程(1)全局变量设置
为了实现流程图中的数据共享,本项目设置了以下流程图变量,即全局变量。它将在运行整个项目时创建和共享。全局变量的设置可以参考报告中的章节。
(2)页面登录和跳转
在这个过程中,机器人主要实现以下步骤
机器人会自动打开浏览器并访问网站。由于已在本地计算机上自动登录,因此无需再次登录。点击我的头像直接进入我的教学内容。
选择“大学计算机基础”
点击课程后,默认进入培训作业页面,查看过期项目。
(3)Excel记录项名称和编号
因为要遍历每个训练项目,以后再爬取数据,所以在这个流程块中,要获取所有的训练名称,这样就可以依次进入对应的训练页面。但是,直接从网页爬取的数据并不是纯字符串。参见解决此问题的解题方法。
自动将所有训练名称保存到训练 details.xlsx。
(4)搜索爬取第i个训练项目
CurProject标识当前遍历的训练项目个数,初始值为0。这部分流程涉及到遍历,在流程块外实现,循环的具体内容在流程块内实现,即进入第i个训练项目爬取学生项目的完成情况。涉及以下步骤:
CurProject 代表当前训练项目的序号。进入本节后+1会从第一个项目开始遍历。
读取training details.xlsx的Sheet1工作表中A&CurProject单元格的数据,即培训项目的名称。比如第一个项目是von Neuy xxxx。
在页面的搜索框中输入项目名称,回车,点击面板进入项目的工作列表
爬取页面数据,由于页面是表格形式,可以快速爬取。设置要翻页的页数。由于每个训练项目都是同一个学生参加,所以要翻页数固定为4。这里可能会出现数据采集不完整的问题,解决问题可以看解决方案。
同时,为了打开页面而不在第一页,可以设置页面滚动条,滑动到页面选择,选择第一页然后爬取数据。添加此操作可以防止页面错误和不完整的数据抓取。
(5)新建工作表,重命名写入,删除无效列
对于不同的训练任务,在Excel中会存储在不同的工作表中,表名就是训练名,所以需要如下步骤。
此时会发现有很多列数据不起作用,所以设置删除这些列。
(6)Excel 亮点和统计数据
由于同学们的投稿分为四种情况:准时清关、迟报清关、未清关、未开关,后三者被视为异常情况,需要记录和统计,使用Late,取消订阅并取消开始录制。
数据写入时,遍历每一行数据,查看每个学生对应的作业状态。根据作业状态(IsSubmit)判断条件。如果是异常状态,会用对应的单元格和文字的颜色高亮,对应变量的值为+1。
最后将每个异常情况的统计值列在工作表J1:K4的位置。
