大数据ETL工具箱组件剖析2
优采云 发布时间: 2022-04-29 20:11大数据ETL工具箱组件剖析2
大数据ETL工具箱组件剖析2第二部
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据,ETL是BI(商业智能)项目重要的一个环节。
业务库数据的实时数仓处理
为了实时捕获业务库当中的数据,我们这里可以使用多种技术手段来实现, 例如canal,maxwell或者flinkCDC,debezium等都可以,以下是几种技术的比较,其中flinkCDC的底层技术实现就是使用的debezium。
一、Maxwell的基本介绍
Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。它的常见应用场景有ETL、维护缓存、收集表级别的dml指标、增量到搜索引擎、数据分区迁移、切库binlog回滚方案等。官网()、GitHub()
Maxwell主要提供了下列功能:
Maxwell与canal的比较
主要区别:
个人选择Maxwell:
MySQL的binlog各种抽取方式的对比
开启MySQL的binlog
编辑配置文件 vim /etc/f
log-bin=/var/lib/mysql/mysql-bin
binlog-format=ROW
server_id=1
安装Maxwell实现实时采集MySQL数据
第一步:下载max-well并上传解压
第二步:修改maxwell配置文件
在bigdata03机器修改maxwell的配置文件
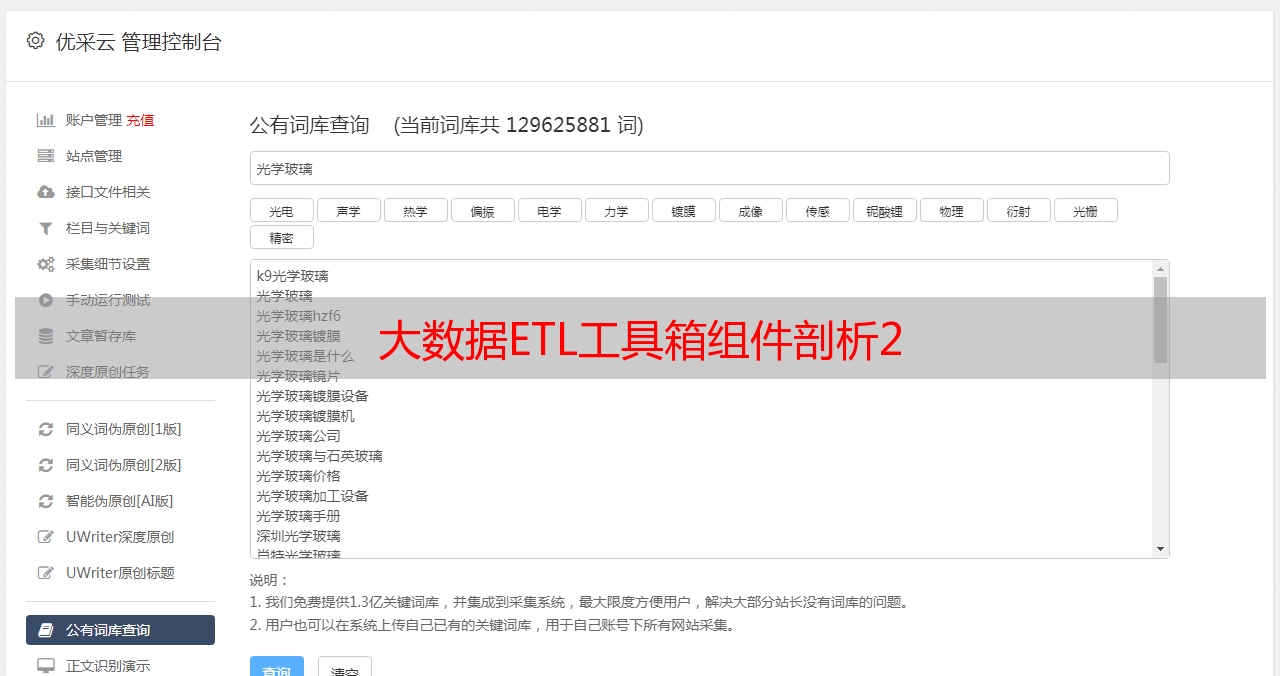
启动Maxwell服务
创建kafka的topic命令-bigdata01机器
启动Maxwell服务-bigdata03机器
二、DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步⼯具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、 Hive、HBase、OTS、ODPS 等各种异构数据源之间⾼效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件, 理论上DataX框架可以支持任意数据源类型的数据同步⼯作。同时DataX插件体系作为一套生态系统,每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
DataX架构
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX安装步骤
DataX配置-MySQL->HDFS
创建HDFS路径:
运行任务:
三、Elastic Stack与Beats介绍
Elastic公司提供了一整套搭建集中式日志平台的解决方案。最开始由Elasticsearch、Logstash、Kibana三个工具组成,简称ELK。在发展的过程中又有新成员Beats的加入,形成了Elastic Stack。
Beats
由于Logstash是在jvm中运行,收集数据时资源消耗比较大,elastic又推出了一系列轻量级的数据 采集工具,这些工具统称为Beats,Beats收集的数据可以直接输出到Elasticsearch中,也可以通过Logstash处理后输出到Elasticsearch中。
Beats有以下常用工具:
Filebeat:用于监控、收集服务器日志文件。
Metricbeat:可以监控、收集系统的CPU使用率、内存、磁盘IO等数据,以及 Apache、NGINX、MongoDB、MySQL、Redis 等服务的指标。
