java入门网java自学大全之爬虫抓取网页数据要经过服务器
优采云 发布时间: 2022-07-27 23:00java入门网java自学大全之爬虫抓取网页数据要经过服务器
爬虫抓取网页数据要经过服务器的,当然有可能存在数据丢失或者丢失个别信息。云平台对数据抓取有一定的数据限制,可以根据需要上传数据。
要有跟数据库的连接,才可以把数据导入到数据库的,最简单的话可以自己用线连接一下,线连接需要了解下数据库方面的知识,推荐java入门网java自学大全,根据网上的教程能够最快把数据库,操作系统,方便操作,最简单地是用阿里云服务器,其实也可以的,也可以在学校内置买一台,个人建议大学毕业前一定把数据库弄懂,对以后会很有帮助的。
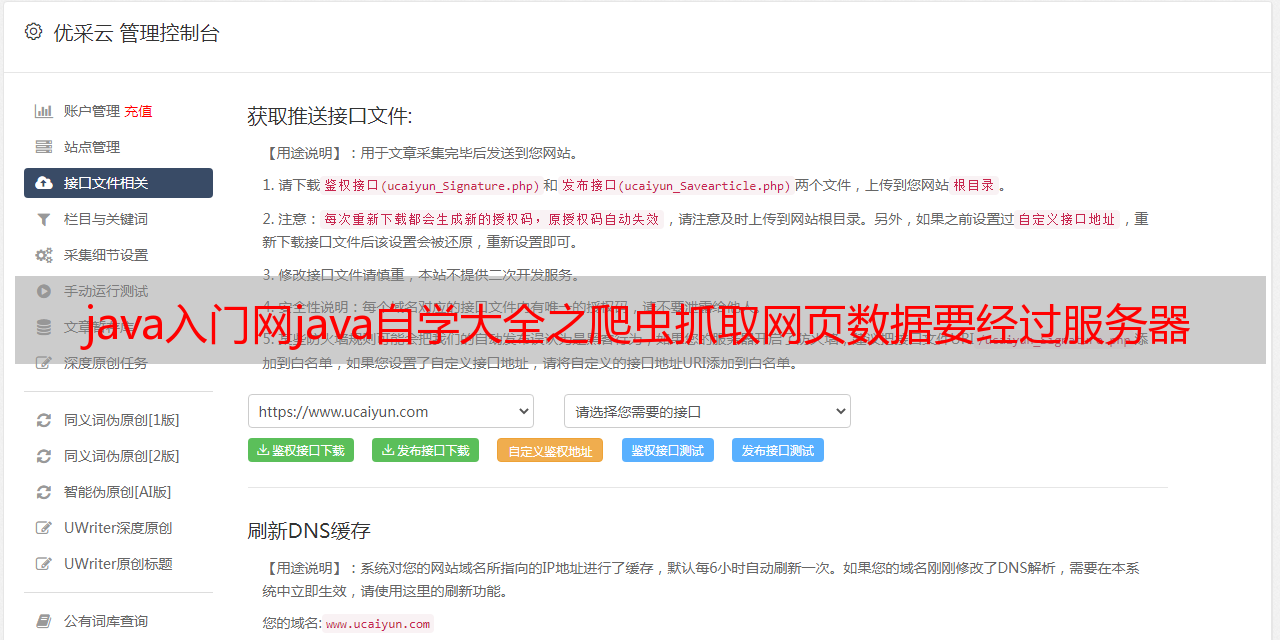
这是云平台接入接口的规则。
不晓得你所说的是线上监控还是线下的。如果是线上监控是可以的,我所了解的做的好的线上监控基本都是redis集群,内存数据库。
你可以从一开始就用个codis之类的集群。可以在读取时一起从集群读取/查询的,你可以快速加入到应用中。
数据监控分中小企业和大企业,针对小企业,使用pymysql非常普遍了,如果是想了解实时性要求高的应用,可以上ps。ps有个短连接的监控,你可以看看。线下很多公司是用redis的,当然mysql也是可以的,有专门的监控,分三类。
1、sharedpoints:实时不限制时间
2、conditionalsocket:实时不限制时间
3、dynamicsocket:实时不限制时间仅供参考

