React 性能优化指南之性能分析与16种优化方法大总结
优采云 发布时间: 2022-05-04 01:21React 性能优化指南之性能分析与16种优化方法大总结
本文分为两个部分
1 如何分析 React性能2 16个React 性能优化方法1 性能 分析
进行任何性能优化的首先你要知道有哪些衡量的指标?其次找出存在的问题?然后才能针对性地进行优化。
1.1 性能分析指标有哪些
定性:加载性能、运行性能:滚动&更新
定量:
加载性能指标:reponseStart、domInteractive、DomContentLoadedEventEnd、loadEventStart、FCP FSP FMP TTI
运行性能指标:FPS 、 内存 CPU I/O 网络 磁盘
治理:采集、运维
1.2 性能分析的两个阶段分析阶段优化阶段
优化阶段我们针对分析阶段抛出的问题进行解决,下面简单列举下React 进行渲染性能优化的三个方向:
1.3 通过工具查看指标和度量1、 React Dev Tools & Redux Dev Tools
React v16.5 引入了新的 Profiler 功能,让分析组件渲染过程变得更加简单,而且可以很直观地查看哪些组件被渲染.
高亮更新
首先最简单也是最方便的判断组件是否被重新渲染的方式是“高亮更新(Hightlight Updates)”,通过高亮更新,基本上可以确定哪些组件被重新渲染。
设置方式如下:
例如合理使用了React.memo的列表组件比不使用,性能更好,“纯组件”是 React 优化的第一张牌, 也是最有效的一张牌。
分析器
如果高亮更新无法满足你的需求,比如你需要知道具体哪些组件被渲染、渲染消耗多少时间、进行了多少次的提交(渲染)等等, 这时候就需要用到分析器了.
来了解一下 Profiler 面板的基本结构:
1、 commit 列表
commit 列表表示录制期间发生的 commit(可以认为是渲染) 操作,要理解 commit 的意思还需要了解 React 渲染的基本原理。在 v16 后 React 组件渲染会分为两个阶段,即 render 和 commit 阶段。
