【教程】银行信息如何爬取?是否违法?(爬虫实际应用)
优采云 发布时间: 2022-05-01 12:28【教程】银行信息如何爬取?是否违法?(爬虫实际应用)
但是当你下拉一下右上角的“网点类型”,重新选择“全部”选项之后,会发现“下一页”按钮生效了。
这应该是网页的一个bug,但我们知道了纠错方法,现在的问题是:
如何在爬虫中应用
所谓爬虫程序,只是对真实操作的模拟。
就像你有个助理一样,只要把规则跟他说清楚,他就会自动工作。
按照我们之前的教程,爬虫可以完成“点击网点类型”之后的所有操作,那我们只要想办法帮它跳过这一步,后面就没有什么问题了。
看不懂这个图的读者,可以参考这篇教程《》
具体操作方法有三种。
第三种算是一种脑洞,大家一定要看一下,并且体会如何“活学活用”已有工具。
2.方法一:手动辅助操作
在我们开始爬虫之前,会设置“爬取间隔时间”。
如果我们按照原定的2000毫秒(2秒)来设置的话,爬取窗口一弹出,基本就开始翻页爬取了,留给我们手动操作的时间太短。
所以,我们可以把间隔时间设置长一些(比如8000毫秒),让我们有时间手动点击一下“网点类型”,排除一下网页的故障,再让爬虫继续爬取。
相当于把重复任务给助理之前,先帮他完成第一步,然后他就能顺利工作了。
方法二:数据预览功能
除了正常爬取之外,我们其实还可以利用“数据预览”功能,直接查看爬取到的结果。
比如,我可以在点击完“网点类型”,确定网页没有故障之后,直接点击重复单元旁边的“数据预览(data preview)”。
过一会儿就能看到,网页开始翻页,就像模拟真实爬取过程一样。
等它翻到最后一页之后,下方的窗口中会弹出一个数据表格,里面的内容就是我们要抓取的数据。
把这部分数据复制下来,粘贴到我们想要存储的文件中,做一点格式的调整就可以了。
“数据预览(data preview)”功能非常重要,能帮我们解决大量问题。
比如,有些网页爬取的第一步,可能并非“点击一下”这么简单,而是需要填写用户名和密码等信息,我们预留的“间隔时间”可能不够。
这时,就不必非得“正式爬取”,而是在编写好规则之后,直接点击对应元素的“数据预览”,然后把结果直接复制粘贴下来。
可以把“数据预览”想象成一个调试过程。
如果调试正确了,我们就直接把结果拿出来,而不必真的再重复运行一次爬虫。
注意:
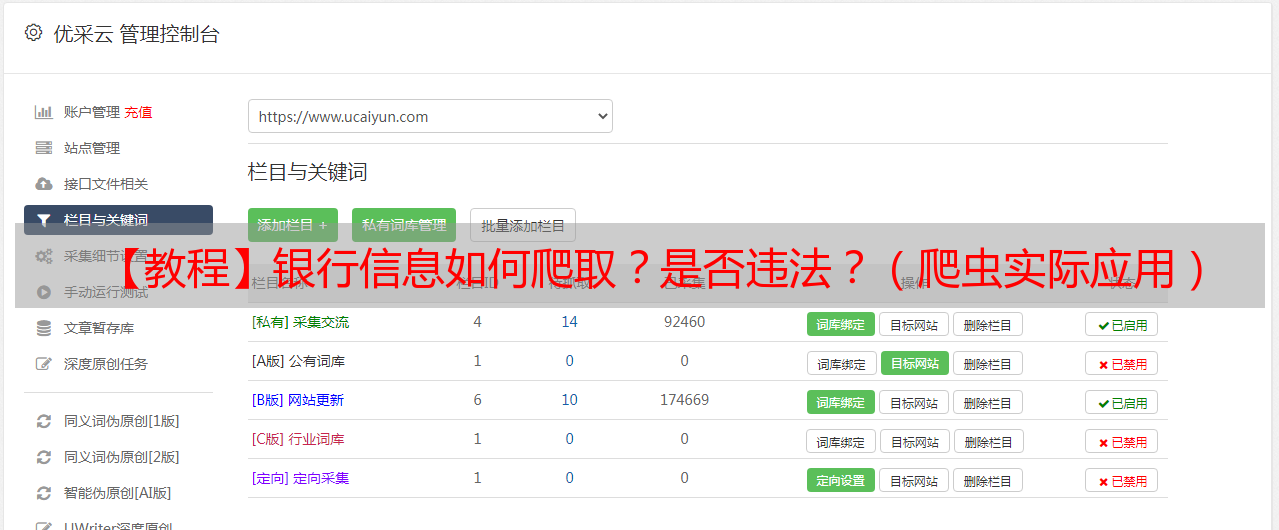
如果爬虫中设置了“重复单元”,要点击它对应的“数据预览”,这样重复单元里的所有数据都可以显现出来。
如果只点击重复单元下的单个元素的预览,那么最终的结果只会显示那一个元素。
方法三:活学活用click
以上两种,算是比较常规的操作。
但我后来又想到了一个“旁门左道”,可以把第一步的“手动操作”也写进自动化爬虫中。
方法其实不复杂。
之前我们手动操作时,要做的就是点击一下“网点类型”,然后再重新点击一下“全部”这个选项。
也就是说,如果我能让爬虫自动点击,就不用我手动操作了。
虽然WebScraper并没有单独的“点击”选项,但我们之前的教程中,其实有一个selector里是可以实现点击的。
