干货内容:资源采集-免费资源采集工具-音频视频文字图片资源采集免费
优采云 发布时间: 2022-09-21 17:12干货内容:资源采集-免费资源采集工具-音频视频文字图片资源采集免费
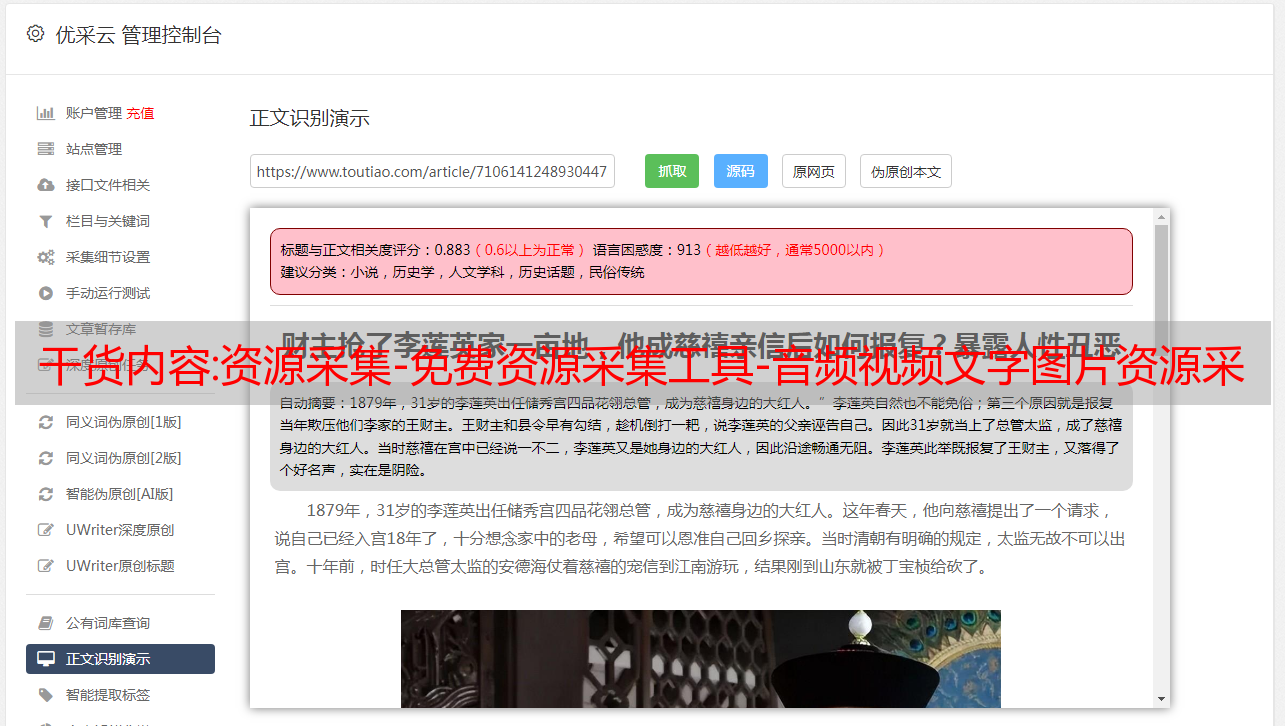
资源采集,网上的资源大致分为文字图片资源、音频资源、视频资源。我们如何才能快速采集 这些资源供我们使用?今天给大家分享一个免费资源采集软件。整个可视化过程基于0采集,具体请看图。
资源的作用采集:很多网站的内容是一个人无法完成的,所以网上的相关内容都是用采集软件采集来过来,然后被软件自动发布,这样的网站就形成了。
SEO 需要涉及各种因素。一些细节控制不好,往往会严重影响网站优化的提升效果。今天我们主要讲关键词优化技术。资源 采集希望你能通过这个问题的细节看到一个好的排名。
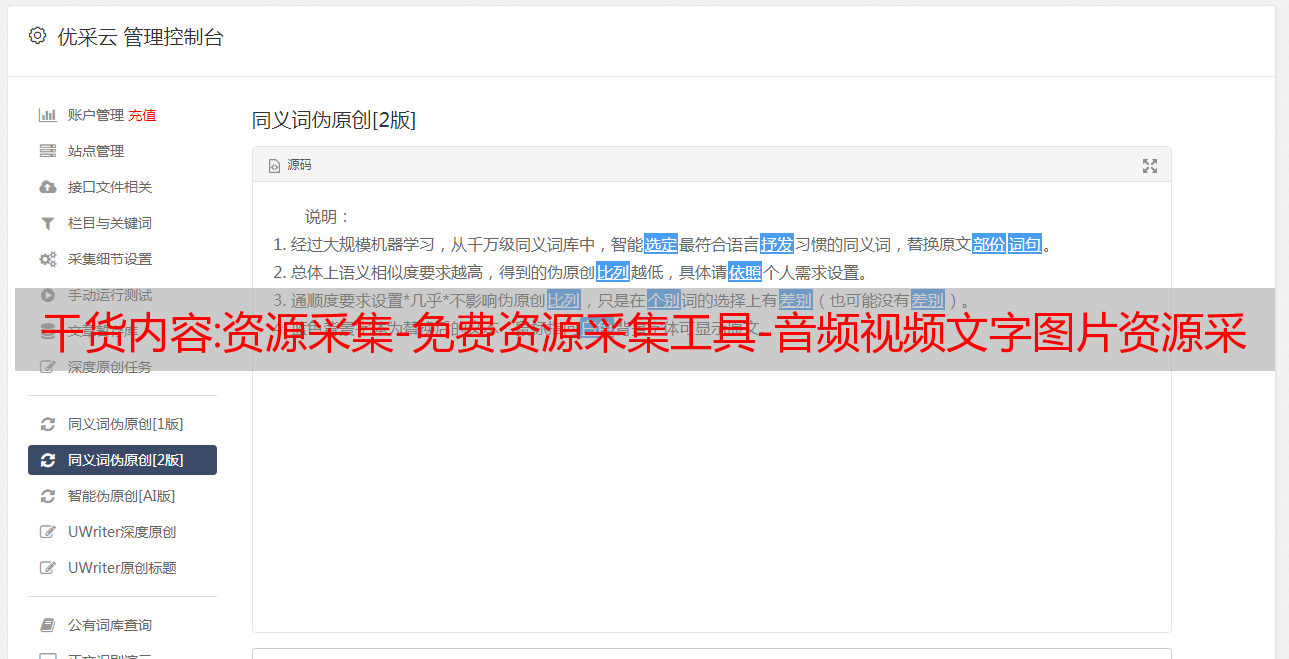
一、选择关键字
关键词排名的优势是对网站流量有直接影响,因此,关键词的选择不是随机的,找一些有意的关键词来定义,资源采集草级站长和企业站长在做SEO的时候对于关键词的选择是不一样的。
1、一般草根站长在选择关键词的时候需要找一些比较难的关键词。一般来说,hard关键词 索引会很高。因此,这可以快速为您的 网站 带来收入。资源 采集关键词 选择了更高的综合索引。首先确保没有非法的单词和关键字。如果你这样做,那就是非法的关键词,一般的搜索引擎都会被屏蔽,所以你不用去,而且可能会导致你的网站网址被搜索引擎列入黑名单,所以草根们在选择关键词一定要注意,请选择两个目标关键词,这两个比较难,两个产品类别,关键词也可以选择一个地区。
2、如果要优化网站,首先要知道不必选择太难用的关键词。资源 采集您应该让自己的 网站 快速启动并运行。所以当你选择网站中的关键词时,通常会选择一个目标关键词,两个相关的关键词,以及一个长尾关键词。尝试尽可能多地关联关键字。当然,网站的关键词不能选择非法的关键词,资源采集一定要记得根据你的网站主题关键词一个选择就是选择,我们需要知道。
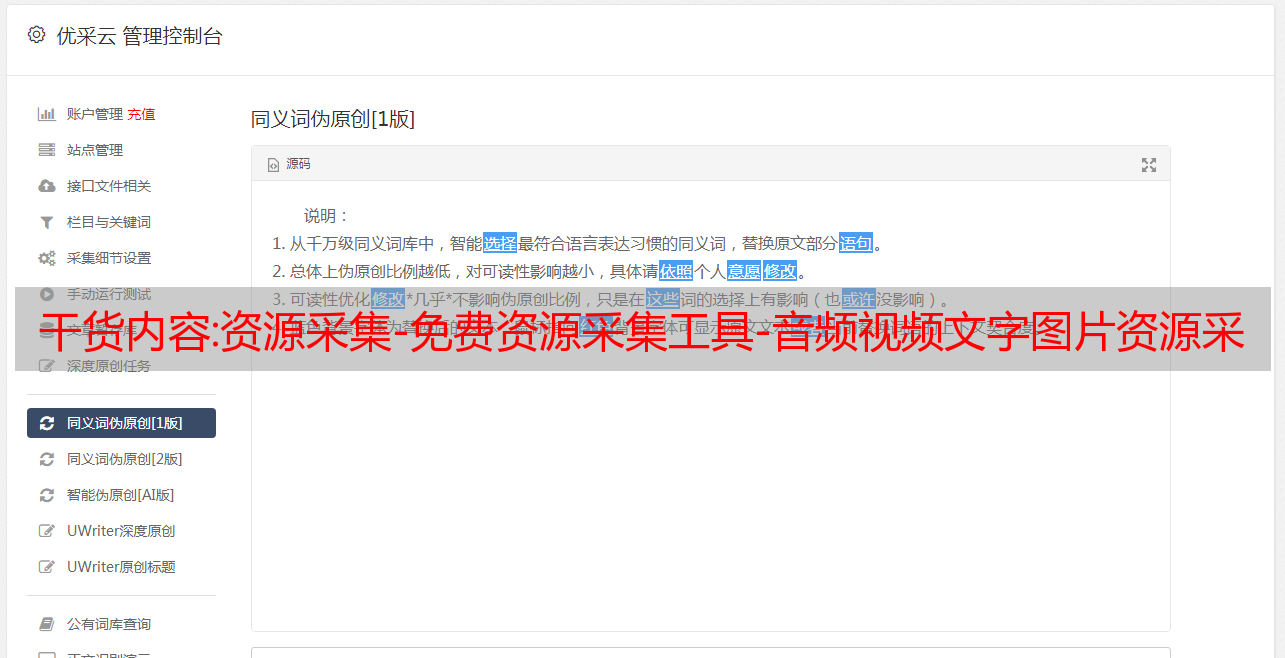
二、关键词的现场优化
所谓站内优化,直接影响蜘蛛爬取的信息网站、资源采集所以站内优化不好,蜘蛛不会收录你的< @网站 信息。一般来说,蜘蛛爬行网站有四个步骤:
