php截取字符串网站内容( 如何建立索引大多数索引?索引结构怎么设置索引)
优采云 发布时间: 2022-04-16 16:17php截取字符串网站内容(
如何建立索引大多数索引?索引结构怎么设置索引)
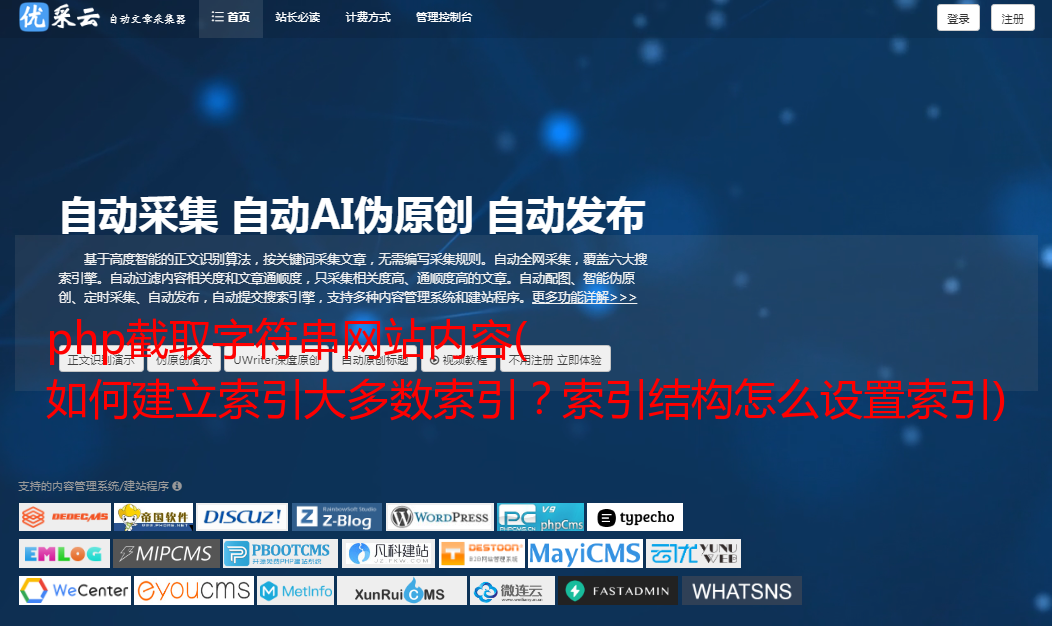
相信大部分朋友都和卡卡一样,从来没有设置过给字符串加索引的长度。今天,我们来谈谈如何正确地给字符串添加索引。
一、如何创建索引
大多数系统都会有一个用户表,系统的初始设计使用手机号登录。
这是产品提出的要求,让系统也可以支持邮箱登录。
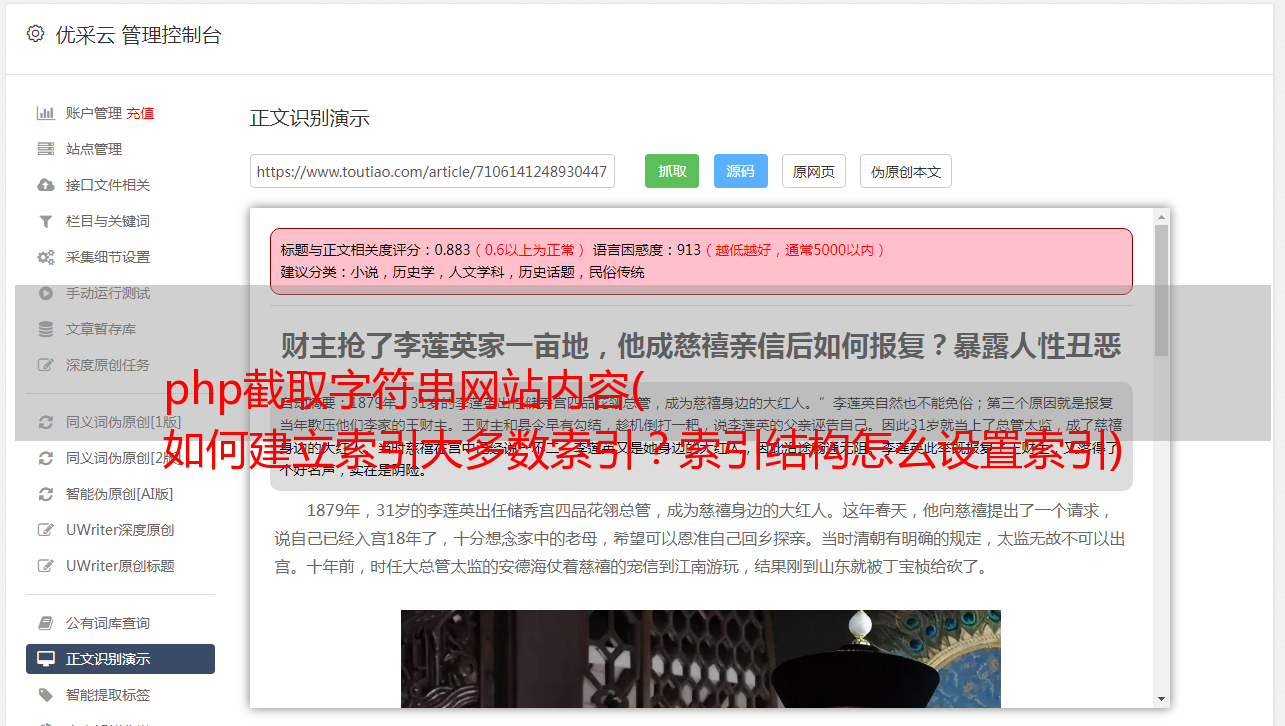