只不过这次我不需要爬取任何element,我只需要爬虫帮我点击一个按钮而已。
按照这个思路,我们就可以新建一个selector,选择任意爬取对象(因为我们不需要爬取,而是想借用点击功能)。
然后在选择click selector时,选中我们想要点击的按钮,并且在click type里选择“只点一次(click once)”。
这样我们就相当于模拟出了,手动操作里第一步(点击下拉菜单)。
以此类推,我们也可以新建一个click selector,让它在下拉菜单中,点击“全部”这个选项。
注意:在用select选择“全部”这个元素前,要保证网点类型的下拉菜单已经拉开,否则无法选中。
有了前两步的点击之后,我们就可以按照正常流程,添加后面的爬取规则了。
因为WebScraper是按照顺序来执行命令,所以它会先完成两次设置好的点击,然后再开始后面的爬取。
3.有关法律法规
关于爬虫,之前就有朋友问过我如下的问题:
因为这次爬取的是银行的网页,所以又简单查了一下相应的法规。
理论上只要是公开数据,通常不会被判为侵权。像百度,谷歌这些搜索引擎,其实就是就是这么爬取信息的。
但是要注意,根据相关条例:
所以,你要让电脑帮你自动复制粘贴,而不是让它一天访问几百万次,搞垮对方的服务器。
这就好比,你可以叫一个跑腿的服务,帮你去餐馆取餐,但不能叫几千个小哥,同时挤进一家店,那别人还怎么做生意。
但大家也不必有太大的担心。
一来是因为大家浏览的网页信息,通常都是公开可查询的,不公开的东西,你也找不到。
二来是为了防止恶意访问,网站通常会有反爬机制,没等你触犯法律,就已经触碰到了网站的底线了。
对于担心是否违规的朋友,我的回答是:
不是不想,而是不能。
4.总结
具体的干货,上面都已经分享完了,但在写这篇文章时,有了几点很深的感受。
首先,工具是死的,但人是活的。
只要愿意开动脑筋,办法总是比问题多。就像我给出的第三种click方法,其实人家估计也没那么设计,但不妨碍我们这么使用。
这方面,我觉得真得学习下公园里健身的大爷。
大爷们会根据自己的需求,重新定义各种健身器械,抛开是否科学安全不谈,这种创新开拓的精神,真值得我们学习。
其次,“无知”不可怕,对“无知”的无知才可怕。
当我知道自己“无知”时,起码有学习的机会和动力,但当我完全不知道自己的“无知”时,连基本的改善空间都没有。
这也是我想要探索和学习新技能和新工具的原动力。
学会了一个技能之后,除了感受到喜悦之外,也会出一身冷汗。心想要是不知道这些知识,未来的人生要多费多大力气啊!
最后,成为1%的人不困难。
我在文章中的“案例说明”当中,说了这么一句:
但真正会做的人,我估计连1%都不到。
也就是说,只要你开始行动,不管结果是否理想,都已经超过了99%的人了。
至于这个结论是如何得到的,我会在后面的文章里详细叙述(因为这几天在手机上看书时,发现了一个有趣的数据)。
最后的最后,读者才是作者最大的财富。
在帮他解决完问题之后,他发来了一条信息。
《》中刚说过,得为读者创造价值,才有可能获得认可,这里就给出了反馈。
如果你在工作中遇到了什么问题,也欢迎你留言描述,说不定我这边就有工具,帮你解决困扰已久的问题。

