网页抓取数据的话,我们大致可以分为下面三种
优采云 发布时间: 2022-07-18 01:07网页抓取数据的话,我们大致可以分为下面三种
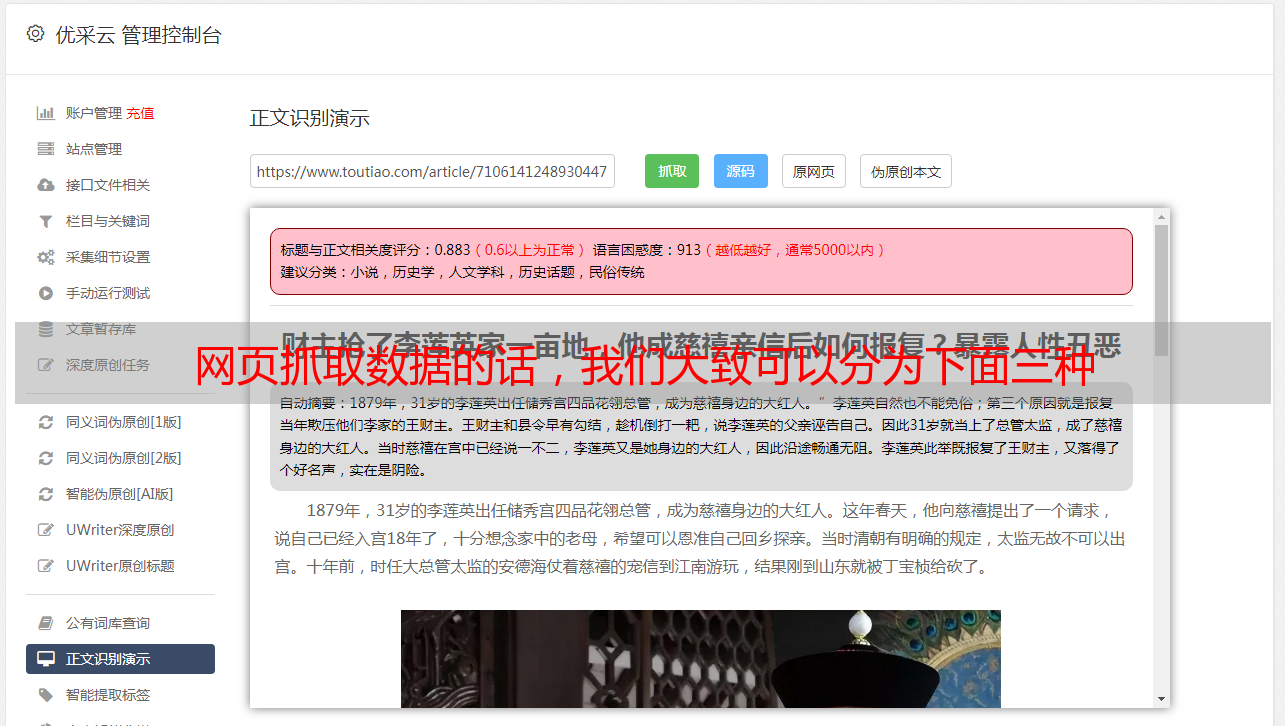
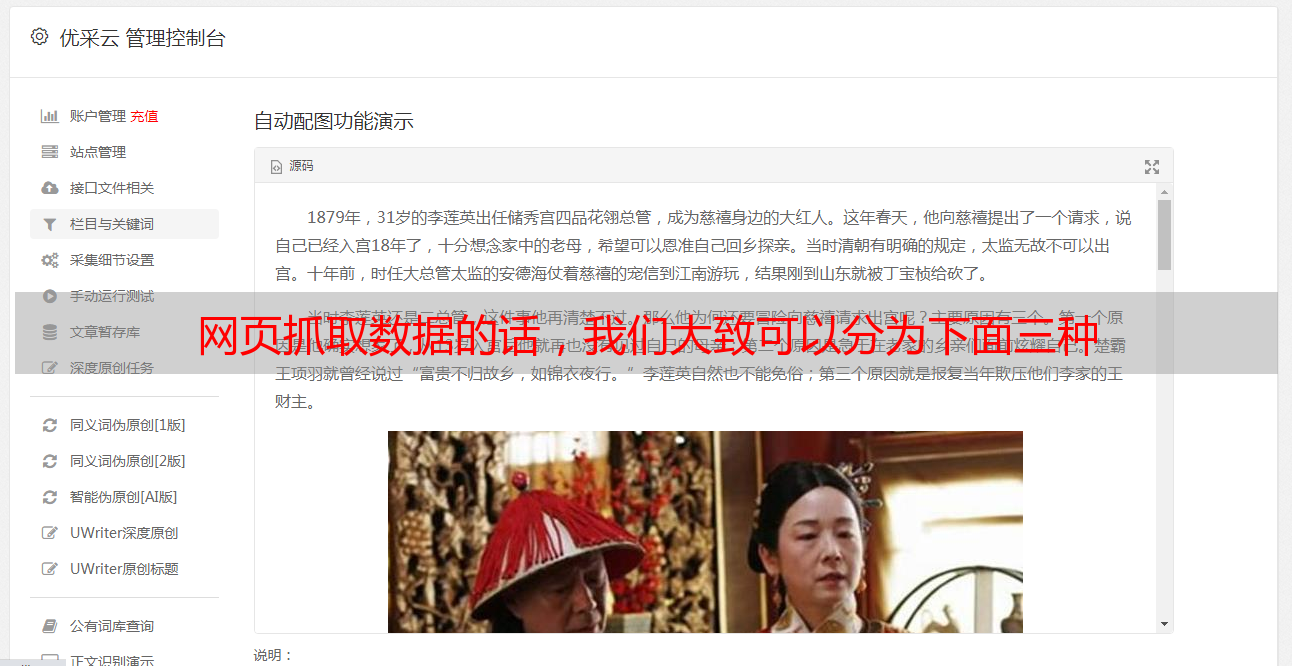
网页抓取数据的话,我们大致可以分为下面三种:1.网页端抓取,也就是用浏览器抓取下来后,保存到html文件2.浏览器端抓取-拼接抓取到数据,并且预览到网页端(firefox)3.浏览器端抓取-将抓取的数据发送到服务器,后台清洗,将无用信息去除,生成结构化的数据。第一步,推荐使用requests库,使用它最关键的是找到headers对象,也就是我们说的头部,在headers对象上找到"user-agent"对象,这个对象里有一个对象“headers":可以看到,每个请求头都会带上该headers对象,头部对象是不能更改的,所以用户可以很方便的决定请求内容:例如"post"请求提交了什么信息,"put"提交了什么信息,"data"将转换数据,"pat"将接受数据,"post-cookie"代表接受用户提交的信息。
这里解释一下用户提交信息、接受到的数据、转换后的数据是如何保存在电脑本地的。例如:post提交信息→我们的html页面→浏览器查看→查看数据结构→保存信息→发送到服务器→服务器查看→接受数据→通过一个get方法向数据库发送请求→...第二步,推荐postman。1.这个程序大致不需要任何编程知识,只需要会基本的http请求,请求headers等即可。