您可以确定的是,如果您执行查询而不向邮箱字段添加索引,它将执行全表扫描。
此时,你暗自庆幸这并不容易,只要在邮箱字段中添加索引就大功告成了!但是要想很好的实现复杂的需求,最好还是简单的需求来降低系统的所有压力。
此时拿起键盘执行alter table table_name add index idx_field(field)
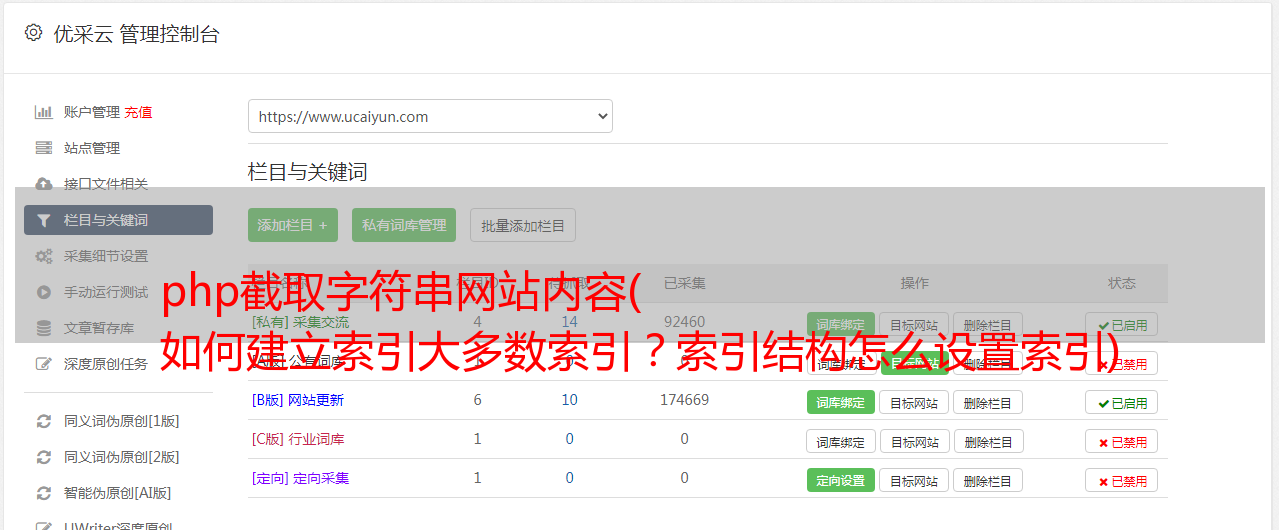
有的朋友不喜欢在命令行创建索引,喜欢用phpmyadmin工具来操作MySQL,那么有没有发现以后创建索引的时候可以设置大小呢?
