网页抓取数据百度百科(robotsrobots协议(robots.txt)Robots协议用来告知搜索引擎哪些页面能被抓取)
优采云 发布时间: 2022-03-24 10:02网页抓取数据百度百科(robotsrobots协议(robots.txt)Robots协议用来告知搜索引擎哪些页面能被抓取)
robotsrobots 协议 (robots.txt)
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽掉,比如:图片、音乐、视频等,节省服务器带宽;它可以被阻止一些指向该站点的死链接。方便搜索引擎抓取网站内容;设置 网站 地图连接来引导蜘蛛抓取页面。(来自百度百科)
** robots.txt 放置在网页上,指定搜索引擎和网络爬虫可以访问和不能访问的页面**
话题分析
进入答题页面后,直接进入url上的robots.txt
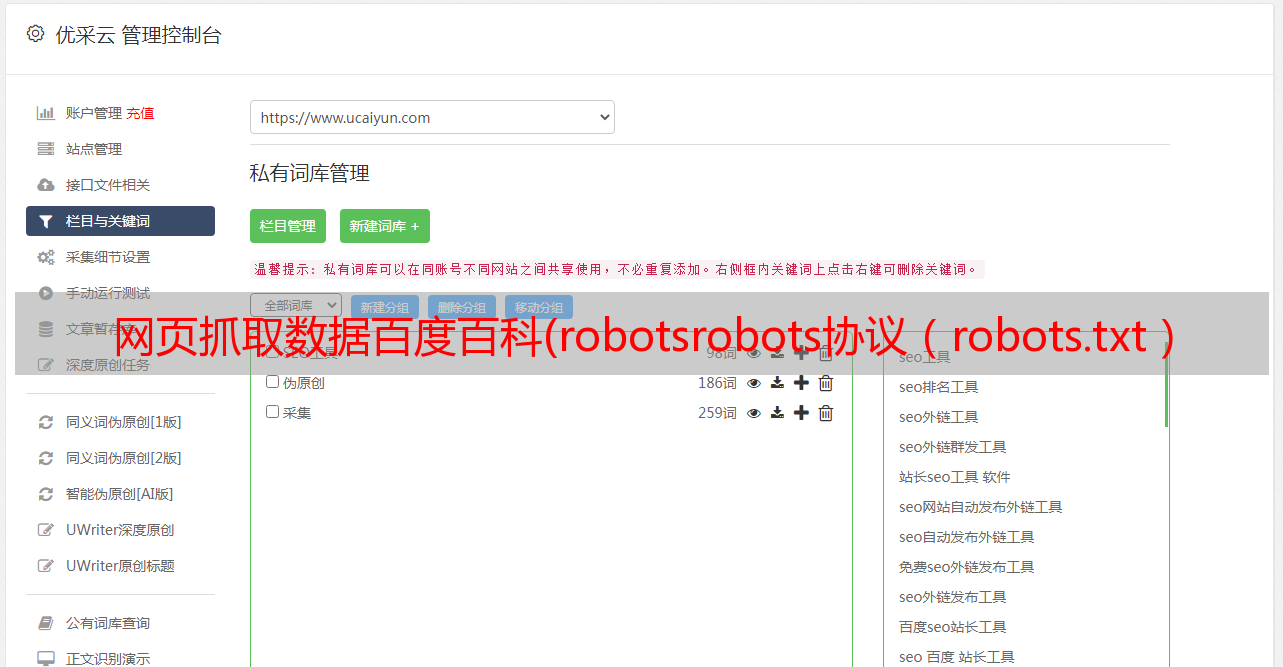
看答案
备份
网页备份
index.php的备份文件是index.php.bax,直接访问下载,然后打开查看文件,可以找到flag
cookie(存储在用户本地终端上的数据)
Cookie,类型为“小文本文件”,是为了识别用户身份和进行会话跟踪而存储在用户本地终端上的一些数据(通常是加密的),由用户的客户端计算机临时或永久存储。资料(来自百度百科)
客户端保存的一小段文本信息,用于服务器识别
话题分析
输入cookies.php查看cookies

提示“查看网页响应”,刷新网页找到网站消息头中的flag
我不知道如何在 Google 中查看它
禁用按钮主题分析
标题如下,flag不能点击
F12 发现form有disable属性,删掉点击,点击就有答案了
HTML 表单的 disabled 属性
disabled 属性可以附加到 HTML 中的输入元素、按钮元素、选项元素等。给定此属性时,元素变为非交互元素
创建一个可以按下的按钮
able
浏览器显示如下,这个按钮可以点击
disable
浏览器显示如下,该按钮无法点击
弱认证
标题如下,是一个不需要登录验证和无限次登录的登录界面。这个弱密码可以通过暴力破解获得:
只需输入一个用户名,用户名为admin,然后使用admin作为用户名进行爆破。
我在虚拟机上用 Buipsuit 爆破
首先在浏览器中设置代理
之后在浏览器中输入用户名admin,密码输入一个随机数(输入123456,直接给出答案...不过为了爆一次,换成111111)@ >,Burpsuit 会拦截它,只要你可以开始特定的爆破步骤 Action —> 发送给 Intruder
Intruder —> Positions,清理变量后,选择密码作为变量
选择的爆破方式为集束*敏*感*词*
Payloads中的Payloads set和Payloads type默认选择,也可以使用自己的字典
选择线程等开始爆破 xff referer
现在在浏览器中设置代理ip,然后使用burpsuite,我在虚拟机上做
现在在 burp 套件上捕获数据包
然后将 X-Forwarded-For:123.123.123.123 添加到响应头
回复显示“必须来自”,然后将Referer:添加到响应头以获得答案
命令执行
Ping是操作系统常用的网络诊断工具,可以用来判断连接是否建立。是一种利用IP地址的唯一性发送数据包,根据反馈数据包和反馈时间来判断连接是否建立的方法。
首先判断链接是否建立,ping127.0.0.1可以连接。
然后在127.0.0.1中查找flag文件,在ping中注入命令并使用&&逻辑符号,可以看到/中有一个flag.txt文件家
打开这个文件,你可以看到标志。
simple_js
我不知道为什么这是答案。如果有人看到它,你能帮帮我吗?
Ctrl+u查看源码
<p>
JS
function dechiffre(pass_enc){
var pass = "70,65,85,88,32,80,65,83,83,87,79,82,68,32,72,65,72,65";
var tab = pass_enc.split(',');
var tab2 = pass.split(',');var i,j,k,l=0,m,n,o,p = "";i = 0;j = tab.length;
k = j + (l) + (n=0);
n = tab2.length;
for(i = (o=0); i

