网页新闻抓取(为什么要做提取一般做舆情分析,正文提取的好坏 )
优采云 发布时间: 2022-02-08 08:08网页新闻抓取(为什么要做提取一般做舆情分析,正文提取的好坏
)
为什么要提取文本
一般来说,舆情分析都会涉及到网页内容的提取。对于分析,有价值的信息是身体部分。大多数情况下,为了便于分析,需要将网页中与正文无关的部分去掉。可以说,文本提取的好坏直接影响分析结果的好坏。
对于具体的网站,我们可以分析其html结构,根据其结构获取body信息。看看下面的图片:
在body部分,不同的网站,body的位置不同,Html的结构也不同。对于爬虫来说,要爬取的页面是多种多样的,不可能对所有页面都写爬取。规则来提取文本内容,因此需要一个通用的算法来提取文本。
现有网页文本提取算法
前两种方法比较容易实现,主要是处理简单。之前实现过标签密度提取算法,但是实际中错误率还是挺高的;后两种方法在实现上稍微复杂一些。算法效率应该不会高很多。
我们需要的是一种简单且易于实现的算法,可以保证处理速度和良好的提取精度。因此,结合前两种算法,研究网页的html页面结构,有一个更好的处理思路,称为基于文本密度的文本提取算法。后来在网上找了一个类似的算法,发现也有类似的处理文本提取的处理方法,但还是有些不同。接下来给大家分享一下这个算法的一些处理思路。
网页分析
我随便从百度、搜狐、网易拿了一个新闻页面,拿来分析。