2.它可以通过编写headers对象,处理请求,并且有一个很好的单元测试,例如它可以生成http2和http1类型的所有的请求信息。3.最好的是当你会html语言,例如xmlhttprequest。第三步,重点讲解web服务器端的处理和分析。1.http方面,当你用postman提交了你的请求,服务器需要清除所有请求,只保留headers对象,并且调用reset()方法,把headers对象中的一些规则清除掉,包括headers的头部内容(包括user-agent这些值)。
这些headers通常包括:cookie-web登录或注册的用户的登录表单上的一些内容(我们拿出来进行简单的说明)2.浏览器方面,大致如下:在浏览器上可以打开和修改http3的浏览器(如user-agent网站进行安全验证,也叫referer),浏览器通过这些http3的浏览器对服务器进行请求,从服务器拿到结构化数据(参考@董潘大神在数据的真相@rednaxelafx答案)。
在浏览器上可以修改http4的浏览器(referer),浏览器通过这些http4的浏览器对服务器进行请求,拿到结构化数据。3.在后台方面,大致如下:在后台使用res.cookie,把http3的headers对象转换为cookie值,再用于请求服务器,从而拿到cookie值,放在服务器存储。4.数据库方面,可以在oracle,mysql等数据库上引入相应的功能,用于规划用户请求与数据库间的交互。