因为要进入下一个循环,所以需要关闭当前标签页(即关闭第i项的提交详情界面)。
(7) 循环执行(4)-(6)
循环条件:CurProject>=TrainNum。其中,CurProject代表当前遍历的项目序号,TrainNum代表训练项目总数。
也就是说,对于每个项目,都会进行一次搜索操作。得到搜索结果后,会自动点击进入训练项目,抓取学员提交的内容。在Excel中新建工作表,命名训练项目名称,写入数据,删除无用数据,异常情况高亮统计,可视化。
(8)关闭页面和表单
遍历完所有训练项后,关闭选项卡和表单,流程结束。
三、 问题解决 1、 全局变量
问题:
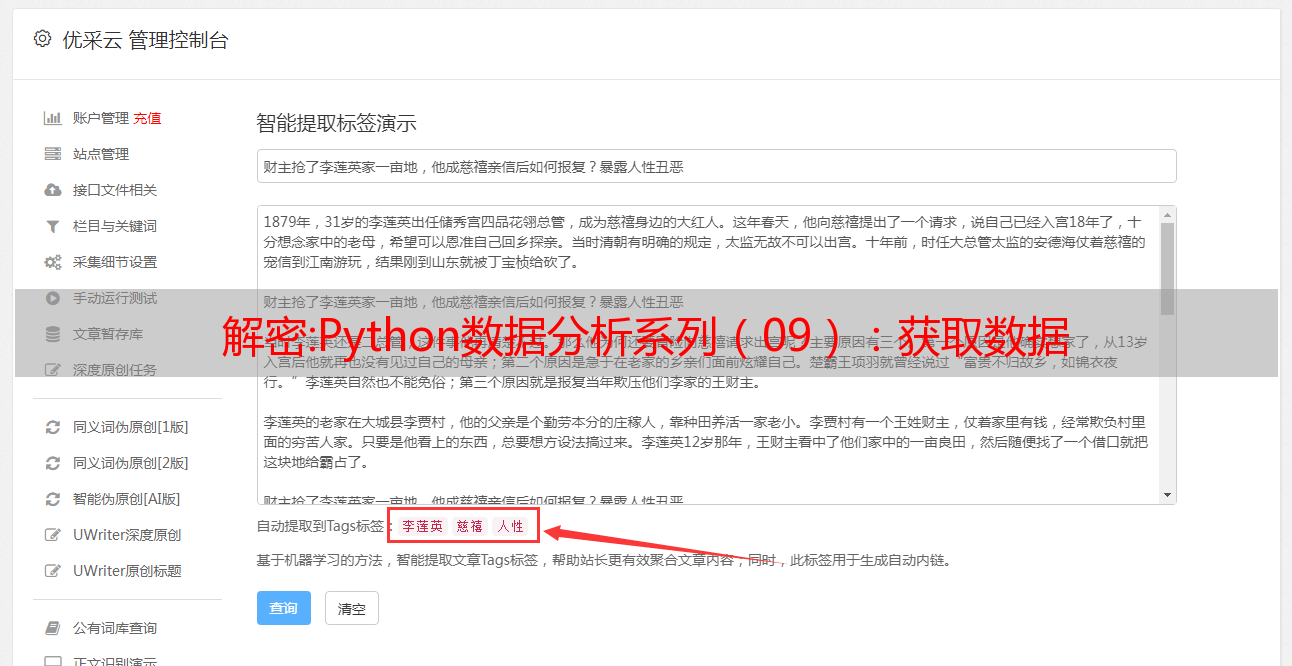
在流程图中,每个block都实现了自己的主要功能,但也有一些数据交互和共享功能。如果在每个进程块中输出一些变量并在下一个进程块中接收,那么变量的传输将变得非常繁琐。观看较早的教学视频只会发现这种交付方式。 【参考】
解决方案:
但是新版开发者指南提供了一些全局变量、循环逻辑和流程块的相关操作。 【参考】,然后可以设置全局变量,面板中的操作会给变量附加新的值,方便进程间的数据传递。
2、插件配置
问题:
在项目过程的步骤中,你会发现当Chrome浏览器设置为打开指定链接时,机器人可以打开Chrome,但无法正确跳转到页面。
解决方案:
需要安装Chrome插件,在首页-工具-Chrome扩展中安装,在浏览器设置-扩展中启用扩展。其他浏览器也可以相应地安装扩展。
参考链接:
3、 获取数据后获取纯字符串
问题:
在项目过程的步骤中,希望获取每个训练项目的名称字符串,实现遍历点击。但是你会发现数据抓取的结果是一个列表,每个item的输出也是一个列表。
爬取得到的数据如下图所示。不是纯字符串,不符合预期。
解决方案:
我想到的解决方案是先将数据写入Excel。然后阅读 Excel 内容。此时读取的字符串是纯字符串,不是列表。
4、数据采集不完整
问题:
在项目过程的步骤中抓取数据时,有时会发现数据抓取不完整。保存到 Excel 表格后,如下图所示。
解决方案:
这个问题很可能是页面延迟问题。数据将进入下一步,然后才能加载。解决这个问题的关键是设置延迟。可以通过以下方案解决
增加上一个动作执行后的延迟时间,可设置为800-1000。
插入延迟命令。设置操作完成运行的等待时间。
5、连接器形状
问题:
在绘制流程图的过程中,发现连接线经常比较混乱,无法按照想要的方式连接起来。
解决方案:
按住Ctrl+鼠标左键在连接线上添加点,拖动点使连接线合理。