2、选择其他图形展示形式
例如Ranked 视图,这个视图按照渲染消耗时间对组件进行排序:
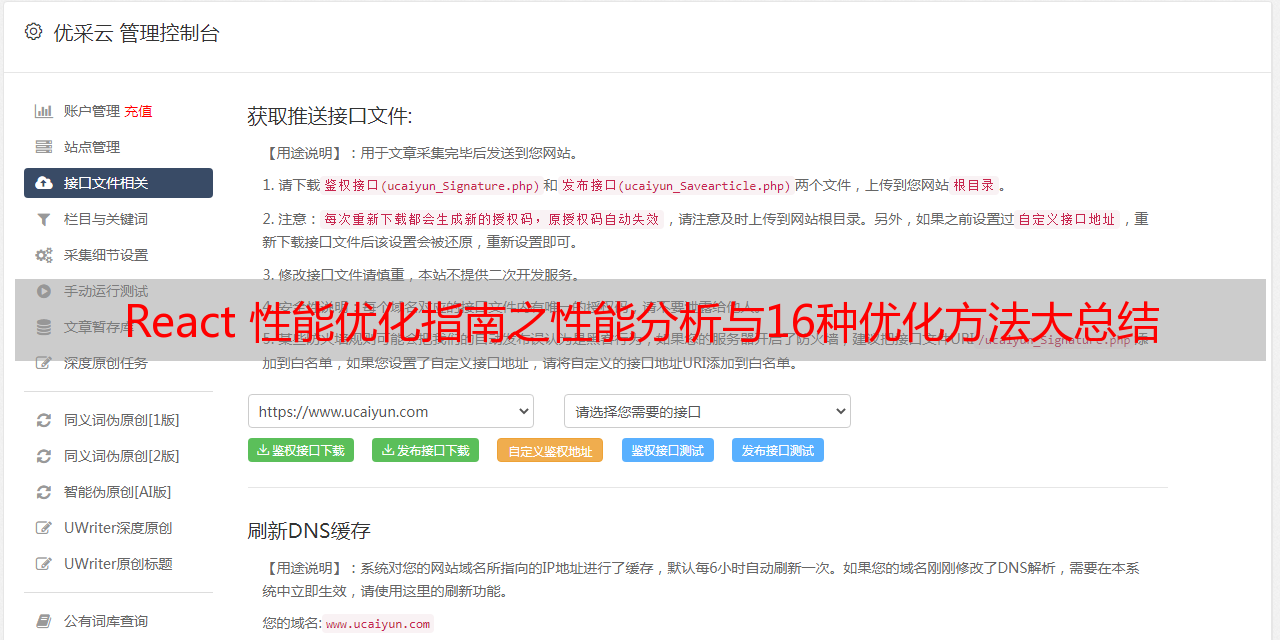
3、火焰图
这个图其实就是组件树,Profiler 使用颜色来标记哪些组件被重新渲染。和 commit 列表以及 Ranked 图一样,颜色在这里是有意义的,比如灰色表示没有重新渲染;从渲染消耗的时间上看的话: 黑色 > *敏*感*词* > 蓝色, 通过 Ranked 图可以直观感受到不同颜色之间的意义
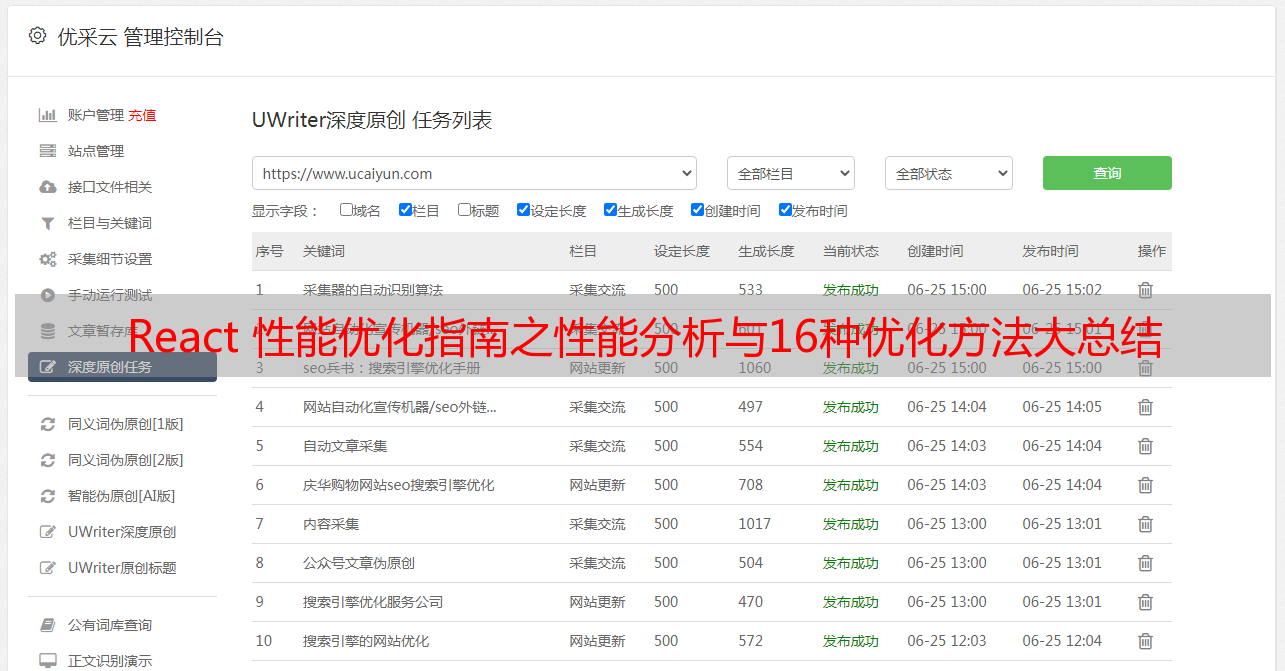
4、另外可以通过设置,筛选 Commit,以及是否显示原生元素:
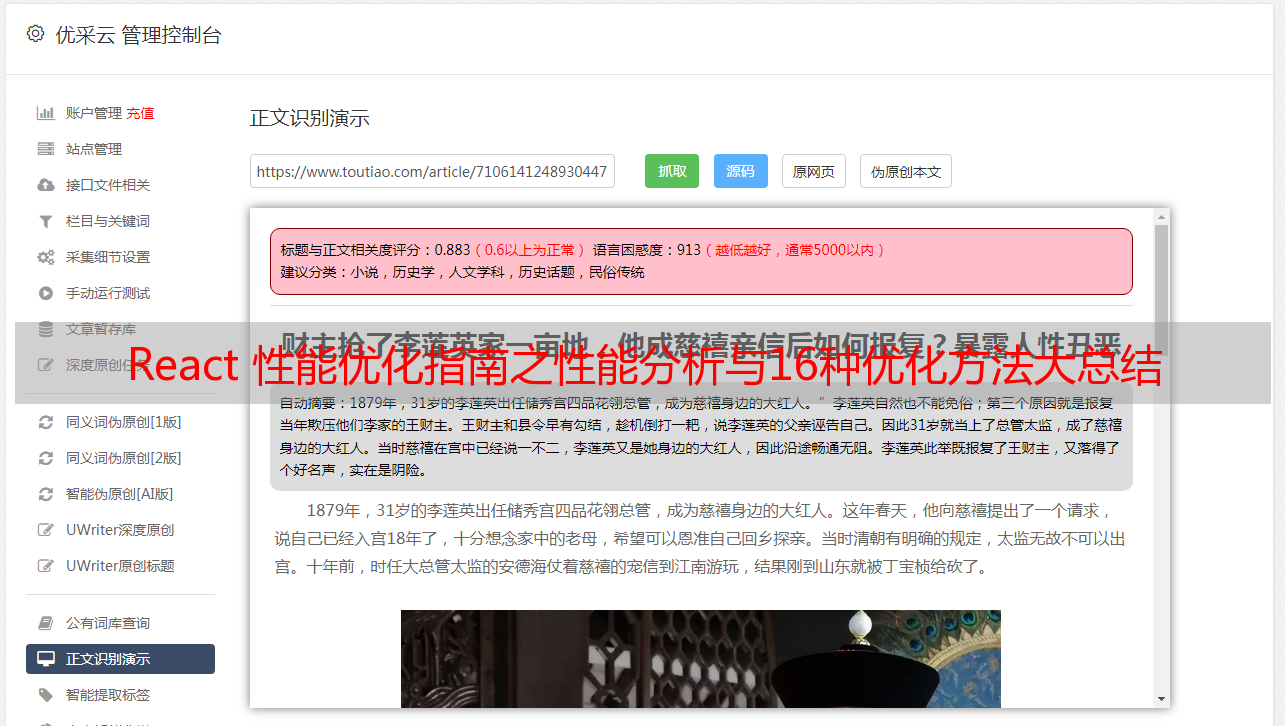
5、当前选中组件或者 Commit 的详情, 双击具体组件可以详细比对每一次 commit 消耗的时间
简单总结下查看流程:
1、改配置:排除影响因素,去掉无意义的 commit,开启 render 原因记录
