关键词自动采集生成内容系统-无需任何打理(几章、apm日志监控系统的功能流程概览(组图))
优采云 发布时间: 2022-03-31 18:09关键词自动采集生成内容系统-无需任何打理(几章、apm日志监控系统的功能流程概览(组图))
前面章节介绍了elasticsearch和apm相关的内容。本视频主要介绍如何使用ELK Stack帮助我们搭建支持Nissan TB级别的日志监控系统
背景
在企业级微服务环境中,运行成百上千的服务被认为是一个相对较小的规模。在生产环境中,日志起着非常重要的作用。排查需要日志,性能优化需要日志,业务排查需要服务。但是,有数百个服务在生产中运行,每个服务都简单地存储在本地。当需要日志辅助排查时,很难找到日志所在的节点。业务日志的数据价值也难以挖掘。然后,将日志统一输出到一个地方集中管理,然后对日志进行处理,并将结果输出为可供运维使用的数据,
我们的解决方案
通过以上需求,我们推出了日志监控系统。
功能流程概述
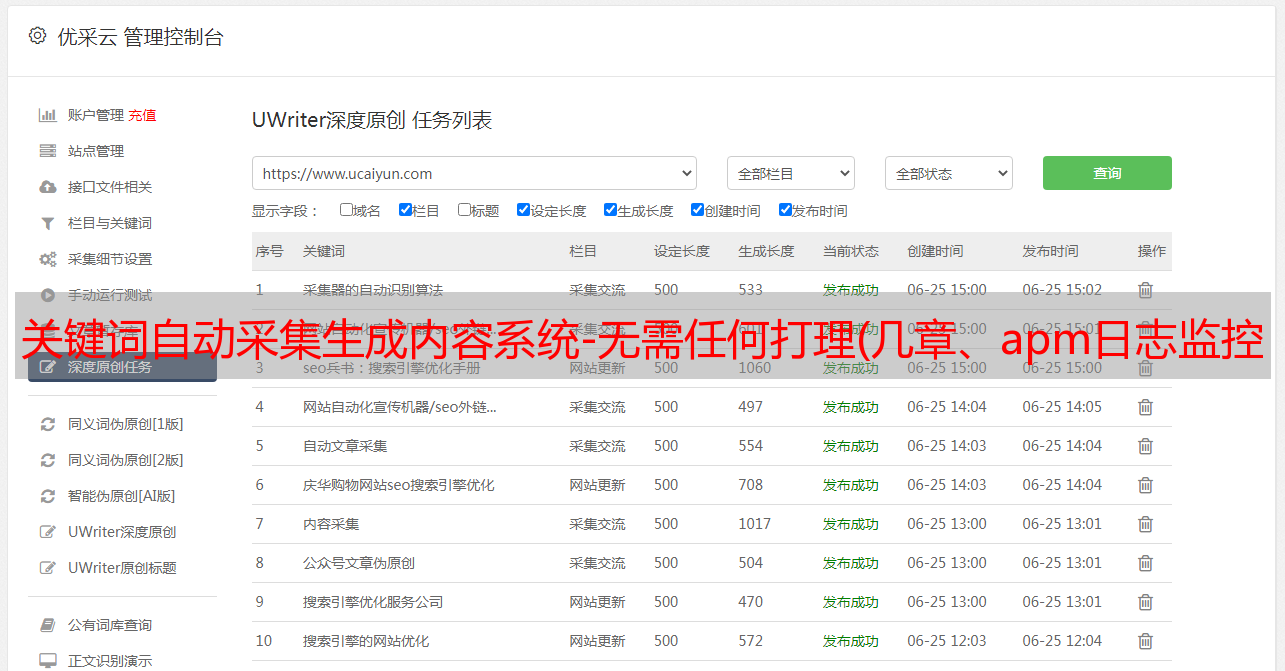
我们的架构
在日志文件采集端,我们使用filebeat,通过我们的后台管理界面配置运维。每台机器对应一个filebeat,每个filebeat日志对应的topic可以是*敏*感*词*一、多对一,根据每天的日志量配置不同的策略。除了采集业务服务日志,我们还采集了mysql慢查询日志和错误日志,以及其他第三方服务日志,比如nginx等。最后结合我们的自动化发布平台,自动发布并启动每个 filebeat 进程。我们对调用栈、链路、流程监控指标使用的代理方式:Elastic APM,这样业务端的程序就不需要改动了。对于已经运行的业务系统,更改代码以添加监控是不可取和不可接受的。Elastic APM可以帮助我们采集http接口的调用链接、内部方法调用栈、使用的SQL、进程的CPU、内存使用指标。有些人可能会有疑问。有了Elastic APM,其他日志基本可以不用采集了。为什么要使用 filebeat?是的,Elastic APM采集的资料确实可以帮我们定位80%以上的问题,但是并不是所有语言都支持如:C。它二、不能帮你采集你想要的非错误日志和所谓的关键日志,例如:调用接口时发生错误,你想查看错误发生前后的日志;有印刷业务相关的日志,便于分析。
其三、用户自定义业务异常,属于非系统异常,属于业务类别。APM 会将此类异常报告为系统异常。如果稍后再上报系统异常,这些异常会干扰您无法过滤业务异常以保证告警的准确性,因为自定义业务异常的类型很多。同时,我们开了两次代理。采集更详细的gc、栈、内存、线程信息。服务器采集我们使用 Prometheus。由于我们是面向SaaS服务的,所以服务很多,很多服务日志不能统一标准化,这也和历史遗留的问题有关。与业务系统无关的系统直接或间接连接到现有业务系统,为了适应自己并让它改变代码是不可能的。牛逼的设计就是让自己和别人兼容,把对方当成攻击自己的目标。