网页抓取数据(一下重新加载整个网页的情况下如何更新部分网页技术)
优采云 发布时间: 2022-04-15 22:16网页抓取数据(一下重新加载整个网页的情况下如何更新部分网页技术)
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
比如打开这个页面,先不要移动,观察右边滚动条的长度,然后当你把滚动条拉到底的时候,滚动条变短了,也就是页面变长了,也就是说,有些数据是这个时候加载的。这个过程是动态加载的,基于ajax技术。我们可以看到,当拉动滚动条时,页面上的数据增加了,但是 URL 并没有改变。它不会像翻页那样将数据存储到另一个网页。现在让我们解释如何爬取这种网页。
本文分为以下几个部分
查看网页源代码的两种方式
首先需要声明的是,在使用浏览器时,两种查看网页源代码的方式是不同的。这里我们使用chrome浏览器来说明。
首先是右键检查,在 element 中查看网页的源代码,这种模式具有折叠和选择的功能,对于我们找到位置抓取信息非常有帮助。这里的源码就是我们面前当前显示的页面对应的源码。
二是右键-查看网页源代码,是网页真正的源代码,请求网页得到的源代码(r.text)与此如出一辙。
大多数情况下,这两个位置显示的源代码完全相同,但有时也存在差异。例如,在当前的动态加载示例中,当我拉下滚轮时,会重新加载新数据。这部分数据会出现在“检查”的源代码中,但不会出现在“查看页面源代码”中。. 后者是这个URL的原创源代码,不会被后面执行的JS程序改变,而“check”中的源代码和当前页面是一样的,是执行一些JS代码后重新生成的源代码. 代码。
有时会发生两个位置的源代码几乎相同,但在一些小标签属性或某个值上存在差异。在解析网页的时候,我们经常会以“check”中的源码为基础。当我们觉得解析代码没有问题,但又找不到什么(或有什么不对)时,可以考虑去“查看网页源代码”。那个页面,是不是有一个小地方的区别。
比如拿一个链家二手房的页面,看这里的“税费”,你先刷新页面观察这个位置,你会发现它会先加载13.8,然后变成 45.@ >
两种方式看源码都会发现,检查时是45,查看网页源代码时是13.8不变。所以,如果你想爬这个网站,不做任何处理,你会得到13.8,这是链家故意给你的假数据。
言归正传,如果我们要捕获这个网页的数据,如果我们像以前一样只提取r.text来解析网页,我们只能得到一开始加载的数据,我们如何将所有数据捕获到稍后加载这就是我们要在这里讨论的内容。
分析网页请求
我们在页面中右键--勾选,选择network,选择XHR,将左侧网页的滚动条拖到底部加载新数据,可以看到network中出现了一个新文件
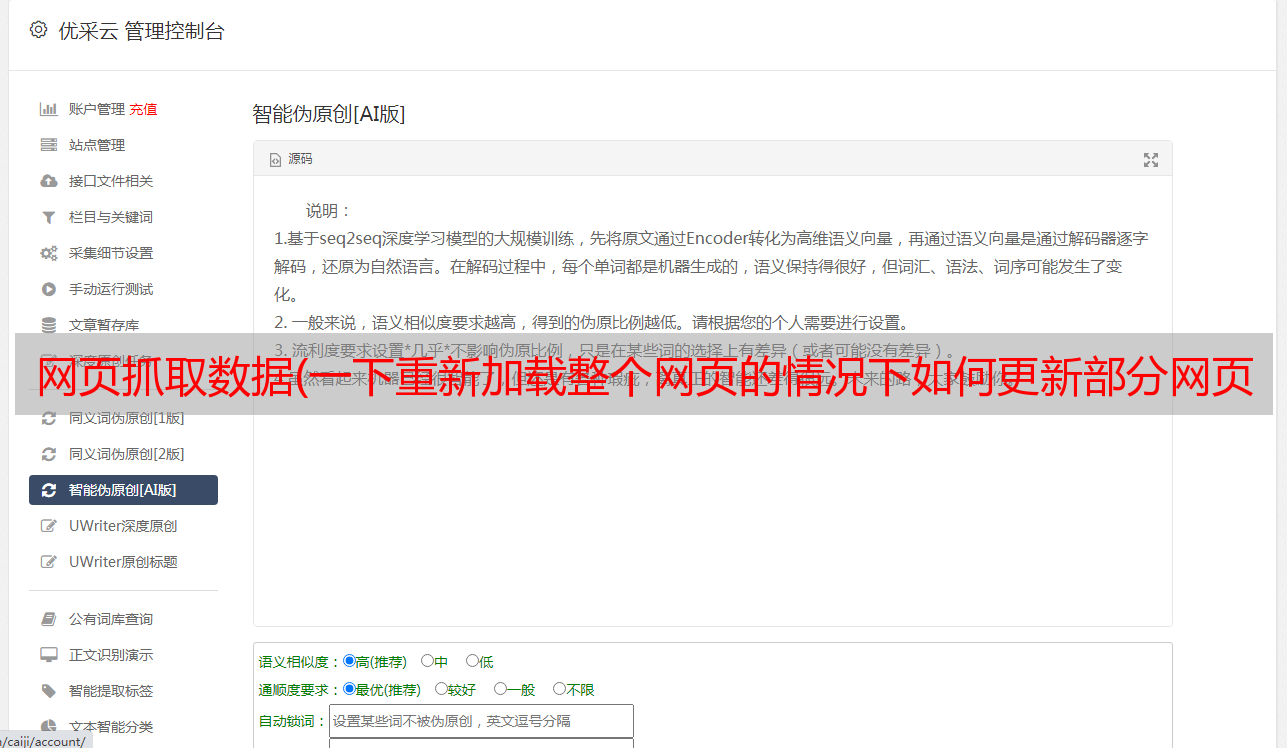
这些是你拖动时浏览器对网页的新请求,加载的数据就是从这个请求中获取的。也就是说,我们可以在这些新加载的文件中找到我们想要的数据。根据经验数据,它存在于第一个URL中。点击这个网址,可以看到如下图(读者可以点击其他网址,会发现其他文件对我们抓取数据没有帮助)
preview 指示此 URL 的内容是什么。从上图可以看出,这是json格式的数据。我们可以展开每一项来看看里面有什么信息。
可以看到我们想要的关于文章的所有信息都在这里了,有些字段没有显示在网页上。对于这部分信息,我们只能根据里面的键值对名称来猜测这个字段是什么。意思是。
接下来我们可以请求这个URL获取数据,在headers中可以查看到URL
从json中提取信息会比解析网页容易很多,所以以后遇到爬虫任务时,首先检查网页请求中是否有类似的文件,如果有,可以直接请求这种json文件而不用逐步解析网页。.