2、横看缩略图
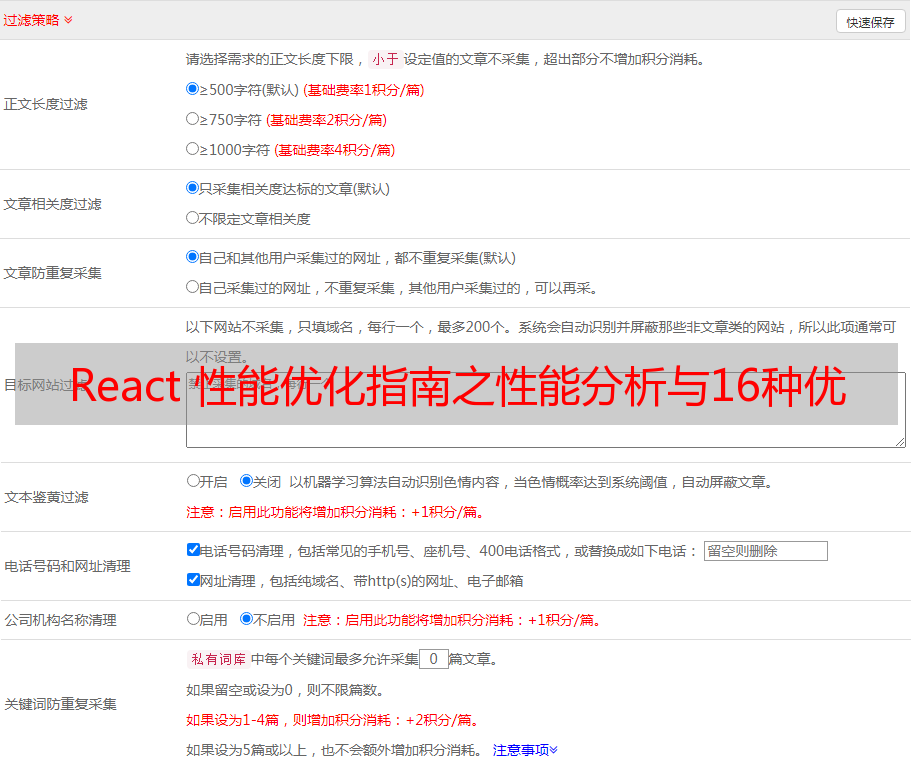
3、纵看火焰图
4、跟踪单个组件
2、Chrome Dev Tools
a、Performance
在 v16.5 之前,一般都是利用 Chrome 自带的 Performance 来进行 React 性能测量:
React 使用标准的User Timing API(所有支持该标准的浏览器都可以用来分析 React)来记录操作,所以我们在 Timings 标签中查看 React 的渲染过程。React 还特意使用 emoji 标记。
相对 React Devtool 而言 Performance 工具可能还不够直观,但是它非常强大, 使用 Performance 可以用来定位一些比较深层次的问题,这可能需要你对 React 的实现原理有一定了解, 就像使用 Wireshark 你需要懂点网络协议一样
所以说使用 Performance 工具有以下优势:
具体应该怎么看?
