seo攻略——搜索引擎优化策略与实战案例详解(Python分布式爬虫必学框架ScrapyCore核心RDD(免费分享))
优采云 发布时间: 2022-03-16 19:06seo攻略——搜索引擎优化策略与实战案例详解(Python分布式爬虫必学框架ScrapyCore核心RDD(免费分享))
Python3实战Spark大数据分析调度
搜索QQ号直接进群获取其他学习资料:517432778
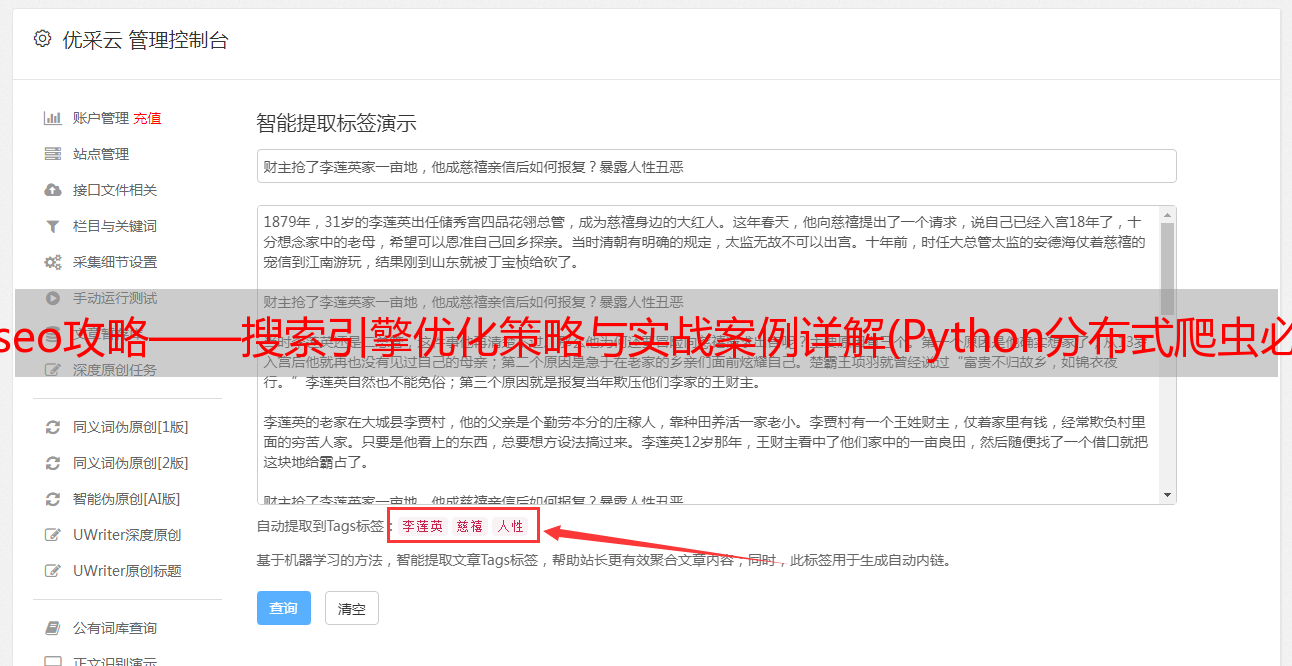
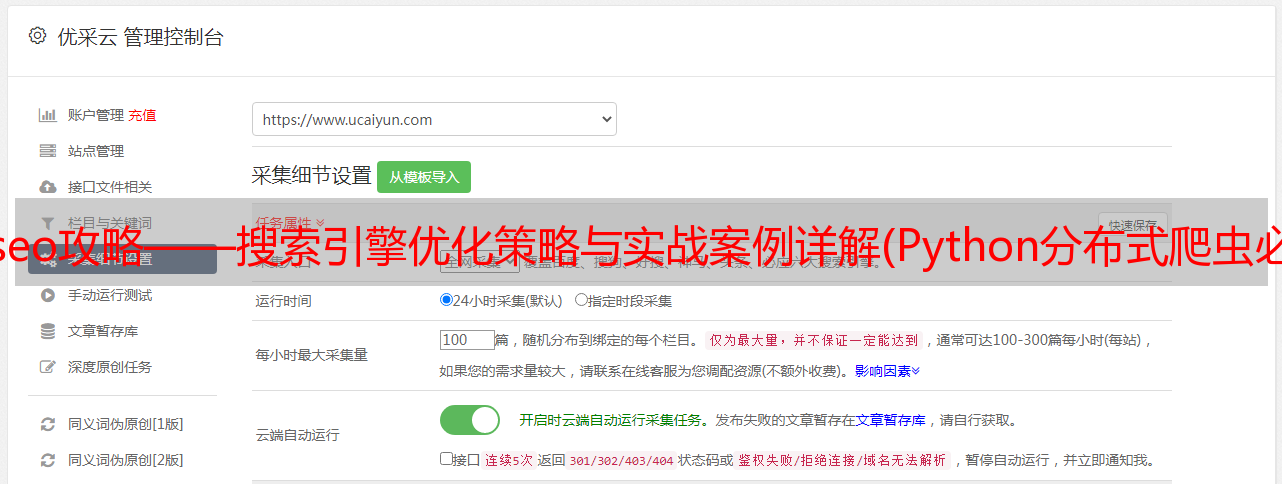
部分课程截图:
提取码:z5xv
PS:免费分享,点击链接获取不到信息,链接失效请进群
其他资源在群里,私聊管理员可以免费获取;群 - 517432778,点击添加群,或扫描二维码
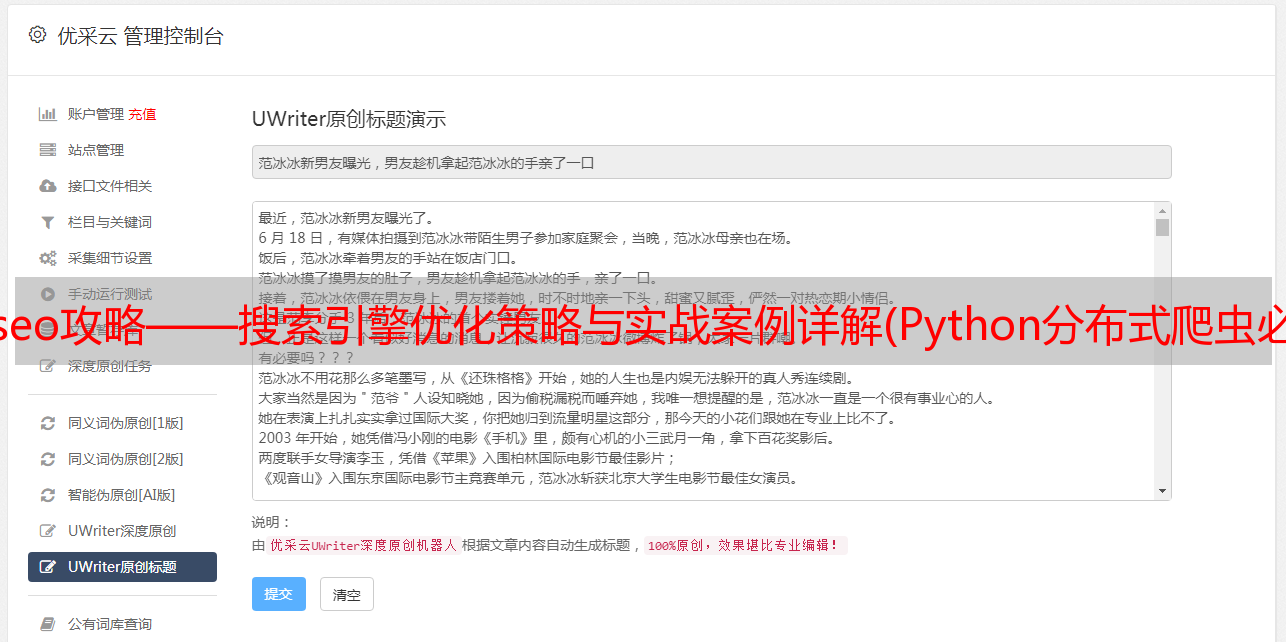
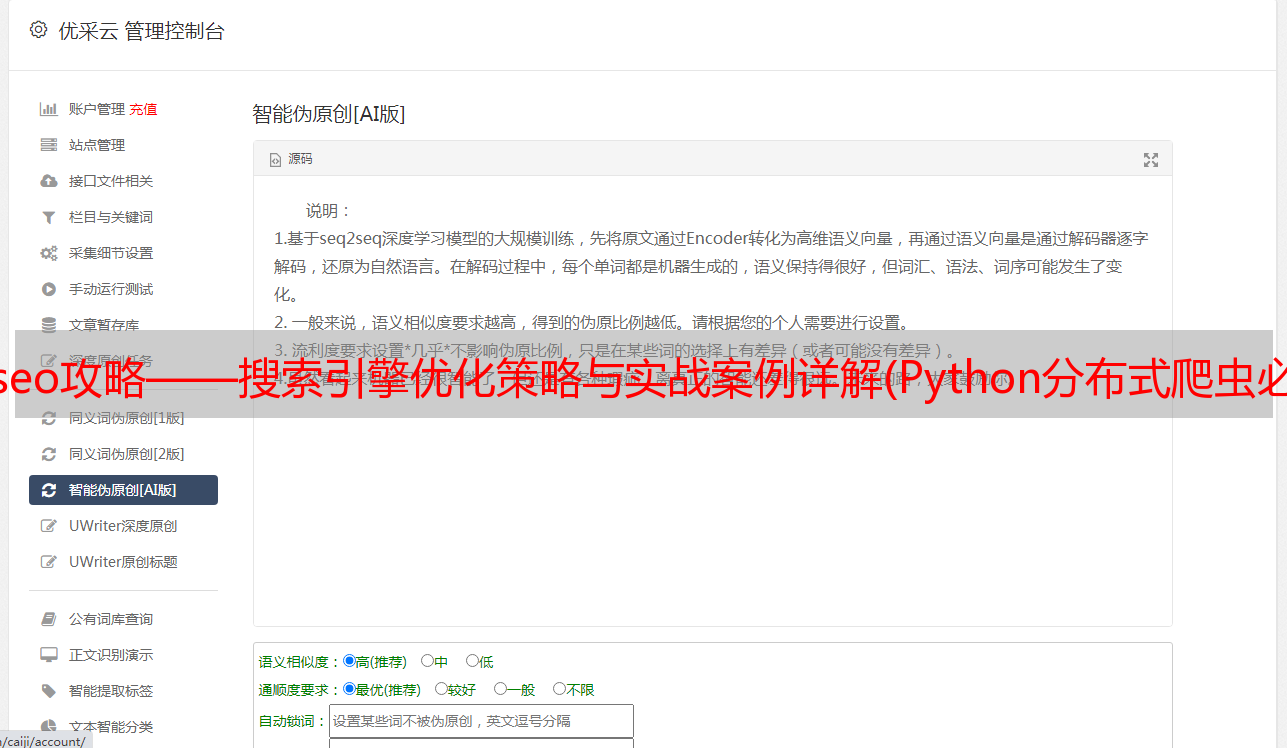
免费课程资料采集目录:
Python Flask 搭建微信小程序点餐系统
