新闻源网站内容采集的两种方式和操作模式!!
优采云 发布时间: 2022-09-20 11:19新闻源网站内容采集的两种方式和操作模式!!
网站内容采集的两种方式:一是把新闻源网站内容抓取到自己网站,二是把自己网站内容抓取到新闻源网站。从搜索引擎抓取信息的方式来看,有多种。大概分为:被动式,主动式,自动式,直接抓取式。这里说下被动抓取式,简单说就是采集系统主动将网站内容抓取。简单介绍下这种的操作模式:网站内容抓取,首先根据网站的内容构架选择自己网站内容想要用到的类型(标题,内容,intext),然后去新闻源网站采集,不过新闻源网站的采集是单向采集的,如果采集多了,会被谷歌判定为某些新闻源站,导致网站robots文件锁定。
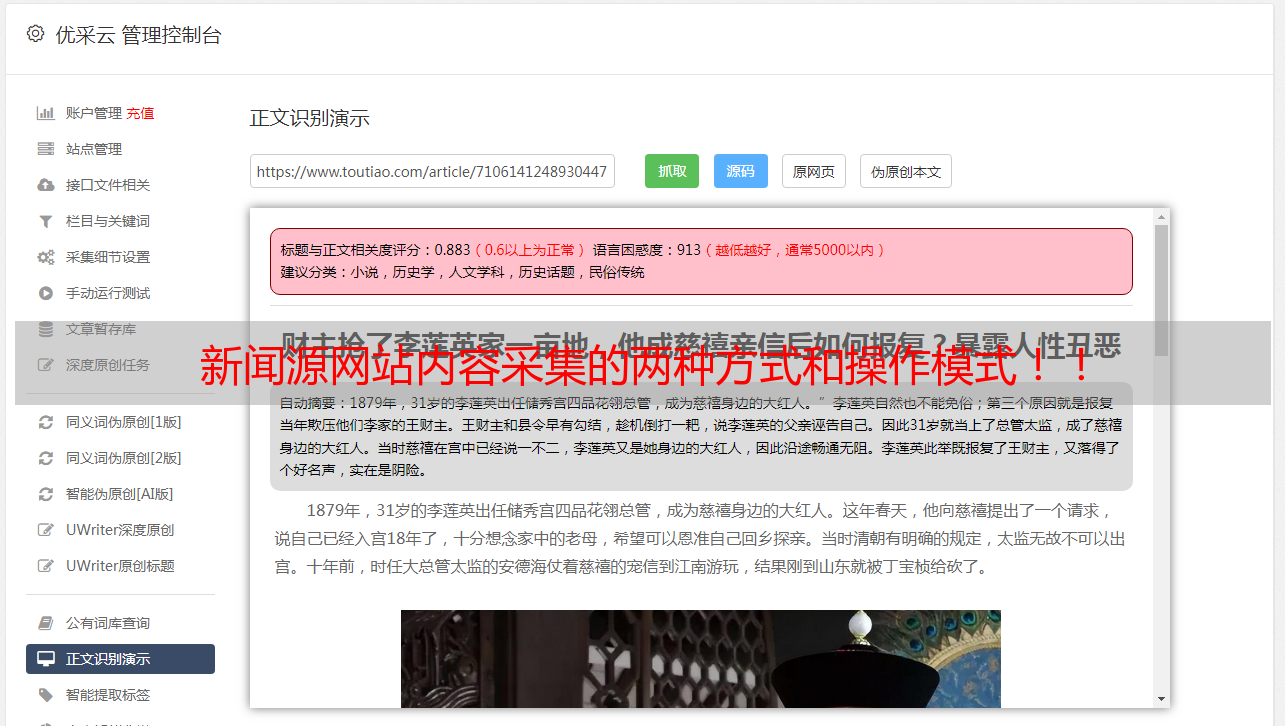
这里面还有几个问题:采集后的文本如何做处理?处理后的文本怎么导入数据库?数据库的数据应该放在哪里?一直有这个问题,直到去年11月我的想法突然有个变化,想明白怎么采集了(这里谈到是想到了写这篇文章)。我的想法如下:采集新闻源站点后,先不放数据库,而是直接发掘网站内容里面的tag。之前用了adwords和谷歌文章助手。