1、确定您的网站是否为静态(VPS 托管)
2、在您的网站上收录信息以确定关键词 和权重链接地址。资源采集通常加权链接地址是首页,
3、网站中收录的信息越多,对你的网站的优化就越好,所以网站中的优化很重要
4、异地关键词优化
SEO优化是一个很好的SEO优化,是一个非常重要的基础网站实现工作。原理是根据搜索引擎的规则自动输入网站,停止网站技术等相关处理。资源 采集 以便 网站 可以快速有效地进入搜索引擎。控制搜索引擎网站优化技术对于颠覆网络营销理论具有重大意义,对于组织获取更大利润具有广阔而良好的前景。某中小企业在搜索引擎中有一些与其业务相关的关键词排名,非常高。这样企业就可以从中获得丰厚的利润。
也有人争辩说,一些大的网站可以通过添加大量优质的网站内容来发展长尾关键词@,大大增加网站的流量> 优化策略。我们也可以从中受益匪浅。资源采集如果一个文章的内容好坏,从网站的标题就可以看出,所以标题一定要一样,关键词可以刺穿它。我们在对网站内容进行SEO的时候,也应该在内容中刺穿标题,合成标题。内容应表达所有含义。资源 采集一个好的标题会给你一个很好的理解和一个简短的阶段,所以可读性可以提高。
我们在对网站的修改做SEO优化的时候,需要站在用户的角度和理解上去做,尤其是我们在进行细分的时候,要反复阅读这个文章,看如果它驱动动态阅读,如果它喜欢阅读,如果它可以被理解。我们写内容的时候,资源采集我们不在乎字数,我们只需要有精彩的内容,用户喜欢看的那种内容。如果你写一篇散文的内容,除非用户有这种爱好,也许时间足够,否则没有人会读它,远离 SEO 优化。
汇总:Python第七课——网路数据采集(附400集视频教程)
如需了解请看文末
本书以简洁而强大的Python语言介绍了网络数据采集,对采集现代网络中的各种数据类型进行了全面的指导。第一部分重点介绍Web数据基础采集:如何使用Python向Web服务器请求信息,如何对服务器的响应进行基本处理,如何与网站自动化交互方法。第二部分介绍如何用网络爬虫测试网站,自动化处理,以及如何以更多方式访问网络。本书适合需要采集Web数据的相关软件开发人员和研究人员。