许多日志毫无意义。比如在开发过程中,为了方便排查和跟踪问题,打印在if else中只是一个符号日志,代表是if代码块还是else代码块通过。一些服务甚至打印调试级别的日志。在成本和资源有限的条件下,所有的日志都是不现实的,即使资源允许,一年也将是一笔巨大的开销。因此,我们采用了过滤、清洗、动态调整日志优先级等解决方案采集。首先,把完整的日志 采集 进入kafka集群并设置很短的有效期。我们目前是设置一个小时,一个小时的数据量,我们的资源暂时还是可以接受的。
Log Streams 是我们用于日志过滤和清理的流处理服务。为什么还要使用 ETL 过滤器?因为我们的日志服务资源有限,但是不对,分散在各个服务本地存储介质上的原创日志也需要资源。*敏*感*词*有限的情况下,没有领导或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:在这种情况下,日志服务的资源是所有服务日志当前使用的资源量。存储时间越长,资源消耗越大。如果在短时间内解决一个非业务或无法解决的问题的成本大于解决当前问题的收益,我认为在资金有限的情况下,没有领导或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:在这种情况下,日志服务的资源是所有服务日志当前使用的资源量。存储时间越长,资源消耗越大。如果在短时间内解决一个非业务或无法解决的问题的成本大于解决当前问题的收益,我认为在资金有限的情况下,没有领导或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:资源消耗越大。如果在短时间内解决一个非业务或无法解决的问题的成本大于解决当前问题的收益,我认为在资金有限的情况下,没有领导或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:资源消耗越大。如果在短时间内解决一个非业务或无法解决的问题的成本大于解决当前问题的收益,我认为在资金有限的情况下,没有领导或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:没有领导者或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:没有领导者或公司愿意采用解决方案。因此,考虑到成本,我们在 Log Streams 服务中引入了过滤器来过滤无价值的日志数据,从而降低日志服务使用的资源成本。技术 我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置进行动态过滤和清理的规则:
7.我们主要使用grafana做可视化界面。在它支持的众多数据源中,有Prometheus和elasticsearch,可谓与Prometheus无缝对接。而kibana主要用于apm的可视化分析
日志可视化

PS:目前UI使用的是自研的UI