后来发现谷歌文章助手对我来说有点繁琐,而且文章助手界面有些小看不惯。于是开始尝试用自己的网站直接采集,这样就方便了。但不能用谷歌文章助手,因为谷歌文章助手对我来说,有点繁琐,而且文章助手界面有些小看不惯。直到我开始学了seo之后,决定去学习seo。于是决定自己去慢慢学习新闻源站点的抓取。学习过程中,我有一个本能认识:新闻源网站站内的内容数量比较多,且大多数不用改动,基本上都可以用。
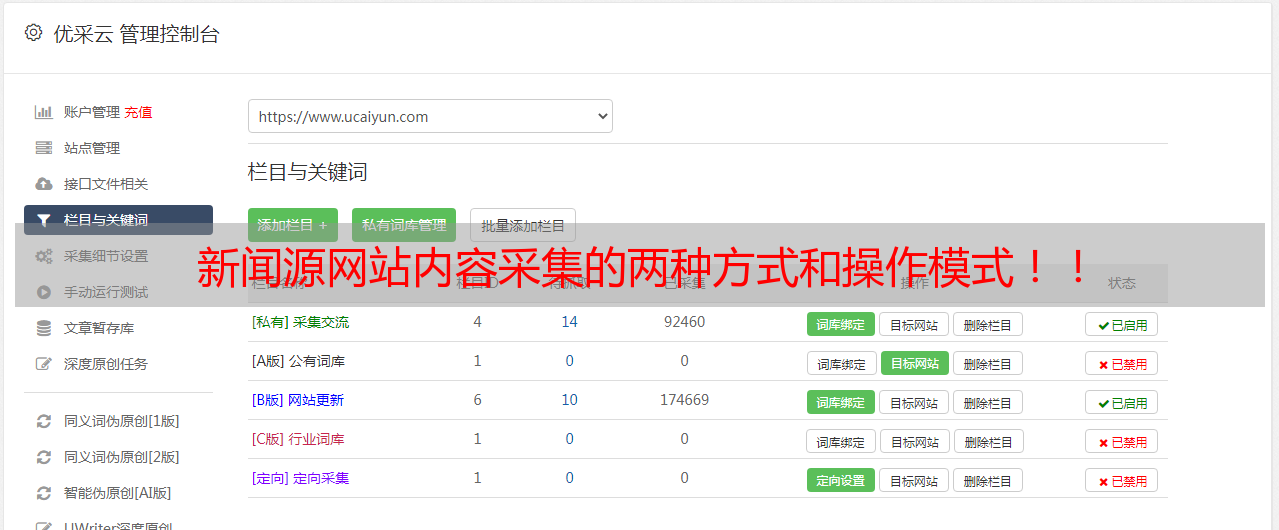
新闻源网站内容抓取一个很简单的事情,先找到任何一个新闻源网站先抓取下来,再对分词,根据partial的auto去调整robots.txt文件。tag抓取的方式,可以学习上文中提到的爬虫,自己写个爬虫,把自己网站里面的内容抓取进来,再做去重处理。处理分词:基本上没什么难度,就是不知道结果是否一致。自己写过爬虫也有很多个,这里记下自己总结的分词技巧。
先看看要抓取的网站大概有哪些分词组成,根据网站构成的分词组成,再看看新闻源网站,属于哪一类的网站,通过网站构成,再看新闻源网站的网站名字,得到大概这类网站的分词组成,之后分词,达到最终目的。比如“快递”这个词,想抓取到第一个新闻源网站是某个快递站点。再比如“机关”这个词,想抓取到第一个新闻源网站是某个机关。
根据我对你们公司的了解,这类一般的网站都有自己的分词工具,网上就有,其实很简单。我这里推荐两个我自己用过的工具,一个是百度新闻源分词,一个是jieba。百度新闻源分词:直接解析网站新闻,可以在线提交。jieba:我常用工具,分词效果比百度新闻源分词好一些。

