小白怎么学习采集网页文章获取爬虫前端页面(组图)
优采云 发布时间: 2022-08-11 10:05小白怎么学习采集网页文章获取爬虫前端页面(组图)
文章自动采集和发布入口:【小白学爬虫】小白怎么学习采集网页文章,获取爬虫前端页面(很多采集软件都是采集网页页面,比如beautifulsoup.),然后配合爬虫工具如脚本宝典,采集软件来写脚本。网页中全是图片的话,chrome浏览器自带的“chrome浏览器插件工具”中有个“用户脚本中心”,就可以进行设置对图片爬虫。
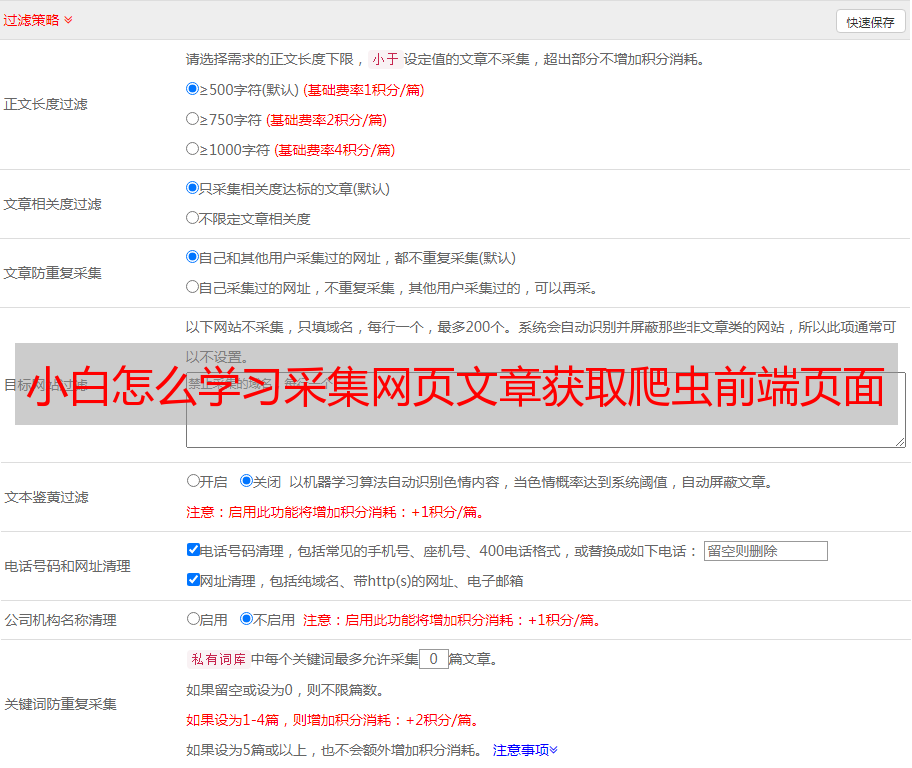
下面是采集常用的几个网站的网页页面(以图片采集为例):image,media,journalpageongoogle.img,journalpageongoogle.url:图片都是由图片代码组成的,我们首先从网页发现图片上传是url编码,我们需要利用chrome浏览器插件来解码网页的url编码,然后使用fiddler进行抓包,就可以看到一个如下的采集记录图。
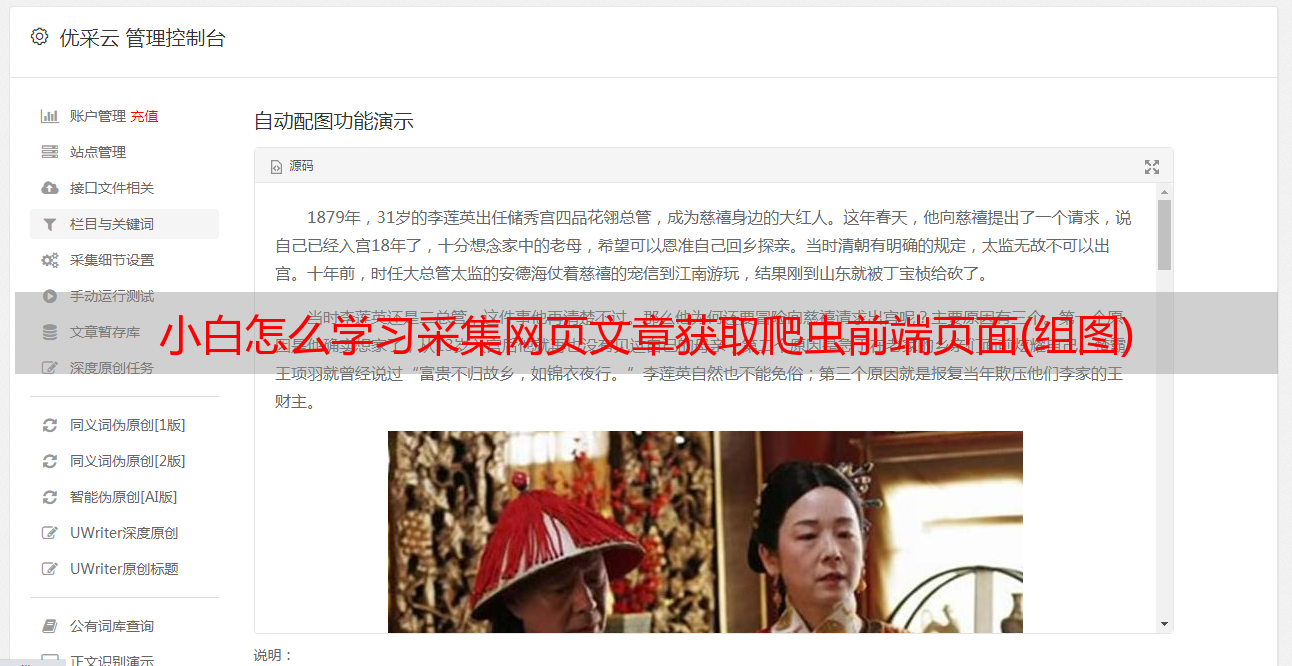
requestpageviewformat:encodingmatrixtype:jpegretrieve:"/uploads/image_jpeg.png"movementurl:"/path/to/image_jpeg.jpg"name:"post"postaccept:image/jpeg,mode:image/jpeg,accept-encoding:encoding这里采集图片上传,使用的正则匹配规则是正则匹配图片下载之前的img,如下图:解