网页数据抓取怎么写(本节书摘来自异步社区《用Python写网络爬虫》第2章)
优采云 发布时间: 2022-03-29 20:20网页数据抓取怎么写(本节书摘来自异步社区《用Python写网络爬虫》第2章)
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳洲】Richard Lawson,李斌翻译,更多章节内容可参考访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方式
现在我们了解了这个网页的结构,有三种方法可以从中抓取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您是正则表达式的新手,或者需要一些提示,您可以查看它以获得完整的介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
元素中的内容,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从以上结果可以看出,标签用于多个国家属性。为了隔离 area 属性,我们可以只选择其中的第二个元素,如下所示。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父级
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,要将双引号更改为单引号,
在标签之间添加额外的空格,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 除了添加和
标签使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局的小变化,如额外的空白和制表符属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。下面是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 可以正确解析属性和关闭标签周围缺少的引号,但模块不会添加和
标签。
解析输入后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
下面是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
W3C 在 `/2011/REC-css3-selectors-20110929/ 提出了 CSS3 规范。
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在这里找到。
需要注意的是,lxml 在内部实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
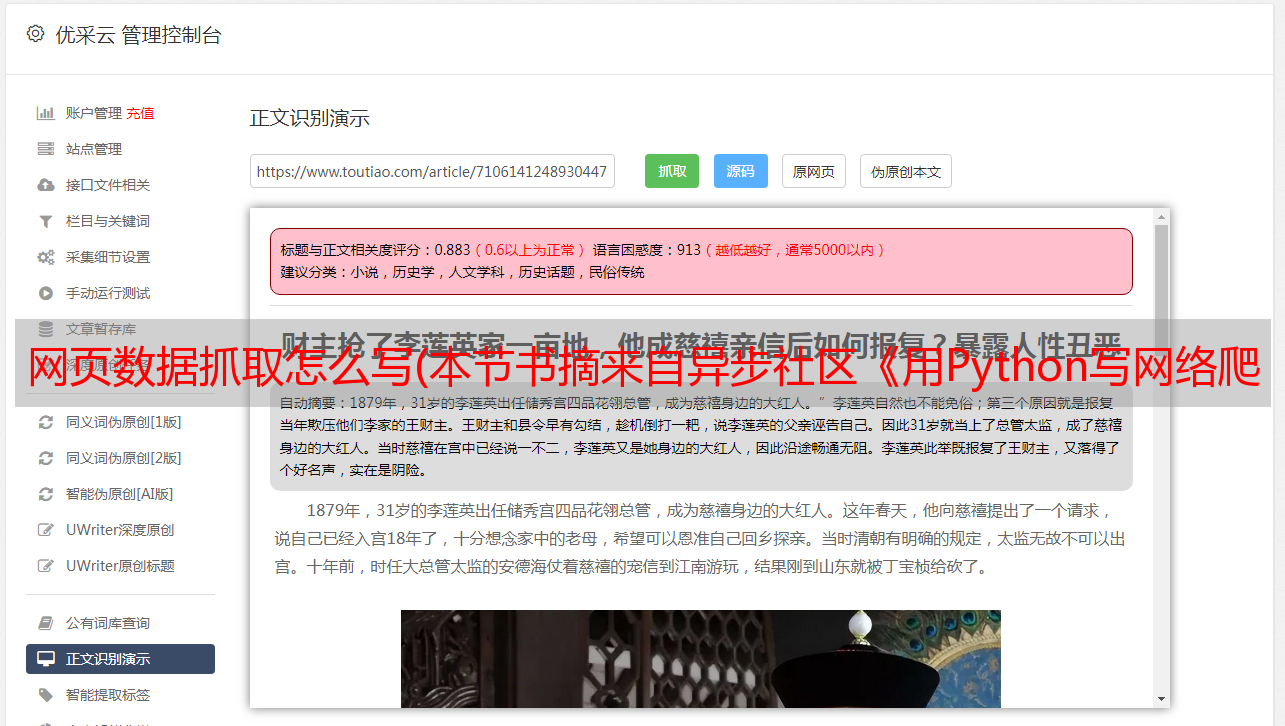
为了更好地评估本章描述的三种抓取方法的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他特征的格式,如图2.4。
从 Firebug 的显示中可以看出,表中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'nei*敏*感*词*ours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
抓取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方式的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 结论
表 2.1 总结了每种抓取方法的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些情况下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何爬取国家数据,接下来我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可以看出,用Python实现这个功能是非常简单的。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取这个版本的链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用这个爬虫来抓取其他网站了。下面对 lxml 抓取示例的代码进行了修改,以便可以在回调函数中使用它。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'nei*敏*感*词*ours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数来维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想进一步了解 Python 的特殊类方法,可以参考。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行此爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。

有效!我们完成了我们的第一个工作数据抓取爬虫。

