优采云文章采集api仅支持网页内文章的检索收录及下载
优采云 发布时间: 2022-07-11 23:02优采云文章采集api仅支持网页内文章的检索收录及下载
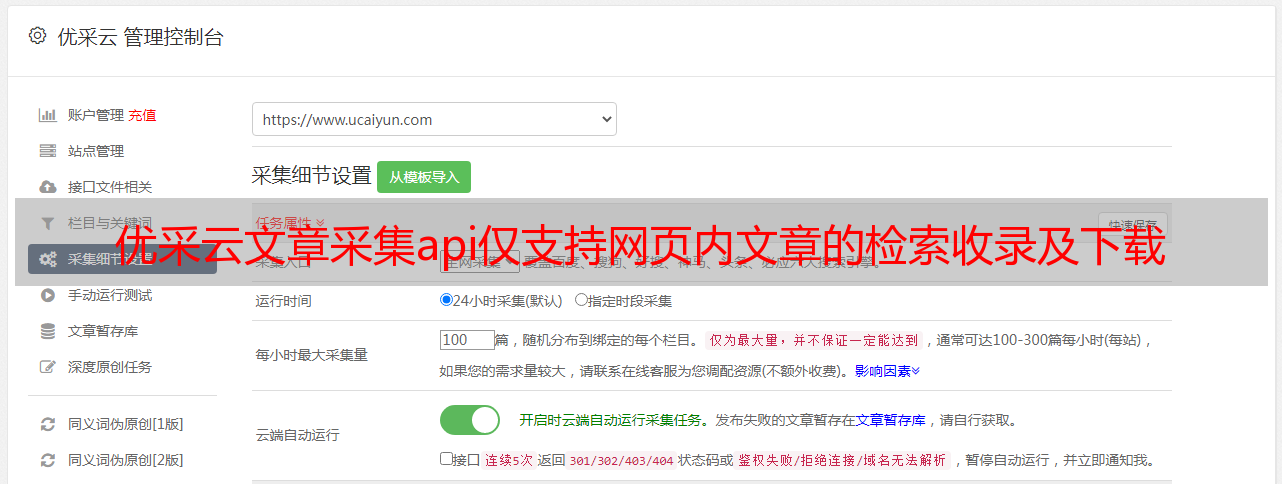
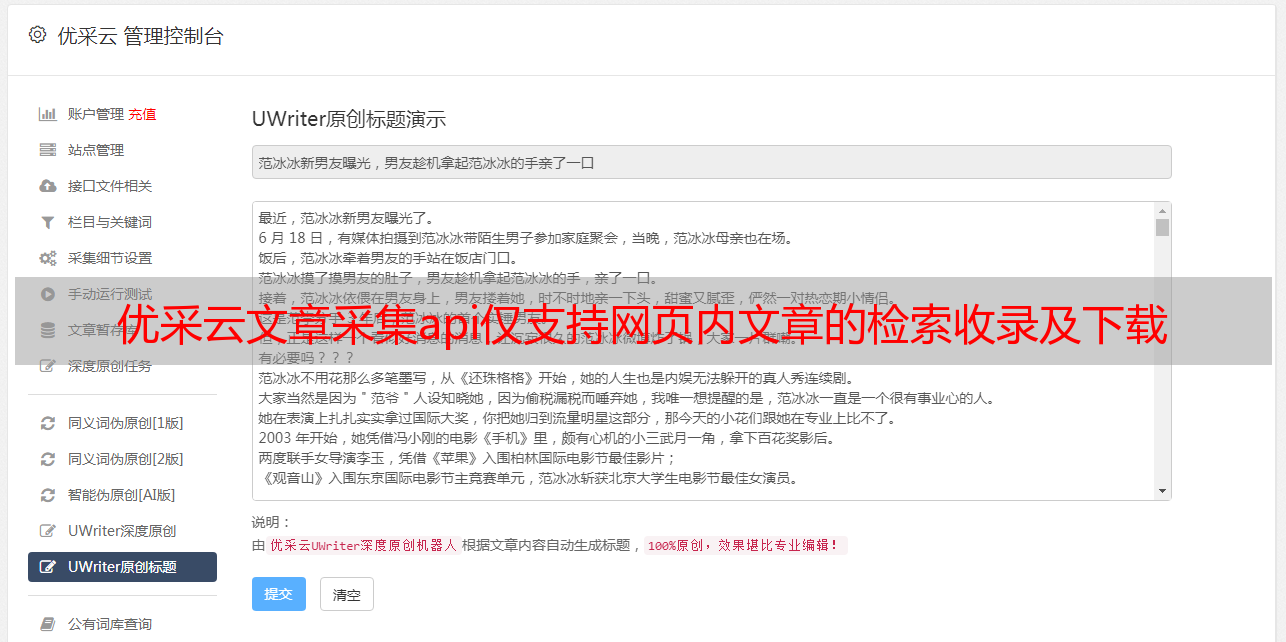
优采云文章采集api,仅支持网页内文章的检索收录及下载,文章采集可以自定义检索范围,支持多种用户注册方式,欢迎大家使用。
我目前做的是全网网页爬虫,一般都用requests+beautifulsoup,
找对网站了...
看了一圈,基本上抓取都是使用selenium+beautifulsoup,后台url转换看看对应的规则是否复用。
基本方法都是放代理,自己手动加代理,少数写爬虫代理池(一年也能开销两三万的),
爬虫基本上用requests+beautifulsoup或者phantomjs。另外还有selenium,nodejs,phantomjs等等。有要自己抓去百度的,手动爬去twitter也可以用以上几种。
selenium+phantomjs+beautifulsoup。
难道不是自己编写爬虫吗?然后利用爬虫自动收集
用爬虫都还是比较慢的,一天抓20个页面都要一天,代理费自己掏,自己写爬虫比较慢但是绝对要快一点,
爬虫这东西还是要看网站资源的
现在直接抓twitter还是很麻烦,一般会抓取联合国和奥巴马的那些被抓取比较多。效率不高。但是现在有了把twitter抓去百度了的crawler,应该是最方便的,缺点是数据量不是很大,不然没啥效果。在论坛找的资料,