码规则为:request:method"post"retrieve:"/uploads/image_jpeg.jpg"width:1000height:300border-bottom:1dashboard:generaldatapath:\travel\tag_signature\gmail.dz\jpg\signature\gmail.dk\jpg"这样查看就知道是图片地址,然后就是采集下载的代码。
从规则可以看出,大部分是gmail名称或昵称。我们把上传图片的url通过fiddler抓包来看看。然后我们打开浏览器网页来看看效果。就知道图片上传是url编码,上传的地址是一个img:/.jpg;r=ul_jqufas8ef7h5qbzss0dvwduzz-x3gk-rwbtpzg-vtem812-jswtjdl1im%2bb4uz1fpyfnhla3p%2ccqqg_a7s63i8hfirzt2x4ujklm.cp2%2ccza0bugxjknryjgz0bnd%2ckel+x95btmv-gxyjw79znd4x8wduzsgz1xvdd%2bbovzfla1cd80b1t5nqzh8qqt0gu3vq3byegfcacbapjhp8jyz-vjkxzv4jh2io0yfpjtfv5h%2ddku5ynrc1ajvaqhxmw6eb++jxjkyieyi1cyypchazmh0nwha2tze0krzt%2fjjnd8bbuqwvrwdj8fasj6hexgn3mejcvj1j50yvz2z&v=5/lib/win32/forms/sogou.dll/ocrbaltuzzy.forms就知道图片上传是fiddler配合爬。

