网页数据抓取软件(网页爬虫代码的实现思路及实现)
优采云 发布时间: 2022-03-26 11:00网页数据抓取软件(网页爬虫代码的实现思路及实现)
如今,网络爬虫代码满天飞,尤其是那些用python和PHP编写的。如果你在百度上搜索,它们都在屏幕上。不管写什么计算机语言,性能都不会相关。重要的是实现思路。
一、实施思路1、之前的思路
这是我个人的实现想法:
十多年前,我写了一个爬虫,当时的想法:
1、根据设置关键词。
2、百度搜索相关关键词并保存。
3、 遍历关键词 库,搜索相关网页信息。
4、提取搜索页面的页面链接。
5、遍历每个页面的 Web 链接。
6、抓取网络数据。
7、解析数据、构造标题、关键词、描述、内容,并合并到库中。
8、部署到服务器,每天自动更新html页面。
这里最关键的一点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
那时,当搜索引擎还没有那么聪明时,它运行得很好!百度的收录率很高。
2、当前思想数据采集 部分:
根据设置的初始关键词,从百度搜索引擎中搜索相关关键词,遍历相关关键词库,爬取百度数据。
构建数据部分:
根据原来的文章标题,分解成多个关键词,作为SEO的关键词。同理,分解文章的内容,取第一段内容的前100字作为SEO的页面描述。内容保持不变,数据被组织并存储在仓库中。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板依次生成文章内容页面、文章列表页面、网站首页。部署到服务器以每天自动更新一定数量的 文章s。
二、相关流程1.数据采集流程
1、设置关键词。
2、根据设置关键词搜索相关关键词。
3、遍历关键词,百度搜索结果,获取前10页。
4、根据页码链接,获取前10页(大概前100条数据,后面的排名已经很晚了,意义不大)
5、获取每个页面的网页链接集合。
6、根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
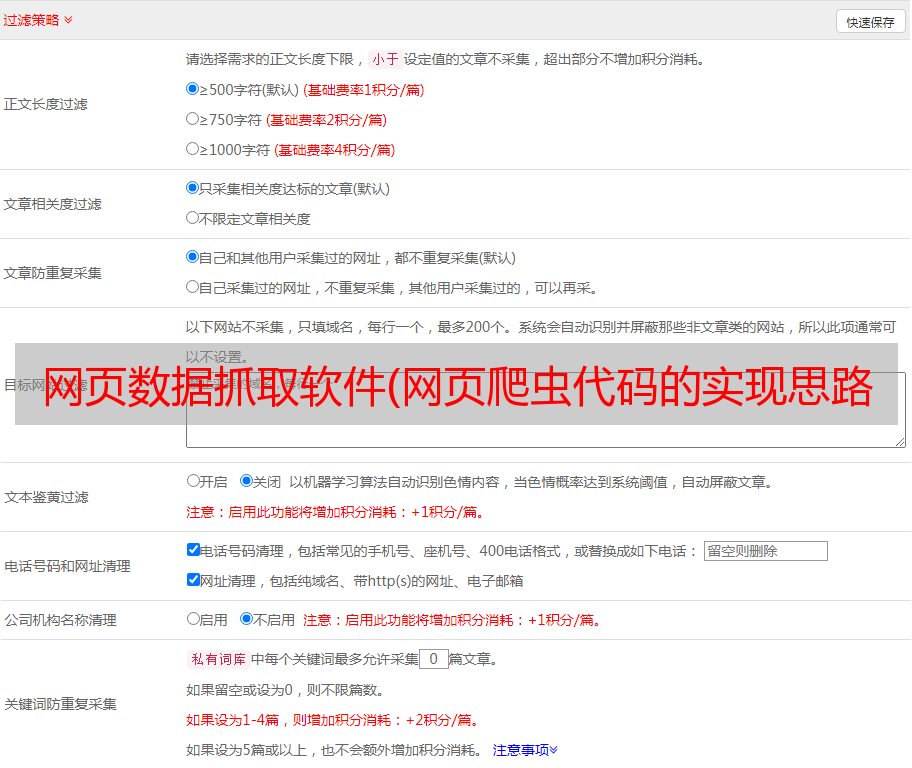
2.数据生成过程
1、初始化表(关键词、链接、内容、html数据、帖子统计)。
2、根据基础关键词抓取相关的关键词,放入库中。
3、获取链接并存储它。
4、抓取网页内容并存储。
5、构建 html 内容并存储它。
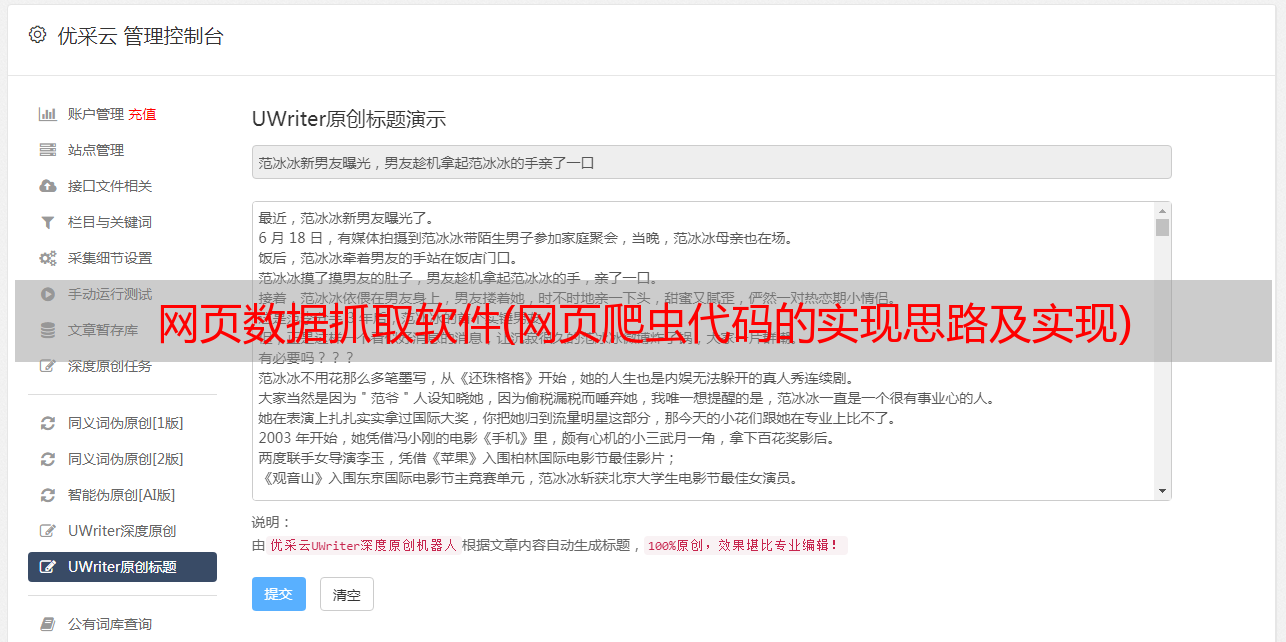
3.页面发布流程
1、从html数据表中获取从早到晚的数据。
2、创建内容详情页面。
3、创建一个内容列表页面。