b、Memory
c、Light House
16个React 性能优化方法
之前的总结先来回顾下性能优化的三个方面:
1、前端通用优化。这类优化在所有前端框架中都存在,重点就在于如何将这些技巧应用在 React 组件中。
2、减少不必要的组件更新。这类优化是在组件状态发生变更后,通过减少不必要的组件更新来实现,对应到 React 中就是:减少渲染的节点 、降低组件渲染的复杂度、充分利用缓存避免重新渲染(利用缓存可以考虑使用PureComponent、React.memo、hook函数useCallback、useMemo等方法)
PureComponent 是对类组件的 Props 和 State 进行浅比较;React.memo 是对函数组件的 Props 进行浅比较
3、提交阶段优化。这类优化的目的是减少提交阶段耗时。
前端通用优化
这类优化在所有前端框架中都存在,本文的重点就在于将这些技巧应用在 React 组件中。
1、组件按需加载
组件按需加载优化又可以分为:懒加载、懒渲染、虚拟列表 三类。
懒加载
在 SPA 中,懒加载优化一般用于从一个路由跳转到另一个路由。还可用于用户操作后才展示的复杂组件,比如点击按钮后展示的弹窗模块。在这些场景下,可以结合 Code Split 实现。
懒加载的实现主要是通过 Webpack 的动态导入和 React.lazy 方法。注意,实现懒加载优化时,不仅要考虑加载态,还需要对加载失败进行容错处理。
import { lazy, Suspense, Component } from "react"<br />import "./styles.css"<br /><br />// 对加载失败进行容错处理<br />class ErrorBoundary extends Component {<br /> constructor(props) {<br /> super(props)<br /> this.state = { hasError: false }<br /> }<br /><br /> static getDerivedStateFromError(error) {<br /> return { hasError: true }<br /> }<br /><br /> render() {<br /> if (this.state.hasError) {<br /> return 这里处理出错场景<br /> }<br /><br /> return this.props.children<br /> }<br />}<br /><br />const Comp = lazy(() => {<br /> return new Promise((resolve, reject) => {<br /> setTimeout(() => {<br /> if (Math.random() > 0.5) {<br /> reject(new Error("模拟网络出错"))<br /> } else {<br /> resolve(import("./Component"))<br /> }<br /> }, 2000)<br /> })<br />})<br /><br />export default function App() {<br /> return (<br /> <br /> <br /> 实现懒加载优化时,不仅要考虑加载态,还需要对加载失败进行容错处理。<br /> <br /> <br /> <br /> <br /> <br /> <br /> <br /> )<br />}<br />
懒渲染
懒渲染指当组件进入或即将进入可视区域时才渲染组件。常见的组件 Modal/Drawer 等,当 visible 属性为 true 时才渲染组件内容,也可以认为是懒渲染的一种实现。
懒渲染的使用场景有:
判断组件是否出现在可视区域内是通过 react-visibility-observer 进行*敏*感*词*。
import { useState, useEffect } from "react"<br />import VisibilityObserver, {<br /> useVisibilityObserver,<br />} from "react-visibility-observer"<br /><br />const VisibilityObserverChildren = ({ callback, children }) => {<br /> const { isVisible } = useVisibilityObserver()<br /> useEffect(() => {<br /> callback(isVisible)<br /> }, [callback, isVisible])<br /><br /> return {children}<br />}<br /><br />export const LazyRender = () => {<br /> const [isRendered, setIsRendered] = useState(false)<br /><br /> if (!isRendered) {<br /> return (<br /> <br /> {<br /> if (isVisible) {<br /> setIsRendered(true)<br /> }<br /> }}<br /> ><br /> <br /> <br /> <br /> )<br /> }<br /><br /> console.log("滚动到可视区域才渲染")<br /> return 我是 LazyRender 组件<br />}<br /><br />export default LazyRender<br />
虚拟列表
虚拟列表是懒渲染的一种特殊场景。实现虚拟列表的组件有 react-window 和 react-virtualized。react-window 是 react-virtualized 的轻量版本,其 API 和文档更加友好。新项目中推荐使用 react-window。
使用 react-window 很简单,只需要计算每项的高度即可。如果每项的高度是变化的,可给 itemSize 参数传一个函数。
import { FixedSizeList as List } from "react-window"<br />const Row = ({ index, style }) => Row {index}<br /><br />const Example = () => (<br /> <br /> {Row}<br /> <br />)<br />
2、批量更新
关于如何实现批量更新可参考之前的文章:葡萄zi:React函数式组件中实现批量更新的两种方式,看下你用对了吗?