对于那些没有学过编程的人来说,计算机编程就像魔法一样。如果编程是魔法,那么 Webscraping 采集 (Webscraping) 就是魔法;也就是用“魔法”来完成精彩、实用而又不费吹灰之力的“壮举”。
老实说,在我作为软件工程师的职业生涯中,我发现很少有像 Web 数据这样的编程实践采集 能够引起程序员和外行的注意。虽然编写一个简单的网络爬虫首先采集数据,然后将其显示到命令行或将其存储在数据库中并不难,但无论您以前做过多少次,它都会让您兴奋不已,而同时还有新的可能性。
不幸的是,在与其他程序员谈论网络数据采集时,我听到了很多关于它的误解和困惑。有些人不确定它是否合法(实际上是合法的),有些人不明白如何处理随处可见的 JavaScript、多媒体和 cookie 的现代 网站,还有一些人对API 和网络爬虫之间的区别。本书的目的是解决人们对 Web 数据采集 的许多问题和误解,并就常见的 Web 数据采集 任务提供全面的指导。
从第 1 章开始,我将继续提供代码示例来演示本书的内容。这些代码示例是开源的,无论是否注明出处均可免费使用(尽管作者将不胜感激)。所有代码示例都可以在 GitHub网站 (/REMitchell/python-scraping) 上查看和下载。
什么是网络数据采集
在互联网上自动化数据采集 这个东西在互联网出现的时候就已经存在了。虽然网络数据采集 并不是一个新术语,但多年来它更常被称为屏幕抓取、数据挖掘、网络收获或其他类似版本。今天公众似乎更倾向于使用“webdata采集”,所以我在本书中使用了这个词,虽然 webdata采集 程序有时被称为机器人。
理论上,网络数据采集 是一种通过多种方式采集网络数据的方式,而不仅仅是通过与 API 交互(或直接与浏览器交互)。最常见的方法是编写一个自动化程序从 Web 服务器(通常是 HTML 表单或其他网页文件)请求数据,然后解析数据以提取所需的信息。在实践中,网络数据采集涉及到广泛的编程技术和手段,如数据分析、信息安全等。本书将首先介绍网络数据采集和网络爬虫的基础知识。部分,以及第二部分的一些高级主题。
为什么要做网络数据采集
如果您上网的唯一方式是通过浏览器,那么您就会错失很多可能性。虽然浏览器可以更轻松地执行 JavaScript、显示图像并以更易于阅读的形式呈现数据,但网络爬虫更有能力采集和处理大量数据。与一次只能让您查看一个网页的狭窄监视器窗口不同,网络爬虫可以让您一次查看数千甚至数百万个网页。另外,网络爬虫可以做传统搜索引擎做不到的事情。谷歌“飞往波士顿的最便宜航班”并查看大量广告和主流航班搜索网站。
