采集免费文章网站(微博指数新闻网站模板带采集、微信、搜狗指数)
优采云 发布时间: 2022-03-17 16:18采集免费文章网站(微博指数新闻网站模板带采集、微信、搜狗指数)
热点指数
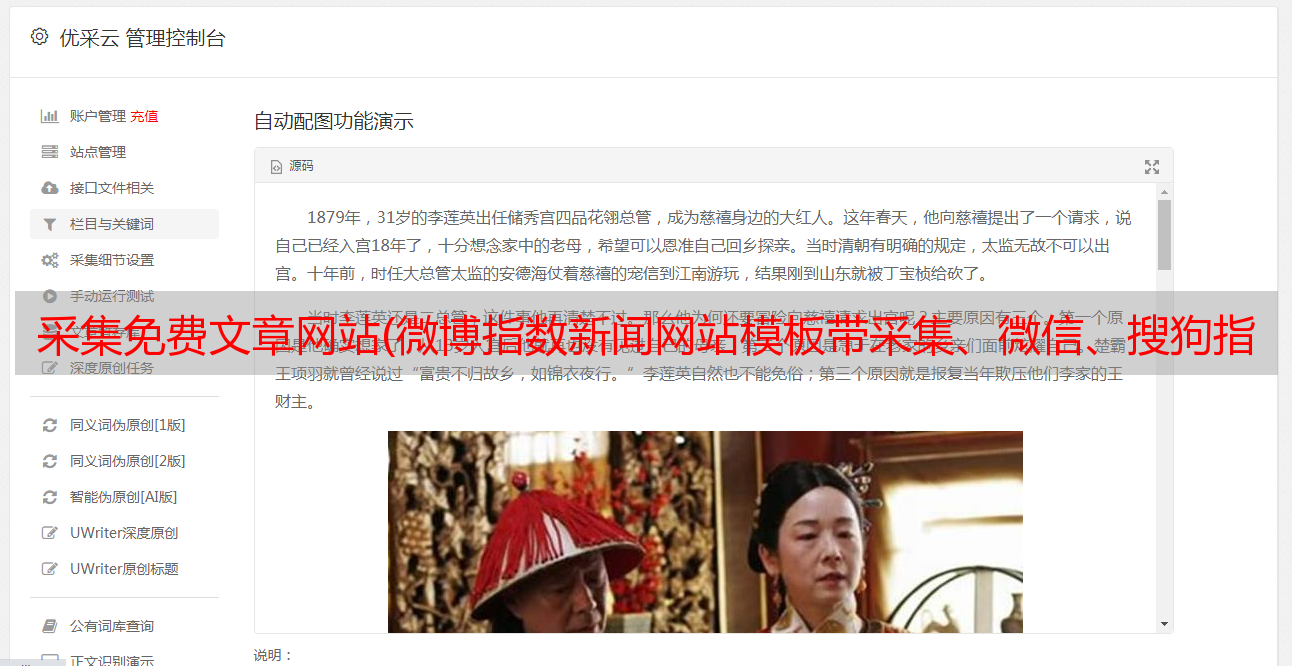
1、微博指数新闻网站带有采集的模板:/index
2 新闻网站模板带采集,微信索引:微信搜索微信索引小程序
3、百度指数新闻网站模板与采集::///#/
4、头条索引新闻网站模板与采集::///
5 新闻 网站 模板与 采集,搜狗指数:/
公众号小助手
1、西瓜助手:/
2、新媒体经理::///index
3、合伙人:://yiban.io/
4、主机:/
5、新排名助手::///public/about/plugIn_introduce.html
6、滴滴微平台:://drip.im/
7、小宝:/
自动采集其他人的消息网站?
是的。自动 采集 功能。东一2006项目管理:1、选择添加新项目,找到你需要的页面采集→复制网址到新闻网址列表框,随便填项目名(主要是给自己要记住备忘录)→下一步2、项目编辑列表设置:在这里填写,注意,找到你想要的新闻列表的第一个信息标题的地方采集,一般会有一个标题前面的表格标签。在表格标签前面选择一些具有典型特征的代码。应该选择多少个代码?有两种情况。一种是分页列表。1、2、3、等页面或页面链接,二是没有分页。简单来说,列表只有一页,只有一页的情况很容易处理。你可以在这里选择它。,只要保证不重复。
但是,带有分页的列表页会比较麻烦。这时候选码的原则是:在保证没有重复码的前提下,尽量少选码,因为码越多越容易出错,对每个列表页的保证也就越少。这些代码都有。这是经验问题。当然,也不一定。有些网页的代码格式很统一,所以这种网页不错采集,也比较容易填写列表起始码。什么是具有典型特征的代码?它基本上是每个列表页都有的代码,但是这个页码在所有列表页中是唯一的,不会重复。
如何采集页面数据?复制和粘贴?
如何采集页面数据?你说复制粘贴,纯属胡说八道
网页数据主要来自网络接口和静态文件。对于采集这些数据,主要是通过解析文件和接口数据获得。不同网站的界面约定和页面结构是不同的。如果要采集@采集很多网站,其实挺麻烦的
具体实现可以自己写爬虫程序,也可以使用一些工具,比如优采云、优采云采集器等,都提供了一些免费的功能,你可以< @采集百度、新浪等知名网站资料,自己玩玩就够了,还有付费的采集,他们会帮你做模板,自定义采集@ > 为你
总之,网站采集不难,就是烦,谢谢