一般这种json文件在XHR中很容易找到,但不排除有时需要全部找到这样的文件。
请求的文件通常非常大。没有方向的时候,只能一个一个的点击,但也不麻烦。每个网址都关注预览。json格式的数据就像刚才一样,其实很明显。
接下来,让我们编写代码来抓取数据。
抓取一页数据
现在假设我们只想要文章这个标题,我们只需要在XHR中请求那个URL,然后像字典一样处理得到的内容,代码如下
import requests
headers = {'cookie':'', # 传入你的cookies
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
def get_page():
r = requests.get('https://www.csdn.net/api/articles?type=more&category=home&shown_offset=0',
headers = headers)
d = r.json()
articles = d['articles']
for article in articles:
yield article['title']
for i in get_page():
print(i)
其中r.json是将json格式的字符串转换成python对象,这里是转换成字典。(读者可以尝试调用r.text,发现是json字符串,可以用json模块中的json.loads转换成字典对象,但是requests中提供的.json()使用起来更方便)
注意:如果您不使用cookies,您将无法获得主页上显示的数据。因此,即使您没有登录,也可以复制 cookie。
接下来让我们获取所有数据。
页面更新策略
当我们再次拉下页面时,我们会发现加载了一个新的 URL。
看它的headers,惊讶的发现和上一个一模一样,再看它的request headers,几乎是一样的,所以我们可以尝试连续两次请求这个页面,看看有没有我们得到不同的数据——真正不同的数据。
所以我们可以设置一个爬取策略:一直访问这个URL,直到获取不到数据为止。
我们连续请求20次,代码如下
import requests
headers = {'cookie':'', # 传入你的cookies
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
def get_page():
r = requests.get('https://www.csdn.net/api/articles?type=more&category=home&shown_offset=0',
headers = headers)
d = r.json()
articles = d['articles']
print(len(articles)) # 每次看抓取到了多少信息
for article in articles:
yield article['title']
def get_pages():
for i in range(20):
yield from get_page()
l = list(get_pages())
len(l) # 看总共抓了多少条
这段代码的结果是,在20个请求中,前15次获取到10条数据,后5次没有获取到数据,说明我们只能获取到150条信息。
这时候我们再看浏览器,会发现滚动条不会加载新的数据,刷新网页就会得到这个界面。
这意味着你的爬虫已经用尽了这个cookie,浏览器无法使用这个cookie获取数据,需要一段时间才能发出请求。
其他例子
ajax加载的页面的爬取是类似的,可能只是不同网站每个加载URL的设计不同。让我们再举一些例子
知乎live,它也是用鼠标下拉页面加载新数据,我们会怀疑是ajax加载的。同理可以找到如下文件
可以看到比CSDN多了一个字段分页,显示本页是否为最后一页,下一页的链接是什么。这样我们只需要像上图那样下拉一次就可以得到页面,然后请求页面,获取数据和下一页的url,然后请求下一页,获取数据并获取下一页,并通过判断is_end结束循环。
换句话说,我们可以查看当前 URL 和下一个 URL 之间是否存在模式,并通过构造 URL 进行循环。
如果读者没有尝试过,他可能会怀疑这里的下一页是否真的是下一页的数据。然后可以多次下拉网页,看后面的网址是不是前面的下一个。
知乎live 这种形式的 ajax 加载内容和 URL 设计应该是最常见的。我们可以看到它的URL其实就是知乎的API(看那个URL的域名),也就是我们浏览网页的时候,页面就是请求API得到的数据。API可以理解为一个数据接口,通过请求这个URL就可以得到对应的数据,那么这个URL就是一个接口。本专栏后面会写一篇文章文章来介绍API。
2.豆瓣电影
点击上面的标签:电影、热门、最新、豆瓣高分等。每次点击,你会发现浏览器中显示的网址没有变化,包括点击下面的点翻页,网址有没变,也就是说这里的数据可能是用ajax加载的,看下检查网络的XHR
发现数据确实是用ajax加载的,我们只需要请求这个URL就可以获取数据。
这时候我们选择最新和豆瓣高分标签,可以看到XHR中加载了一个新文件,如下图
只要我们分析这些文件的URL的规律性,我们就可以在这个窗口中抓取所有标签的电影数据。