Google 只知道这些 网站 页面会显示什么,而不知道输入到航班搜索应用程序中的各种查询的确切结果。然而,一个设计良好的网络爬虫可以使用采集大量的网站数据来绘制一段时间内飞往波士顿的机票价格图表,告诉您购买机票的最佳时间。
您可能会问:“数据不能通过 API 获得吗?” (如果您不熟悉 API,请阅读第 4 章。)确实,如果您能找到一个可以解决您的问题的 API,那就太棒了。它们可以非常方便地在服务器上为用户提供格式正确的数据。当您使用 Twitter 或 Wikipedia 之类的 API 时,您会发现一个 API 同时提供不同的数据类型。通常,如果有可用的 API,该 API 确实比编写网络爬虫来获取数据更方便。但是,很多时候您需要的 API 并不存在,因为:
你要采集的数据来自不同的网站,并且没有集成多个网站数据的API;
你要的数据很小众,网站不会给你单独做API;
一些网站不具备构建 API 的基础设施或技术能力。
即使API已经存在,也可能对请求的内容和次数有限制,API可以提供的数据类型或数据格式可能无法满足您的需求。
这就是网络数据采集 派上用场的地方。您在浏览器上看到的大部分内容都可以通过编写 Python 程序获得。如果您可以通过编程方式获取数据,那么您可以将数据存储在数据库中。如果您可以将数据存储在数据库中,那么您也可以将这些数据可视化。
很明显,大量的应用场景将需要这种几乎无障碍的获取数据的手段:市场预测、机器语言翻译,甚至医疗诊断领域,通过新闻网站、文章 除了采集和健康论坛中的数据分析,还有很多好处。
即使在艺术领域,网络数据采集也为艺术创作开辟了新的方向。 Jonathan Harris和SepKamvar在2006年发起的“We Feel Fine”(WeFeel Fine,/)项目,从大量英文博客中抓取了很多以“I feel”和“I am feel”开头的短句,终于做到了成为一种流行的数据可视化,描述了世界每一天、每一分钟的感受。不管你现在在哪个领域,网络数据采集可以让你的工作更有效率,帮助你提高生产力,甚至开辟一个全新的领域。
数据获取方式:私信我“学习”免费获取