Python分布式爬虫必须学习框架Scrapy来创建搜索引擎
PythonFlask进阶编程之RESTFulAPI前后端分离(免费分享)
第二章 实战环境建设
要想做好,首先要磨砺自己的工具。本章介绍JDK、Scala、Hadoop、Maven、Python3和Spark源码的编译和部署。
第 3 章 Spark Core 核心 RDD
本章详细讲解RDD是什么及其特点(常见访谈),Spark中的两个核心类SparkContext和SparkConf,pyspark启动脚本分析,RDD是如何创建的,如何使用IDE开发Python Spark应用并提交到运行服务器
第 4 章 Spark Core RDD 编程
本章将对RDD常用的算子进行详细案例讲解,并进行综合案例实战。
第 5 章 Spark 操作模式
本章将介绍 Spark 的几种运行模式,需要重点关注 on YARN 模式。
第6章高级Spark核心
本章将介绍 Spark 中的核心术语、运行架构,并比较 Spark 和 MapReduce 的概念区别、存储策略和选择方法、宽窄依赖以及 Shuffle。
第 7 章 Spark 核心调优
本章将从 Spark 作业性能指标、序列化、内存管理、广播变量、数据本地化等方面介绍 Spark 作业调优。
第 8 章 Spark SQL
本章将解释 Spark SQL 模式、DataFrame 和 Dataset,以及如何使用 Python API 编程 DataFrame
第 9 章 Spark Streaming
本章将解释 Spark Streaming 的核心概念、执行原理以及如何使用 Python API 编写 Spark Streaming
第10章阿兹卡班基础
本章将讲解Azkaban的特点、架构、运行模式、源码编译部署、快速上手
第11章阿兹卡班在行动
本章将讲解如何使用 Azkaban 完成 HDFS、MapReduce、Hive 作业调度、定时作业调度和电子邮件警报
第12章 阿兹卡班进阶
本章将讲解Azkaban在生产中的部署、权限管理、Ajax API、Plugin,以及短信和调度框架的二次开发
第十三章项目实践
本章将讲解搭建大数据平台的技术选型,集群升级资源评估,使用Spark分析气象数据,将分析结果写入ES,通过Kibana将统计结果可视化

