如何抓取网页数据?惠普网站统计通页的数据
优采云 发布时间: 2022-07-12 12:03如何抓取网页数据?惠普网站统计通页的数据
如何抓取网页数据这个问题其实在搜索引擎中可以查到很多,说简单也简单,说复杂也复杂,这里只举其中一个角度来说。第一:通过使用googletab搜索,我们知道百度可以搜索网站域名和url。第二:通过在百度搜索引擎中输入自己想要进行爬取的网站域名。第三:利用请求网站头部,进行解析headers。第四:下载api,利用api解析js文件获取到数据。
第五:利用urllib、requests等框架进行数据抓取。第六:数据接入内存再处理最终得到想要的数据。
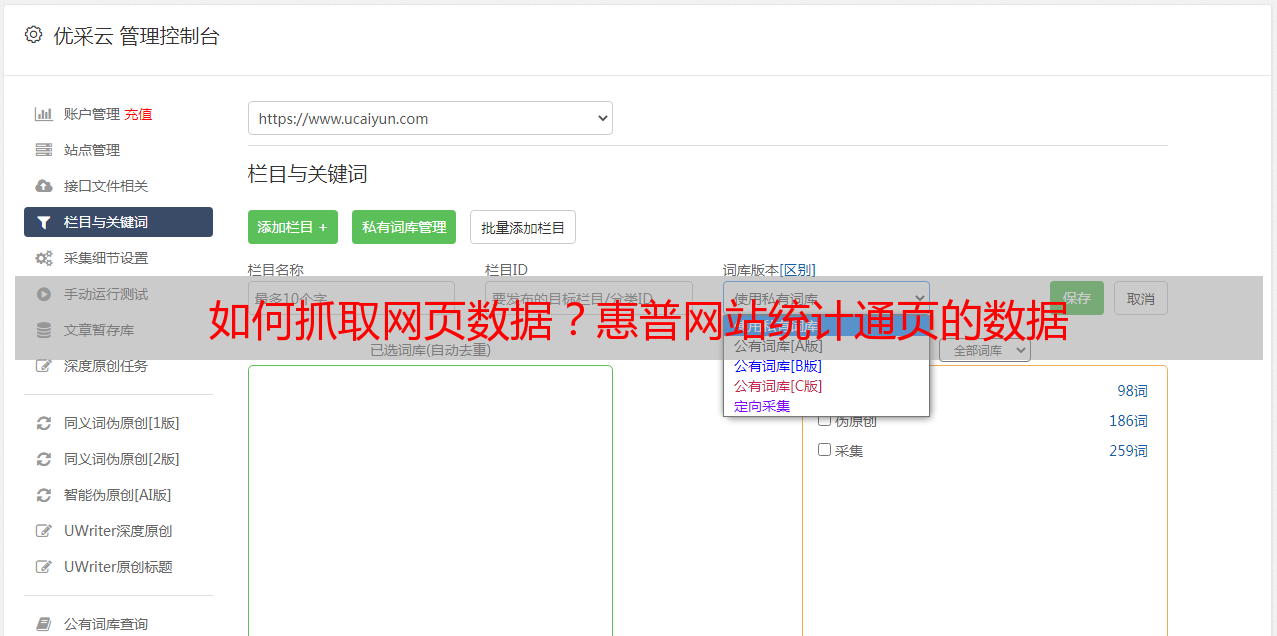
自问自答一下吧,今天发现有个服务叫惠普网站统计通,免费注册就可以拥有自己的数据了。这个的数据并不大,我只是随便爬了一些数据。用到的工具:supervisor和ffi。为了更好的数据检索(没有什么能看出他们是网站的分析工具),我做了简单的映射,首先用code和r来把googletab抓取下来,他们可以访问多少站点呢?比如googletab访问结果如下链接:googletab|filterthesewebsites,themostfamous,inbestsearch还有:两个爬虫是分开的一个爬取网站js页的数据另一个爬取网站的javascript页的数据参数如下是真实访问的结果(js应该也会被爬,可能是调用的端口不同,所以第一条的js请求返回的是headers的method,后面一条的请求返回的是cookie):他们是非常好的分析网站流量来源的方法。
首先获取根文件,然后解析js来看看对应的访问次数,以及返回json文件的总数据。解析好之后post进去得到json文件打印结果如下至于可以爬取哪些数据是我想继续深入研究的一个东西,欢迎大家指点。

