实时抓取网页数据(思通舆情的功能:思通、开发计划、UI展示架构说明)
优采云 发布时间: 2022-02-23 22:07实时抓取网页数据(思通舆情的功能:思通、开发计划、UI展示架构说明)
四通舆论的作用:四通舆论的优势:四通舆论的数据:四通舆论的百科全书:
关于本次舆情系统项目的思路、发展规划、介绍文件、团队介绍、实战案例等,
你想知道的都在这里:
四通舆情技术栈:UI展示
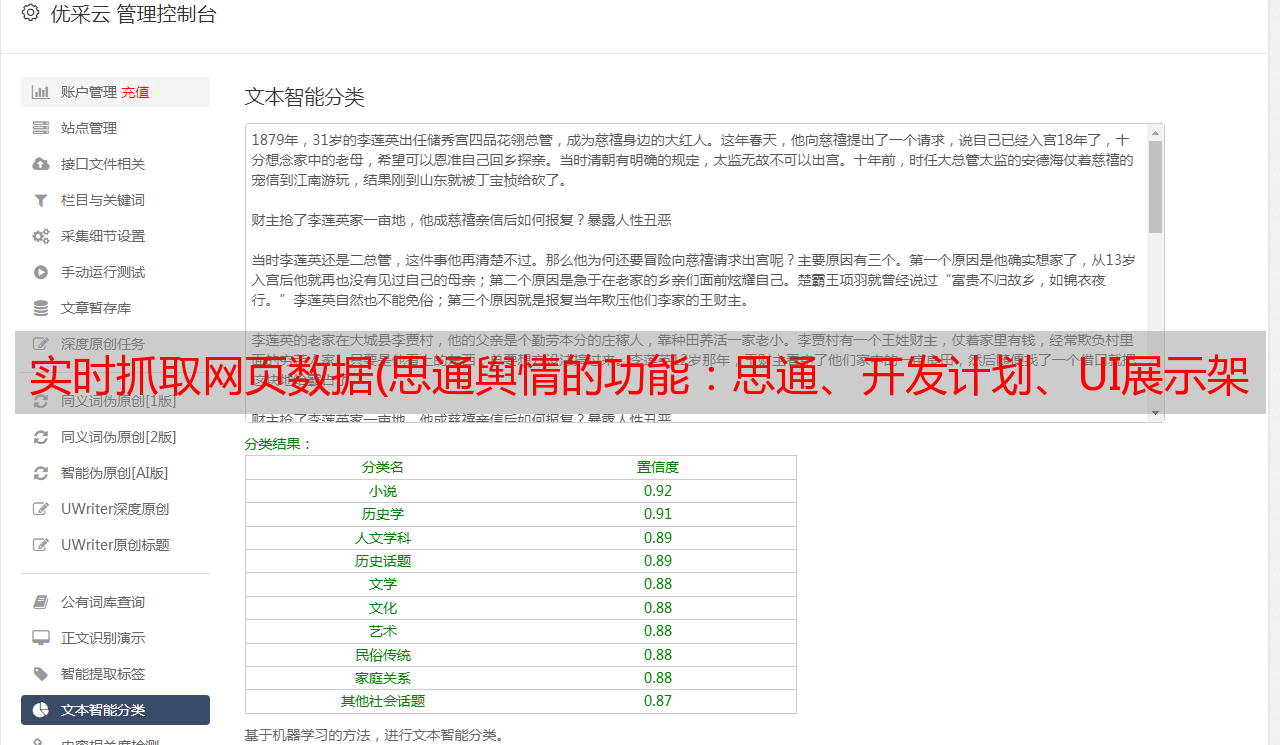
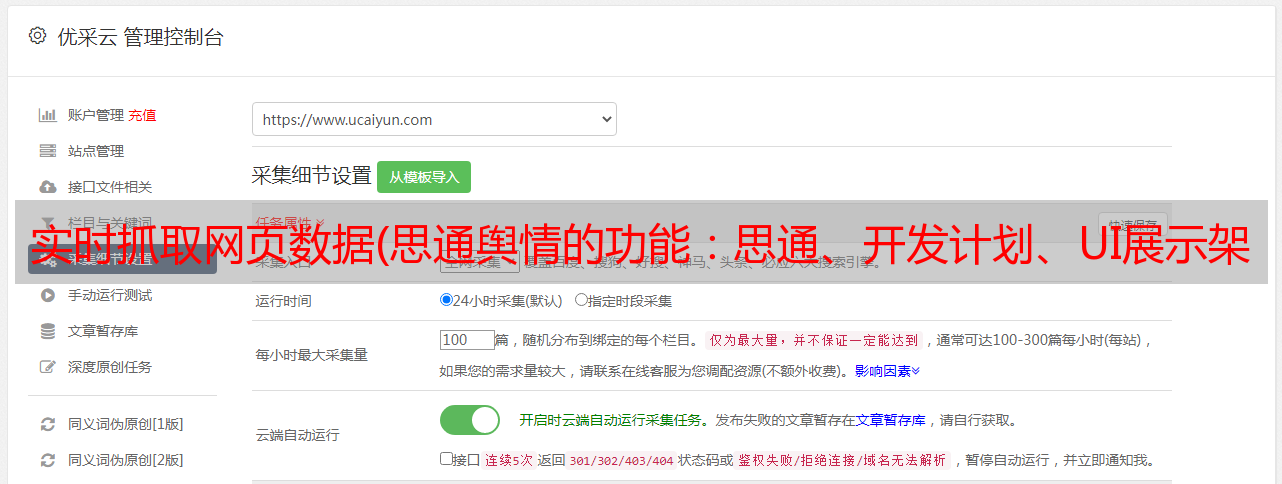
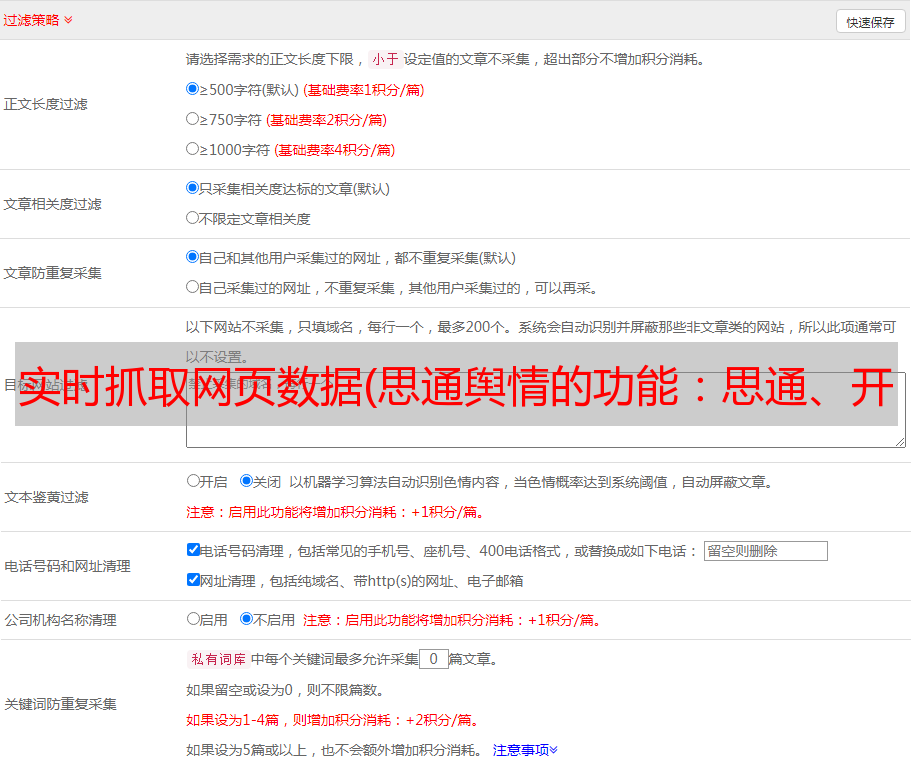
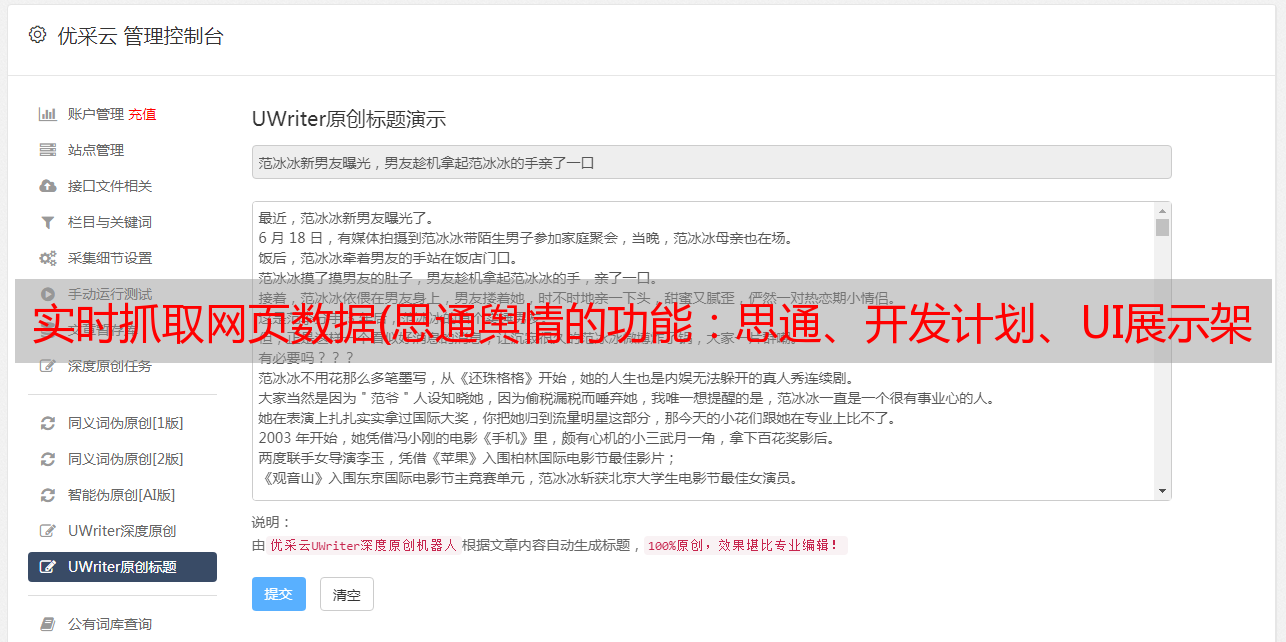
系统采集架构说明