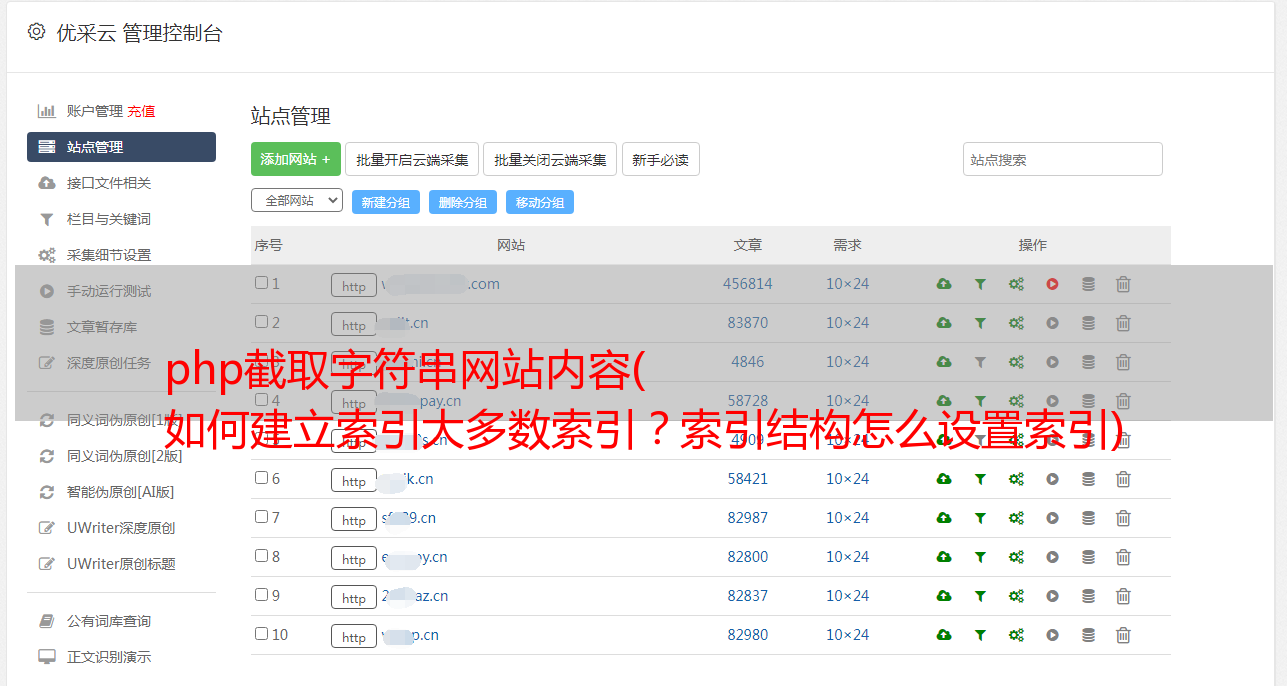
通过上图我们知道,字符串的索引可以定义长度,那么两者有什么区别。
使用命令行直接创建的索引 alter table table_name add index idx_field(field) 默认收录整个字符串。
如果执行此操作,则指定索引前缀长度 alter table table_name add index idx_field (field(6))
千愁万绪图,看看这两个索引结构是怎么创建的。
索引*敏*感*词*
索引*敏*感*词*
索引二*敏*感*词*
索引二*敏*感*词*
从图中可以看出,如果索引长度指定为6,那么只取邮箱字段的前6个字段。与收录整个字符串的索引相比,每个节点会存储更多的数据。
索引文章也告诉大家,索引越小越好。
凡事都有两面,有坏就有好。第六期文章误选索引的因素之一是扫描的行数。
减少索引长度的效果是索引基数变大,从而增加了额外的扫描记录数(执行explain的row字段)。
此时,执行 select id,name,email from mac_user where email='';
将索引执行流程添加到整个字符串
1、从邮件索引树中找到一条满意的记录,得到主键ID为1
2、根据ID 1到主键索引树找到这条记录,判断邮件是否正确,并将这一行记录为结果集。
3、重复第一步,直到不满足查询条件,循环结束。
指定索引长度执行过程
1、从邮件索引树中找到满足139739的记录,得到主键ID为1
2、根据ID从1到主键索引树找到这条记录,判断email不正确,丢弃这行记录。
3、在邮件索引树中找到刚刚查询到的下一条记录,发现还是139739,去掉ID2,然后到ID索引树上进行判断,值配对时添加结果集。
4、继续重复上一步,直到不满足查询条件,循环结束。
综上所述
在模拟执行过程的过程中,很容易发现使用前缀索引会导致读取数据的次数增加。这是否意味着使用前缀索引会增加查询成本?