在React18中会有并发模式,在并发模式中,将默认以批量更新方式执行 setState。到那时候,或许就不需要这个优化了。
3、按优先级更新,及时响应用户
优先级更新是批量更新的逆向操作,其思想是:优先响应用户行为,再完成耗时操作。常见的场景是:页面弹出一个 Modal,当用户点击 Modal 中的确定按钮后,代码将执行两个操作。a) 关闭 Modal。b) 页面处理 Modal 传回的数据并展示给用户。当 b) 操作需要执行 500ms 时,用户会明显感觉到从点击按钮到 Modal 被关闭之间的延迟。
4、利用debounce、throttle 避免重复回调
在搜索组件中,当 input 中内容修改时就触发搜索回调。当组件能很快处理搜索结果时,用户不会感觉到输入延迟。但实际场景中,中后台应用的列表页非常复杂,组件对搜索结果的 Render 会造成页面卡顿,明显影响到用户的输入体验。
在搜索场景中一般使用 useDebounce + useEffect 的方式获取数据。
例子参考:debounce-search。
import { useState, useEffect } from "react"<br />import { useDebounce } from "use-debounce"<br /><br />export default function App() {<br /> const [text, setText] = useState("Hello")<br /> const [debouncedValue] = useDebounce(text, 300)<br /><br /> useEffect(() => {<br /> // 根据 debouncedValue 进行搜索<br /> }, [debouncedValue])<br /><br /> return (<br /> <br /> {<br /> setText(e.target.value)<br /> }}<br /> /><br /> <p>Actual value: {text}<br />
Debounce value: {debouncedValue}<br /> <br /> )<br />}<br /></p>
为什么搜索场景中是使用 debounce,而不是 throttle 呢?
throttle 是 debounce 的特殊场景,throttle 给 debounce 传了 maxWait 参数,可参考 useThrottleCallback。在搜索场景中,只需响应用户最后一次输入,无需响应用户的中间输入值,debounce 更适合使用在该场景中。而 throttle 更适合需要实时响应用户的场景中更适合,如通过拖拽调整尺寸或通过拖拽进行放大缩小(如:window 的 resize 事件)。实时响应用户操作场景中,如果回调耗时小,甚至可以用 requestAnimationFrame 代替 throttle。
5、缓存优化
缓存优化往往是最简单有效的优化方式,在 React 组件中常用 useMemo 缓存上次计算的结果。当 useMemo 的依赖未发生改变时,就不会触发重新计算。一般用在「计算派生状态的代码」非常耗时的场景中,如:遍历大列表做统计信息。
跳过不必要的组件更新1、PureComponent、React.memo
在 React 工作流中,如果只有父组件发生状态更新,即使父组件传给子组件的所有 Props 都没有修改,也会引起子组件的 Render 过程。从 React 的声明式设计理念来看,如*敏*感*词*组件的 Props 和 State 都没有改变,那么其生成的 DOM 结构和副作用也不应该发生改变。当子组件符合声明式设计理念时,就可以忽略子组件本次的 Render 过程。PureComponent 和 React.memo 就是应对这种场景的,PureComponent 是对类组件的 Props 和 State 进行浅比较,React.memo 是对函数组件的 Props 进行浅比较。
2、 shouldComponentUpdate
在 React 刚开源的那段时期,数据不可变性还没有现在这样流行。当时 Flux 架构就使用的模块变量来维护 State,并在状态更新时直接修改该模块变量的属性值,而不是使用展开语法生成新的对象引用。例如要往数组中添加一项数据时,当时的代码很可能是 state.push(item),而不是 const newState = [...state, item]。这点可参考 Dan Abramov 在演讲 Redux 时演示的 Flux 代码。
在此背景下,当时的开发者经常使用 shouldComponentUpdate 来深比较 Props,只在 Props 有修改才执行组件的 Render 过程。如今由于数据不可变性和函数组件的流行,这样的优化场景已经不会再出现了。
接下来介绍另一种可以使用 shouldComponentUpdate 来优化的场景。在项目初始阶段,开发者往往图方便会给子组件传递一个大对象作为 Props,后面子组件想用啥就用啥。当大对象中某个「子组件未使用的属性」发生了更新,子组件也会触发 Render 过程。在这种场景下,通过实现子组件的 shouldComponentUpdate 方法,仅在「子组件使用的属性」发生改变时才返回 true,便能避免子组件重新 Render。