Beats-Filebeat和Metricbeat
轻量型数据采集器Beats是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或 成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。我们使用Beats系列最常用的Filebeat和Metricbeat采集日志文件和指标数据。
如果采集数据不需要任何处理,那么可以直接发送到Elasticsearch中。
如果采集的数据需要处理,那么可以发送到Logstash中,处理完成后再发送到Elasticsearch。最后通过Kibana对数据进行一系列的可视化展示。
Filebeat介绍和架构、安装
Filebeat是一款轻量型日志采集器,用于监控、收集服务器日志文件。
首先Filebeat指定一些日志文件为数据输入源,之后使用Harvester(收割机)源源不断的读取日 志,最后通过Spooler(卷轴)将日志数据传送到对应的目的地。
架构图如下:
安装步骤如截图
Filebeat配置文件1-采集一般日志文件
配置文件截图如下
自定义字段:Filebeat读取日志文件后会生成json格式的日志,我们还可以为生成的日志添加一些自定义字段。
如下截图。
Filebeat配置文件2-采集Nginx日志
Nginx的日志文件在/usr/local/nginx/logs中,正常日志存在access.log中,异常日志存在error.log中。
读取Nginx日志的配置文件
在收集Ngnix日志时,日志内容并没有处理,难以阅读其中的具体数据。Filebeat针对常见的服务提供了 处理日志的模板。接下来我们讲解Filebeat中Module的使用。
配置Nginx读取模板:
Filebeat配置文件3-写入ES和logstash
将数据输出到ES中、修改Filebeat配置文件
重启FileBeat
FileBeat采集日志写入logstash
四、Logstash介绍与架构
Logstash是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
早期的Logstash用于收集和处理数据。但由于Logstash在JVM中运行,运行时资源消耗比较大,现在更多使用Beats收集数据,Logstash处理Beats收集的数据。
Logstash安装
1.使用rz工具将Logstash压缩文件上传到Linux虚拟机
2.解压:
tar -zxvf logstash-7.12.1-linux-x86_64.tar.gz -C /usr/local/
3.日志文件 格式如下mylog.log
4.修改配置
Logstash配置文件有以下三部分构成:
根据该结构编写配置文件:
5.启动Logstash
Logstash-处理Beats收集数据
处理Beats收集的数据
由于JVM的启动,Logstash的收集速度比较慢,所以后面使用Beats来代替了Logstash进行收集,而Logstash负责处理Beats收集的数据。
1.配置Logstash 详见右侧截图
cd /usr/local/logstash-7.12.1/config/
vim mylog.conf
启动Logstash
2.配置Filebeat 详见右侧截图
#创建Filebeat配置文件
cd /usr/local/filebeat-7.12.1-linux-x86_64/
vim mylog.yml
启动Filebeat
3.追加数据进行测试

