SEO文章原创度检测
优采云 发布时间: 2022-06-04 05:46SEO文章原创度检测
过程:
1)先把一篇文章,按逗号分隔成一个一个短语
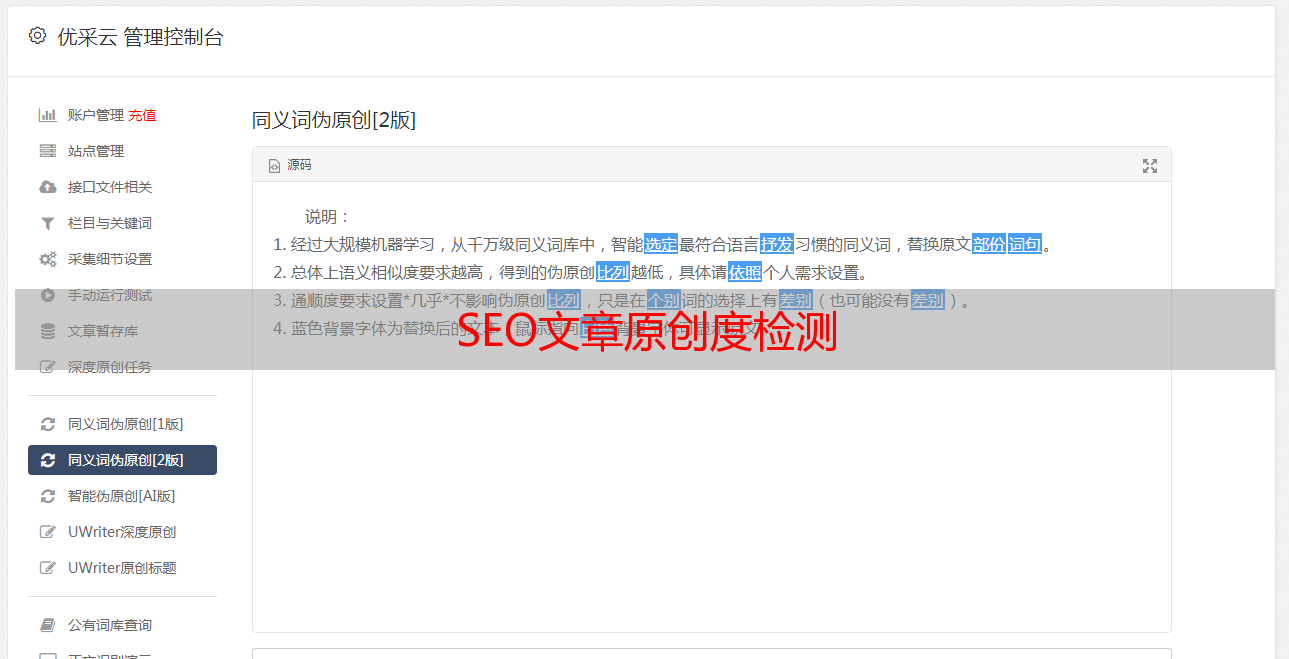
2)然后计算每个短语的字数

3)前两个>10个字的短语,我们拿出来在百度搜索下,计算百度搜索结果中,完整出现该短语的次数。
若一个文章被其他网站大量转载,那么随便提取该文章中一个短语,都能在百度搜索出完全重复的内容:
如果我们连续搜索两个短语,在百度搜索中,完全重复的结果很少,则可以一定程度代表该内容被其他站点大量转载的概率比较小,原创度较高
以上3个步骤,编写一个脚本来执行:
左列是文章ID,右列是两个短语,在百度搜索结果中完整出现的次数。次数越大,重复度越高,具体数值达到多少,自己定义。比如本渣一般将>=30%定位重复度比较高的,即搜索2个短语,20个搜索结果中,完整出现该短语的结果有>=6个
#coding:utf-8<br /><br />import requests,re,time,sys,json,datetime<br />import multiprocessing<br />import MySQLdb as mdb<br /><br />reload(sys)<br />sys.setdefaultencoding('utf-8')<br /><br />current_date = time.strftime('%Y-%m-%d',time.localtime(time.time()))<br /><br />def search(req,html):<br /> text = re.search(req,html)<br /> if text:<br /> data = text.group(1)<br /> else:<br /> data = 'no'<br /> return data<br /><br />def date(timeStamp):<br /> timeArray = time.localtime(timeStamp)<br /> otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)<br /> return otherStyleTime<br /><br />def getHTml(url):<br /><br /> host = search('^([^/]*?)/',re.sub(r'(https|http)://','',url))<br /><br /> headers = {<br /> "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",<br /> "Accept-Encoding":"gzip, deflate, sdch",<br /> "Accept-Language":"zh-CN,zh;q=0.8,en;q=0.6",<br /> "Cache-Control":"no-cache",<br /> "Connection":"keep-alive",<br /> #"Cookie":"",<br /> "Host":host,<br /> "Pragma":"no-cache",<br /> "Upgrade-Insecure-Requests":"1",<br /> "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36",<br /> }<br /><br /> # 代理服务器<br /> proxyHost = "proxy.abuyun.com"<br /> proxyPort = "9010"<br /><br /> # 代理隧道验证信息<br /> proxyUser = "XXXX"<br /> proxyPass = "XXXX"<br /><br /> proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {<br /> "host" : proxyHost,<br /> "port" : proxyPort,<br /> "user" : proxyUser,<br /> "pass" : proxyPass,<br /> }<br /><br /> proxies = {<br /> "http" : proxyMeta,<br /> "https" : proxyMeta,<br /> }<br /><br /> html = requests.get(url,headers=headers,timeout=30)<br /> # html = requests.get(url,headers=headers,timeout=30,proxies=proxies)<br /> code = html.encoding<br /> return html.content<br /><br /><br />def getContent(word):<br /><br /> pcurl = 'http://www.baidu.com/s?q=&tn=json&ct=2097152&si=&ie=utf-8&cl=3&wd=%s&rn=10' % word<br /> # print '@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ start crawl %s @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@' % pcurl<br /> html = getHTml(pcurl)<br /><br /> a = 0<br /> html_dict = json.loads(html)<br /> for tag in html_dict['feed']['entry']:<br /> if tag.has_key('title'):<br /> title = tag['title']<br /> url = tag['url']<br /> rank = tag['pn']<br /> time = date(tag['time'])<br /> abs = tag['abs']<br /><br /> if word in abs:<br /> a += 1<br /> return a<br /><br /><br />con = mdb.connect('127.0.0.1','root','','wddis',charset='utf8',unix_socket='/tmp/mysql.sock')<br />cur = con.cursor()<br />with con:<br /> cur.execute("select aid,content from pre_portal_article_content limit 10")<br /> numrows = int(cur.rowcount)<br /> for i in range(numrows):<br /> row = cur.fetchone()<br /><br /> aid = row[0]<br /> content = row[1]<br /> content_format = re.sub(']*?>','',content)<br /><br /> a = 0<br /> for z in [ x for x in content_format.split(',') if len(x)>10 ][:2]:<br /> a += getContent(z)<br /> print "%s --> %s" % (aid,a)<br /><br /><br /># words = open(wordfile).readlines()<br /># pool = multiprocessing.Pool(processes=10)<br /># for word in words:<br /> # word = word.strip()<br /> # pool.apply_async(getContent, (word,client ))<br /># pool.close()<br /># pool.join()<br />