但使用 shouldComponentUpdate 优化第二个场景有两个弊端。
<br /> {/* B 组件只使用了 data.a 和 data.b */}<br /> <br /> {/* C 组件只使用了 data.c */}<br /> <br /> </B><br /></A><br />
B 组件的 shouldComponentUpdate 中只比较了 data.a 和 data.b,目前是没任何问题的。之后开发者想在 C 组件中使用 data.c,假设项目中 data.a 和 data.c 是一起更新的,所以也没任何问题。但这份代码已经变得脆弱了,如果某次修改导致 data.a 和 data.c 不一起更新了,那么系统就会出问题。而且实际业务中代码往往更复杂,从 B 到 C 可能还有若干中间组件,这时就很难想到是 shouldComponentUpdate 引起的问题了。
第二个场景最好的解决方案是使用发布者订阅者模式,只是代码改动要稍多一些,可参考本文的优化技巧「发布者订阅者跳过中间组件 Render 过程」。
第二个场景也可以在父子组件间增加中间组件,中间组件负责从父组件中选出子组件关心的属性,再传给子组件。相比于 shouldComponentUpdate 方法,会增加组件层级,但不会有第二个弊端。
本文中的跳过回调函数改变触发的 Render 过程也可以用 shouldComponentUpdate 实现,因为回调函数并不参与组件的 Render 过程。
3、useMemo、useCallback 实现稳定的 Props 值
如果传给子组件的派生状态或函数,每次都是新的引用,那么 PureComponent 和 React.memo 优化就会失效。所以需要使用 useMemo 和 useCallback 来生成稳定值,并结合 PureComponent 或 React.memo 避免子组件重新 Render。
拓展知识
useCallback 是「useMemo 的返回值为函数」时的特殊情况,是 React 提供的便捷方式。在 React Server Hooks 代码 中,useCallback 就是基于 useMemo 实现的。尽管 React Client Hooks 没有使用同一份代码,但 useCallback 的代码逻辑和 useMemo 的代码逻辑仍是一样的。
4、发布者订阅者跳过中间组件 Render 过程
React 推荐将公共数据放在所有「需要该状态的组件」的公共祖先上,但将状态放在公共祖先上后,该状态就需要层层向下传递,直到传递给使用该状态的组件为止。每次状态的更新都会涉及中间组件的 Render 过程,但中间组件并不关心该状态,它的 Render 过程只负责将该状态再传给子组件。在这种场景下可以将状态用发布者订阅者模式维护,只有关心该状态的组件才去订阅该状态,不再需要中间组件传递该状态。当状态更新时,发布者发布数据更新消息,只有订阅者组件才会触发 Render 过程,中间组件不再执行 Render 过程。
只要是发布者订阅者模式的库,都可以进行该优化。比如:redux、use-global-state、React.createContext 等。例子参考:发布者订阅者模式跳过中间组件的渲染阶段,本示例使用 React.createContext 进行实现。
import { useState, useEffect, createContext, useContext } from "react"<br /><br />const renderCntMap = {}<br />const renderOnce = name => {<br /> return (renderCntMap[name] = (renderCntMap[name] || 0) + 1)<br />}<br /><br />// 将需要公共访问的部分移动到 Context 中进行优化<br />// Context.Provider 就是发布者<br />// Context.Consumer 就是消费者<br />const ValueCtx = createContext()<br />const CtxContainer = ({ children }) => {<br /> const [cnt, setCnt] = useState(0)<br /> useEffect(() => {<br /> const timer = window.setInterval(() => {<br /> setCnt(v => v + 1)<br /> }, 1000)<br /> return () => clearInterval(timer)<br /> }, [setCnt])<br /><br /> return {children}<br />}<br /><br />function CompA({}) {<br /> const cnt = useContext(ValueCtx)<br /> // 组件内使用 cnt<br /> return 组件 CompA Render 次数:{renderOnce("CompA")}<br />}<br /><br />function CompB({}) {<br /> const cnt = useContext(ValueCtx)<br /> // 组件内使用 cnt<br /> return 组件 CompB Render 次数:{renderOnce("CompB")}<br />}<br /><br />function CompC({}) {<br /> return 组件 CompC Render 次数:{renderOnce("CompC")}<br />}<br /><br />export const PubSubCommunicate = () => {<br /> return (<br /> <br /> <br /> 优化后场景<br /> <br /> 将状态提升至最低公共祖先的上层,用 CtxContainer 将其内容包裹。