%E6%96%B0%97%BB为例来采集列表
优采云 发布时间: 2021-05-16 20:20%E6%96%B0%97%BB为例来采集列表
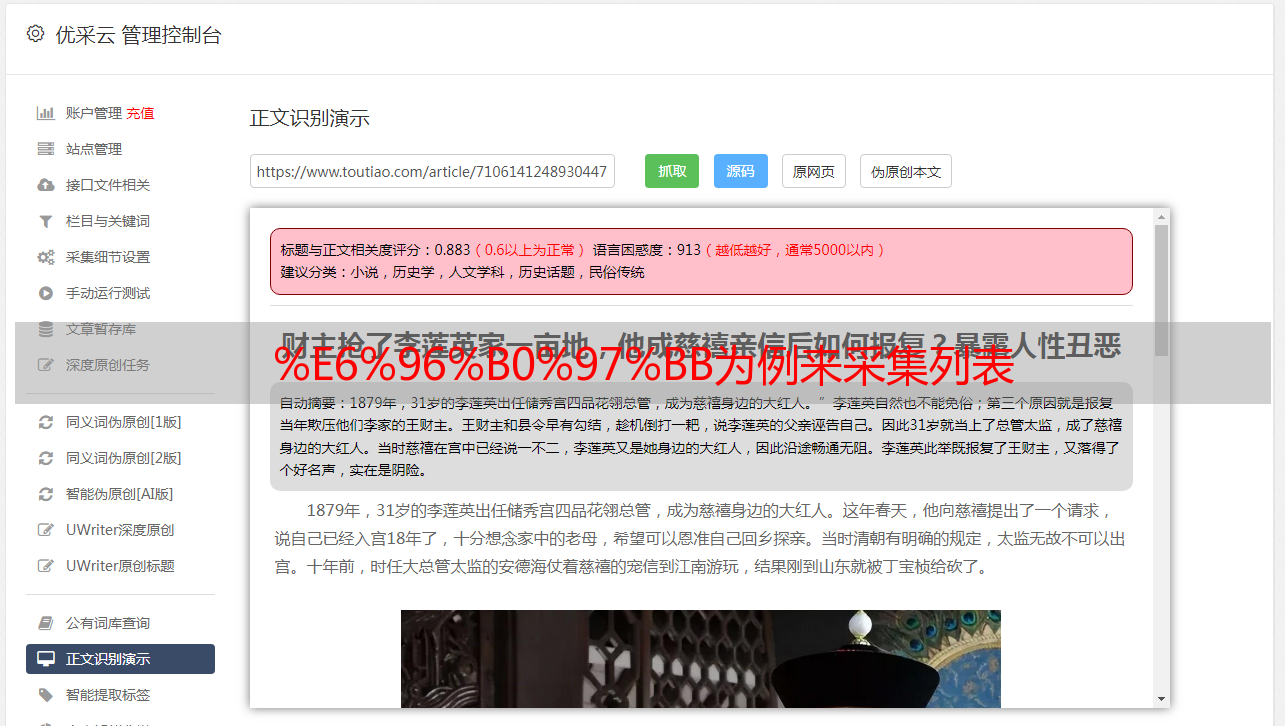
%E6%96%B0%E9%97%BB例如采集列表中的文章
使用Google Chrome浏览器打开链接,右键单击“审阅”,在控制台中切换到网络,然后单击XHR,以便可以过滤不必要的请求(例如图片,文件等),而仅请求查看内容页面
由于该页面是由ajax加载的,因此请将页面拉到底部,更多文章将自动加载。目前,控制台捕获的链接是指向我们真正需要的列表页面的链接:
在优采云 采集中创建任务
创建后,单击“ 采集设置”,然后在“起始页面URL”中填写上面爬网的链接
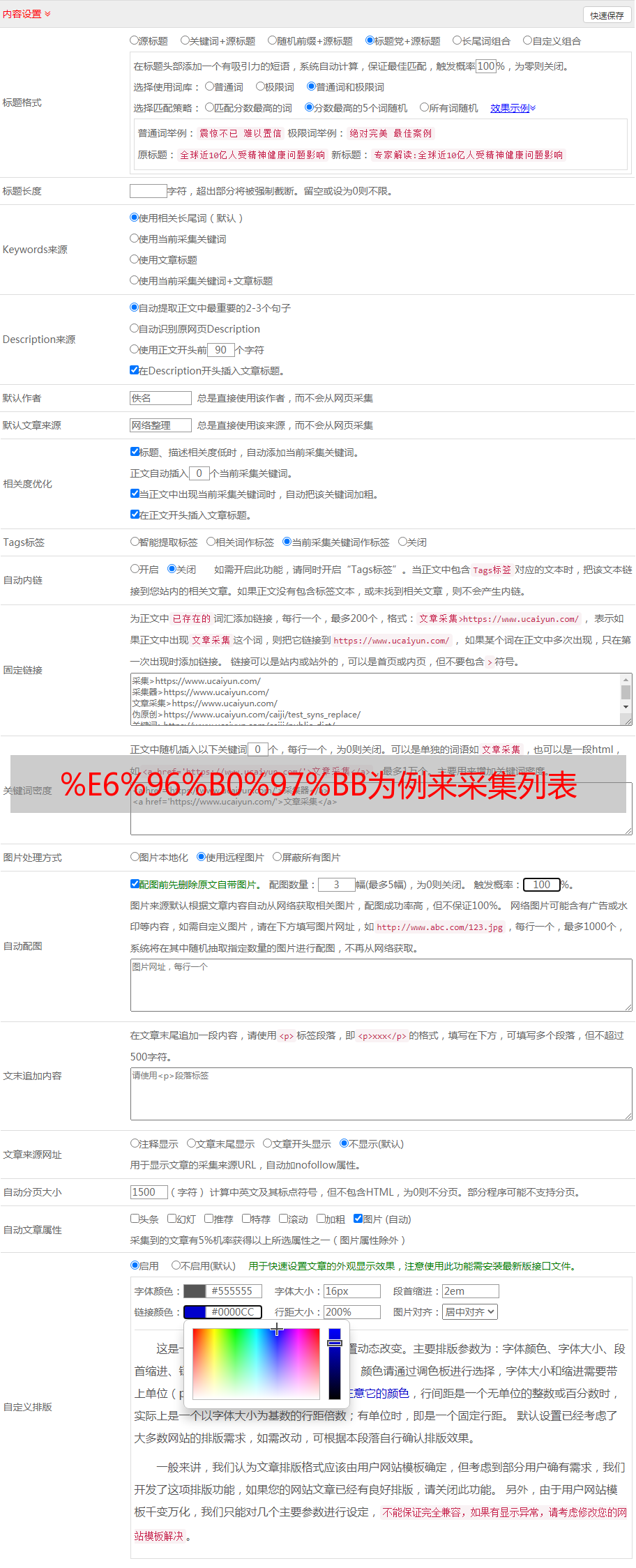
接下来匹配内容页面的URL,标题中的文章 URL格式为数字/
点击“内容页面网址”以编写“匹配的内容网址”规则:
这是一条常规规则,这意味着将匹配的URL加载到捕获组content1中,然后填写下面的[Content 1](与上面的content1相对应)以获取内容页面链接
您可以单击“测试”以查看链接是否成功爬网
获取成功后,您可以开始获取内容
单击“获取内容”以在字段列表的右侧添加默认字段,例如标题,正文等。可以智能识别,如果需要准确性,则可以自己编辑字段,支持常规,xpath ,json和其他匹配内容
我们需要获取文章的标题和文本。因为它是由Ajax显示的,所以我们需要编写规则以匹配内容。分析文章的源代码:,找到文章的位置
标题规则:articleInfo \ s:\ s {\ stitle:\ s“ [Content1]”,
文本规则:content \ s:\ s'[content1]',\ s * groupId
必须保证规则的唯一性,否则它将与其他内容匹配。将规则添加到字段中,然后选择获取规则以匹配规则的方法:
编写规则后,单击“保存”,然后单击“测试”以查看其工作原理
规则正确,爬网正常,捕获的数据也可以发布到cms系统,直接存储在数据库中,另存为excel文件等,只需单击“发布设置”即可。底部导航栏,今天好。标题采集在这里,您不妨尝试一下!
原文:

