网页表格抓取( 终端窗口查询全国3400多个区县当日天气信息和近七天信息)
优采云 发布时间: 2022-02-12 23:03网页表格抓取(
终端窗口查询全国3400多个区县当日天气信息和近七天信息)
写一个爬中国天气网的终端版天气预报爬虫
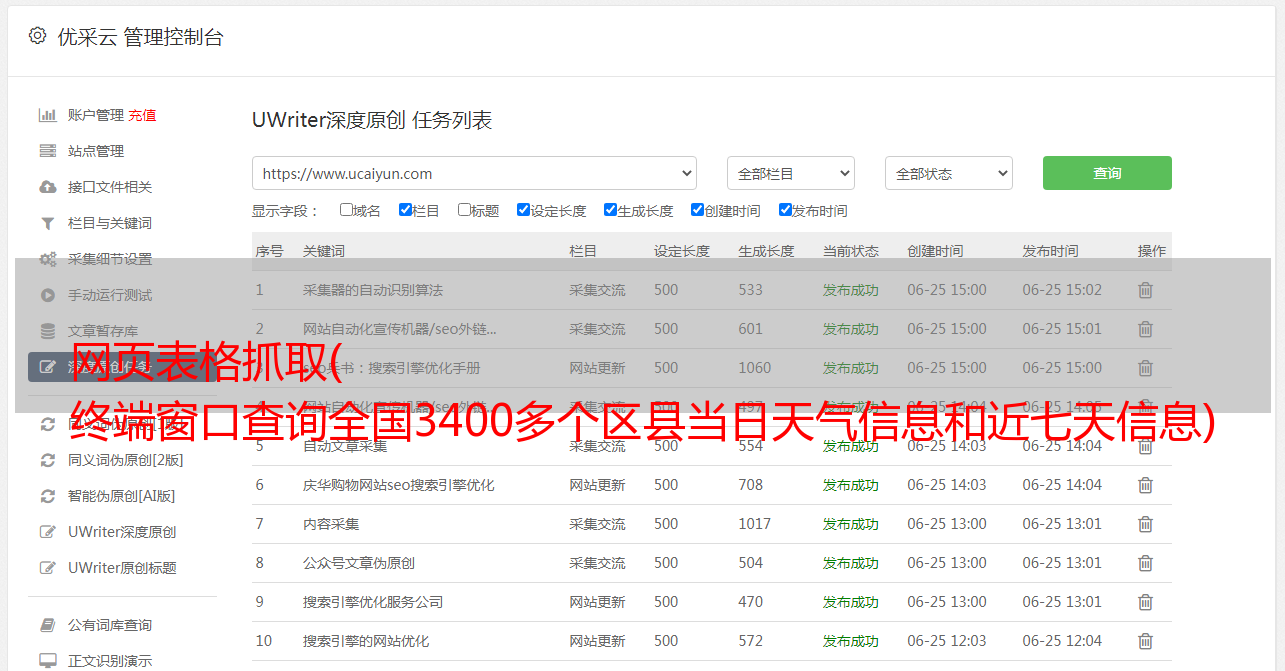
前几篇文章介绍了爬取静态网站的主要方法。今天写一个小项目来练习。本项目可在终端窗口查询全国3400多个区县当天及过去7天的天气信息。实现获取原创链接文件的效果:在公众号Thumbnote后台回复“天气预报”即可获取相关节目和城市id文件。使用方法:在终端窗口运行程序,输入要查询的区县名称(如:丰台、静安等)。相关模块 pandas:读取城市 ID 文件 prettytable:输出 ASC 样式表 bs4:解析网页 天气信息存储在不同的网页中,其 url 如下
现在下载
wiki-scraper:从维基百科中抓取表格和其他信息 - 源代码
Wikicrawler 这是一个简单的脚本,它从 Wikipedia 抓取数据表以安装所需的软件包: pip install beautifulsoup4, pip install pandas 这个例子从一个城市的大都市区抓取人口数据。输出 .dat 文件由双冒号分隔。基于 ADEsquared 的教程::///2013/06/16/using-python-beautifulsoup-to-scrape-a-wikipedia-table/
现在下载
Python 读取文本中的数据并将其转换为 DataFrame 的实例
在一次技术问答中看到这样的问题,觉得比较常见,所以就点开一篇文章文章写下来。从纯文本文件“file_in”中读取数据,格式如下:需要输出到“file_out”,格式如下:数据的原创格式为“category: content”,空行“ \n"作为条目,转换后变成一个条目一行,内容按类别顺序写出。建议看完后使用pandas将数据构建成一个名为DataFrame的表。这使得以后处理数据更容易。但是原创格式不是通常的表格格式,所以先做一些简单的处理。#coding:utf8import sysfrom pandas import DataFrame #DataFrame 通常用于加载二维表导入
现在下载
双色球的单线程爬行网站.py
通过pandas爬表,可供个人测试,爬取双色球网站的所有数据。注意:抓取访问为csv格式,可以在excel中读取,但建议在excel中编辑后保存为xlsx格式,否则会造成混乱。
现在下载
pandas 实现了一种对重复表进行去重并重新转换为表的方法
在python中处理数据时,经常使用DataFrame和set。train=pd.read_csv('XXX.csv')#读取文件 train=train['item_id']#选择要重复的列 train=set(train)#删除数据=pd.DataFrame(list(train) , columns=['item_id'])#因为集合是无序的,所以必须经过列表处理才能成为DataFramedata.to_csv('xxx.csv',index=False)#保存表格记得导入pandas~以上文章Pandas实现了对重复表进行去重再转表的方法。小编分享给大家。
现在下载
Matplotlib图形化分析猪肉价格上涨趋势,pandas数据处理
1.爬取新发地果蔬价格csv,上一张表的内容,爬取新发地果蔬价格并保存为csv格式,筛选出毛猪和白条猪,< @2. 筛选分析猪肉价格,使用matplotlib库制作趋势图#pandasimport pandas as pd #导入数据处理工具pandasimport matplotlib.pyplot as plt#导入图形展示工具matplotlibdataframe = pd.read_csv(新菜价.csv, header=None)#print(dataframe )#获取数据 fei = dataframe[dataframe[0] == 白猪(胖)]shou =
现在下载
300hero_report:300英雄记录查询-源码
300英雄记录查询一个爬虫+一个GUI来下载数据并找到一种显示方式。scrapy PyQt matplotlib 还没有完成。操作方法为python 300hero.pyTODO,防止爬取重复信息数据,存入本地库。查询时,优先从本地库中获取。当你点击某个会话时,会弹出一个对话框,显示该字段的详细数据,并使数据显示更规则(可能你需要pandas和matplotlib)加点图表(组分数变化图表...)多窗口(点击显示详细战况)然后一个网页端具体游戏数据,不再使用爬虫,使用api获取Bug 重复查询会报错 twisted.internet.error 。
现在下载
使用xpath爬取链家租房数据并使用pandas保存到Excel文件
<p>我们的需求是使用xpath爬取链家的租房数据,并通过pandas将数据保存到Excel文件中。我们来看看链家官网的上市信息(以北京为例)。如图,我们通过筛选得到北京。出租信息然后我们需要通过爬虫提取房屋面积、小区名称、户型、面积、朝向、价格等信息。思考步骤:1.通过翻页,我们看到总页数是100页,那么我们需要通过format方法获取100个url地址列表url_list;

