网页正文爬取方法需要做几个准备,请求获取时间url
优采云 发布时间: 2022-08-21 09:00网页正文爬取方法需要做几个准备,请求获取时间url
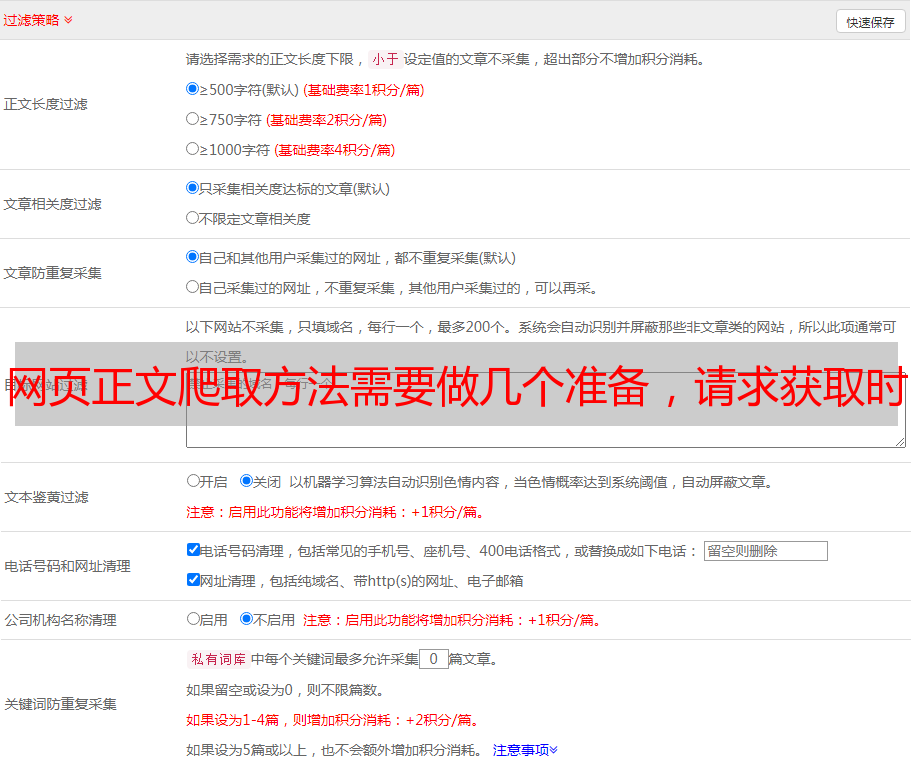
php网页抓取标题提取正文前端数据抓取。请求获取时间url,去查询每个不同页码对应对应的url。正文解析我们查看一下正文的内容和,将网页正文的内容解析成对应我们需要抓取的正文数据。有了网页正文的信息,我们就可以爬取数据,我们接下来了一个步骤就是查看网页正文抓取方法。我们要发现网页正文爬取方法需要做几个准备,首先需要先下载相应的网页正文。
首先是网页正文爬取在我们在浏览器上发现的通常有三种抓取方法。分别是轮子哥推荐的urllib2抓取方法,for循环抓取方法,cookie抓取方法。一,urllib2抓取方法,网址页面查询解析方法,先下载相应网页正文代码,例如;data=;data=;data=;url_login=;data=;html=;data=;二,for循环抓取方法,包括子代码循环跟二号循环。1,子代码循环父代码循环一致,步骤如下:。
1)创建工程copy;
2)首先新建工程yaml4_python,写一个container.py。然后写一个response.py,将爬取到的内容post到父index.py中。
3)父代码循环
1)创建工程python_parse,下载网页内容,注意的是安装urllib2,for循环爬取的内容必须放在这里,
4)父代码循环
2)创建一个index.py脚本,包括网页正文爬取方法以及二号循环使用。2,cookie抓取方法cookie抓取方法是ecshop、wordpress、eventlet中在后台cookie抓取,利用cookie机制爬取对应的内容,再次wordpress中做的同样的事情。cookie抓取方法如下图:首先是cookie抓取方法,从这个页面的一个网页内容,然后点一下cookie抓取按钮,这个页面里面就会抓取到这个网页正文部分的内容,包括页面的浏览记录,已经js,xml文件等内容(前提得是https抓取的网页),firefox等浏览器可以发现抓取记录直接作为https握手成功的一种标志。firefox抓取方法和chrome抓取方法基本上一致。
总结:网页正文爬取一共有三种抓取方法
1)轮子哥推荐的urllib2方法,cookie抓取方法(在同一个页面内下,多个页面间),
2)for循环抓取方法(子代码循环同上),cookie抓取方法(发现cookie,js等内容,
3)cookie抓取方法,二代码循环。