<br /> <br /> <br /> 每次 Render 时,只有组件A和组件B会重新 Render 。<br /> <br /><br /> <br /> 父组件 Render 次数:{renderOnce("parent")}<br /> <br /> <br /> <br /> <br /> <br /> <br /> )<br />}<br /><br />export default PubSubCommunicate<br />
5、状态下放,缩小状态影响范围
如果一个状态只在某部分子树中使用,那么可以将这部分子树提取为组件,并将该状态移动到该组件内部。如下面的代码所示,虽然状态 color 只在和
中使用,但 color 改变会引起重新 Render。
import { useState } from "react"<br /><br />export default function App() {<br /> let [color, setColor] = useState("red")<br /> return (<br /> <br /> setColor(e.target.value)} /><br /> Hello, world!<br /> <br /> <br /> )<br />}<br /><br />function ExpensiveTree() {<br /> let now = performance.now()<br /> while (performance.now() - now <br /> Hello, world!</p><br /> <br /> )<br />}<br /></p>
这样调整之后,color 改变就不会引起组件 App 和 ExpensiveTree 重新 Render 了。
如果对上面的场景进行扩展,在组件 App 的顶层和子树中都使用了状态 color ,但仍然不关心它,如下所示。
import { useState } from "react"<br /><br />export default function App() {<br /> let [color, setColor] = useState("red")<br /> return (<br /> <br /> setColor(e.target.value)} /><br /> <br /> Hello, world!<br /> <br /> )<br />}<br /></p>
在这种场景中,我们仍然将 color 状态抽取到新组件中,并提供一个插槽来组合,如下所示。
import { useState } from "react"<br /><br />export default function App() {<br /> return <br />}<br /><br />function ColorContainer({ expensiveTreeNode }) {<br /> let [color, setColor] = useState("red")<br /> return (<br /> <br /> setColor(e.target.value)} /><br /> {expensiveTreeNode}<br /> Hello, world!<br /> <br /> )<br />}<br /></p>
这样调整之后,color 改变就不会引起组件 App 和 ExpensiveTree 重新 Render 了。
该优化技巧来源于before-you-memo,Dan 认为这种优化方式在 Server Component 场景下更有效,因为可以在服务端执行。
6、列表项使用 key 属性
当渲染列表项时,如果不给组件设置不相等的属性 key,就会收到如下报警。
相信很多开发者已经见过该报警成百上千次了,那 key 属性到底在优化了什么呢?举个 ,在不使用 key 时,组件两次 Render 的结果如下。
<br /><br /> Duke<br /> Villanova<br /><br /><br /><br /><br /> Connecticut<br /> Duke<br /> Villanova<br /><br />
此时 React 的 Diff 算法会按照
最后, 送人玫瑰,手留余香,觉得有收获的朋友可以点赞,关注一波 ,我们组建了高级前端交流群,如果您热爱技术,想一起讨论技术,交流进步,不管是面试题,工作中的问题,难点热点都可以在交流*敏*感*词*流,为了拿到大Offer,邀请您进群,入群就送前端精选100本电子书以及 阿里面试前端精选资料添加下方小助手二维码或者扫描二维码就可以进群。让我们一起学习进步.