舆情系统中的数据采集是关键部分。虽然这部分核心技术是由爬虫技术框架构建的,但绝不是一两个爬虫程序就可以处理海量的互联网数据,尤其是在抓取大量网站的情况下,每天大量网站状态和样式变化后,爬虫可以快速响应和维护。
一旦分布式爬虫规模大了,就会出现很多问题,都是技术上的挑战,会有很多门槛,比如:
1.检测到你是爬虫,屏蔽你的IP
2 人家返回脏数据给你,你怎么识别?
3 对方被你杀了,调度规则怎么设计?
4 一天需要爬10000w的数据,你的机器带宽有限。如何以分布式方式提高效率?
5 数据爬回来的时候,要清理吗?对方的脏数据会不会污染原创数据?
6 对方部分数据未更新。您是否必须重新下载这些未更新的?如何识别?如何优化你的规则?
7 数据太多,一个数据库放不下,要不要拆分数据库?
8 对方的数据是用JavaScript渲染出来的,那么怎么抓拍呢?你想使用 PhantomJS 吗?
9 对方返回的数据是加密的,怎么解密?
10 对方有验证码,怎么破解?
11 对方有APP,如何获取他们的数据接口?
12 如何显示数据?你如何形象化它?你如何使用它?你如何利用它?
13 等等……
在*敏*感*词*的互联网数据采集中,需要构建完整的数据采集系统。否则你的项目开发效率和数据采集效率会很低。同时,也会出现很多意想不到的问题。
开源技术栈的整体架构
(这是最早的系统架构图)
数据处理流程
(这是最早的系统设计图)
源头管理
信息源,信息源的简称。我们需要管理采集类型、内容、平台、区域等各种属性,为此我们开发了三代源码管理平台。
代产品形式
二代产品形态
三代产品形态
现场肖像
采用模拟浏览器请求技术实现深度和广度爬取算法。整体分为3个环节。整个站点被1)扫描、2)数据存储和3)特征化。
数据抓取
数据分期低代码开发
分布式采集爬虫管理采集分类反爬虫策略采集日志数据解析数据存储异步调用
数据通过kafka中间件以消息的形式发送到存储终端系统。

