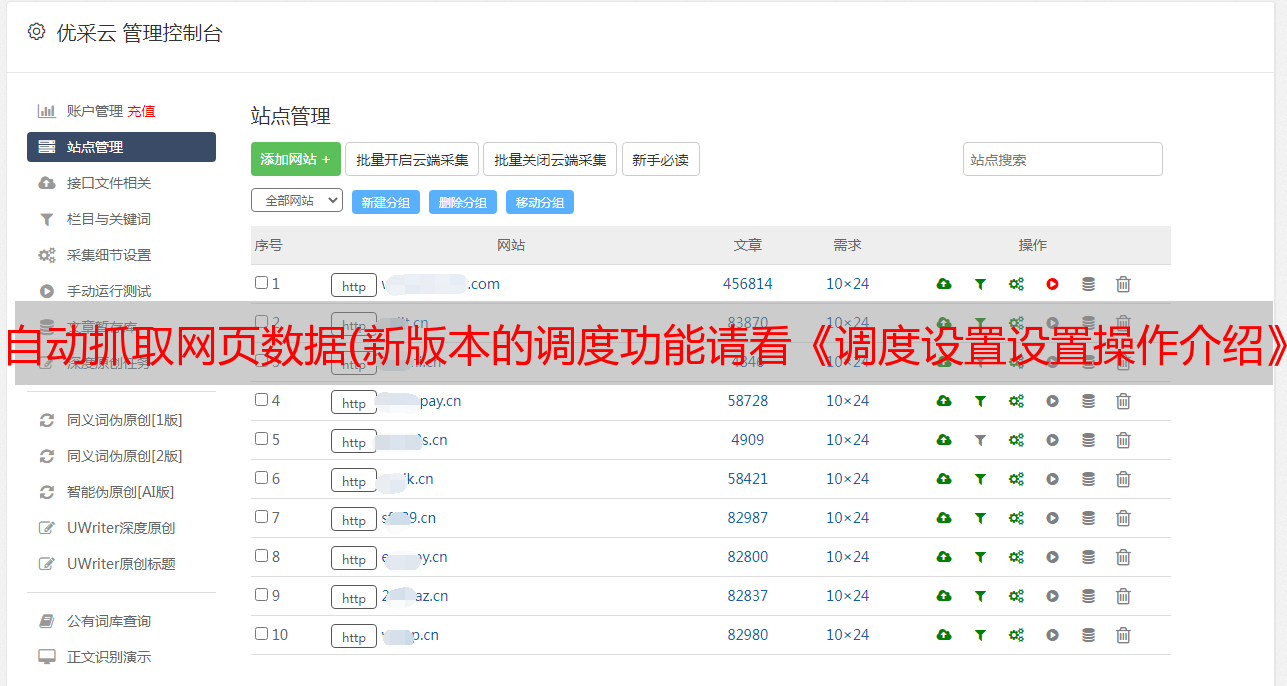
自动抓取网页数据(新版本的调度功能请看《调度设置设置操作介绍》 )
优采云 发布时间: 2022-03-20 22:25自动抓取网页数据(新版本的调度功能请看《调度设置设置操作介绍》
)
下面是老版本的调度功能界面。新版调度功能请参考《调度设置介绍》
1 使用场景
这些只要开启爬虫群模式就可以实现。爬虫分组模式采用简单的图形界面,只需点击几下鼠标即可自由控制爬虫,实现采集数据的自动智能调度,真正实现大爬虫的概念,让你的采集数据更高效方便。
2 关于爬行动物
爬虫群模式是在一台电脑上同时开启多个爬虫(即DS计数器窗口)。通过设置更多的爬虫数量和合理的爬取速度,不仅降低了IP被封的风险,还可以抓取更多的数据,是一种非常稳定高效的原生采集模式。它集成了crontab爬虫调度器、DS计数器主要功能、数据库存储三大功能块。简单易用的图形界面操作,无需编程基础,100%权限开放,让您自由控制爬虫数量和操作,专属数据库,高效处理千万级数据,转换数据轻松快速地格式化。
爬虫组和规则制定可以同时操作,但是爬虫组只能采集调度池中的规则。如果你想自动采集 任何规则,它将被扔到调度池中。调度池等价于一个指挥中心,采集任务会自动分配给每一个爬虫,所以运行爬虫组、制定规则、调度这三个步骤是必须的,并且三者没有先后顺序.
如上图所示,与没有爬虫组的工作模式相比,爬虫组的使用过程如下:
准备阶段完成后,只需制定抓取规则,扔一个到调度池中,就不用担心爬虫的启动,调度系统会自动将抓取任务分配给空闲的爬虫。当爬取规则比较多的时候,就不用担心 crontab 爬虫调度器的编写了。可见,非常适合使用大量爬取规则,运行大量爬虫的场景。
准备阶段完成后,您应该看到如下图的爬虫组都处于待命状态。
可以看到,GooSeeker社区的会员中心和爬虫软件已经整合成一个“大爬虫系统”。爬虫软件是一个执行组件,会员中心就像一个大脑,是一个命令组件。单击以阅读有关如何运行爬虫群的更多信息。
如有疑问,您可以或