当然不是,假设此时定义的长度是6,那么设置为7或8!会好很多吗?图中的案例为了方便设置了三个相同的数据,但实际情况基本不是这样。
索引侧重于歧视程度。只有区分度越高,重复值越少,查询效率越高。
所以使用前缀索引,只要定义好长度,就可以节省空间,而且不会增加太多额外的查询成本。
二、如何创建索引来确定要使用多长时间的前缀
MySQL 中的 关键词distinct 可以为该列返回不同的结果集。
比如查询 email 列有多少个不同的值 select count(distinct email) as num from mac_user。
如何计算一列具有不同前缀的行数
结合MySQL自带的函数left,比如select count(distinct left(email,4)) as num4 from mac_user,截取email的前四串,计算出有多少行。
然后用这个值除以总数得到比例,可以根据业务情况判断比例是多少。
三、使用前缀索引的影响
使用前缀索引会增加扫描的行数,也会使覆盖索引无效。
为什么它会影响覆盖索引?
如果执行语句是select id,email from mac_user where email = ''。
使用全串索引结构查询可以使用覆盖索引,从邮件索引中得到的结果直接返回,无需回表。
如果使用前缀索引获取email索引中的结果,则需要回到id索引检查查询到的email值是否正确。
即使设置的长度大于email,也会返回表做判断,因为MySQL不知道定义的前缀是否截取了完整的信息。
综上所述
使用前缀索引会增加扫描的行数,但也不会使用覆盖索引。这个因素是选择是否使用前缀索引时要考虑的一个因素。
如果不知道使用前缀索引还是全字符串索引,可以在本地测试,选择适合生产环境的方案。
四、如何把不可用的变成可用的
假设身份认证系统存储的是*敏*感*词*号码,大家应该都知道*敏*感*词*号码的前6位是地址码,同一个县的*敏*感*词*号码的前6位一般都是一样的。
如果这样使用前缀索引,区分度会很低,不仅起不到加速查询的作用,还会导致索引区分度不影响查询性能。
索引长度越长,每个节点存储的索引值就越少,查询效率也会变得低效。
如果这种情况得到解决
第一个选项
存储数据时,按倒序存储数据,查询时按正序处理
第二种选择
向表中添加新字段,存储数据的哈希值,并为哈希添加前缀索引。
区别
使用这两种方案的共同点是不支持范围查询,只能查询等值。
从占用空间来看:闪回方式不会增加额外的存储空间,hash会增加一个字段。两者在空间上具有可比性
从CPU消耗来看:flashback需要使用函数reverse,hash需要使用crc32,reverse的消耗会很小。
从查询效率来看:hash查询更稳定。crc32计算出来的数值虽然有冲突,但是概率很小。基本上每个查询的平均扫描行数接近1。闪回中使用的前缀索引方法也会增加扫描行数。
五、总结
直接为字符串创建一个空格。
创建前缀索引可以节省空间,增加扫描的行数,并且不能使用覆盖索引。
闪回存储,创建前缀索引,解决小区分问题。
使用hash方式,查询稳定,不支持范围查询。