先看一个百度文章
任正非为什么要主动和我合影?
先请求这个页面,然后过滤到所有的html标签,只留下文本信息,我们可以看到body信息集中在以下几个位置:
使用Excel分析行数与每行字符的关系可以发现:
显然,文本内容集中在65-100行之间的位置,这个区间的字符数比较密集。
网易的另一篇文章文章
张小龙的神话破灭了,马化腾接手微信的时候到了。
或者先过滤html标签后看body部分:
另一个Excel分析结果:
文本部分集中在第 279-282 行之间。从图中可以看出,正是这些行具有特别高的文本密度。
搜狐新闻最后分析
李克强在天津考察考察期间的几个瞬间,
或者看一下标签后面的文字:
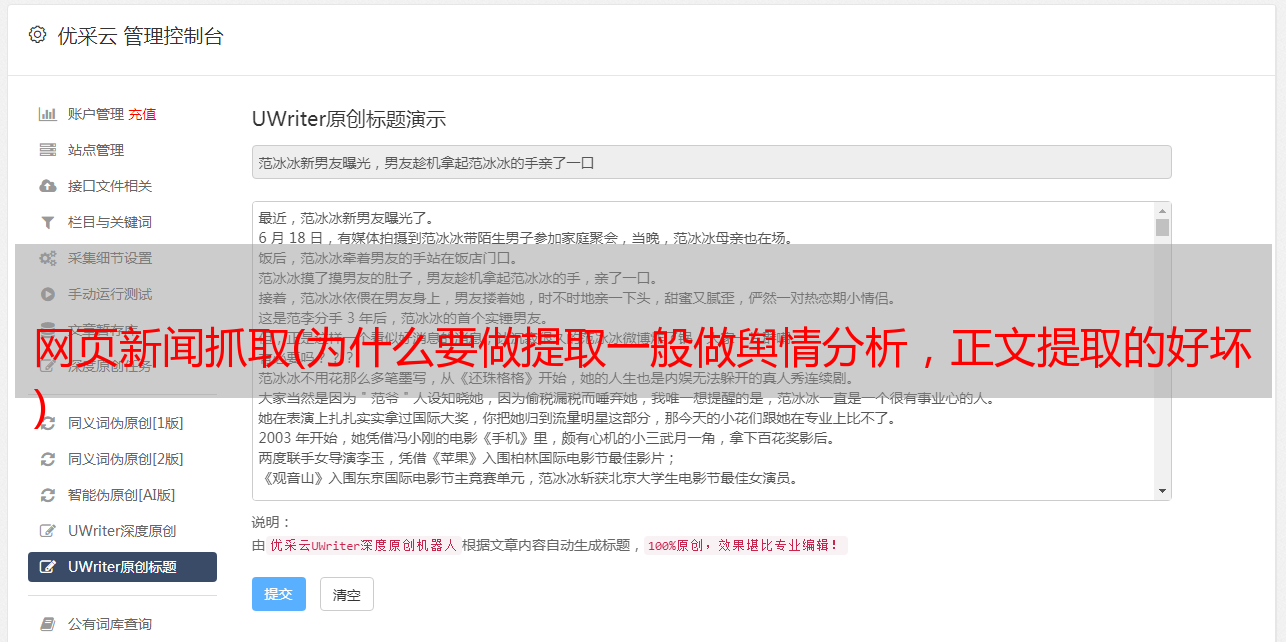
看一下Excel中的分析结果:
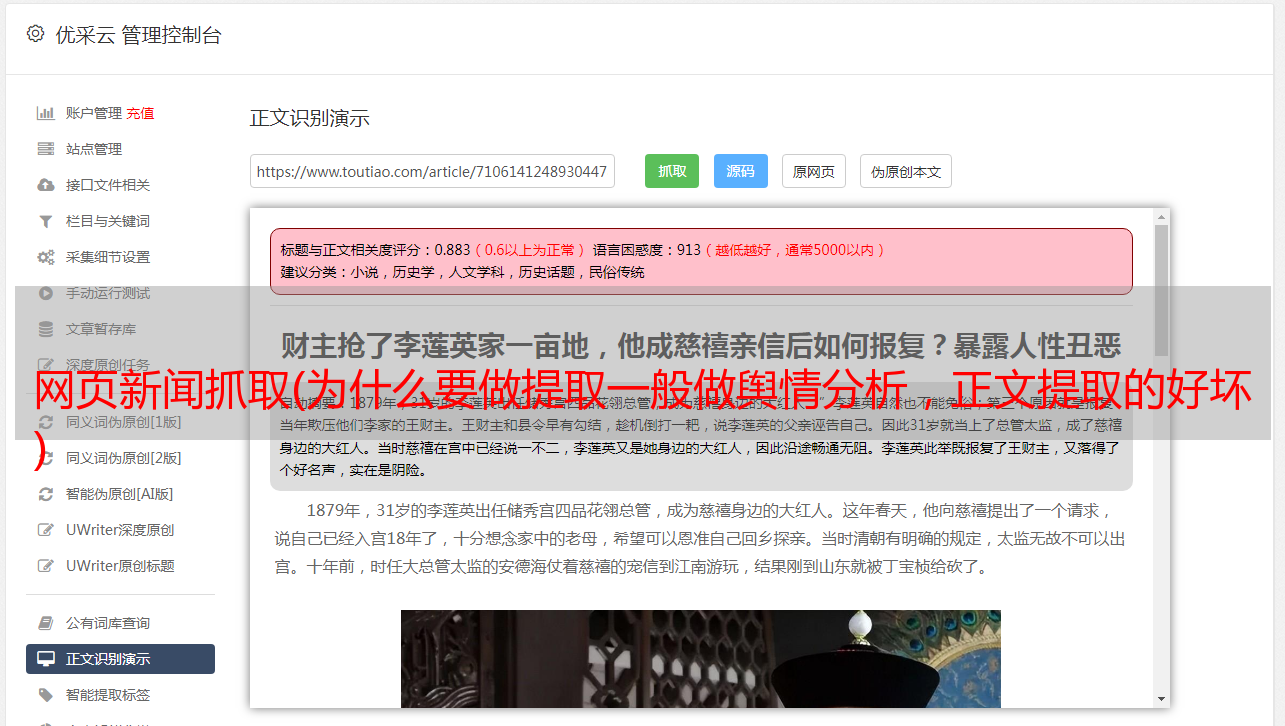
而搜狐的文章正文部分主要集中在200-255行之间。其余的文字都是杂乱无章的标签文字。
对不起,我漏掉了一个很重要的解释:为什么我们在分析的时候要过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关注的是body的内容。如果有这样的标签 style="color: #0000ff;">varchart =style="color: #0000ff;">newstyle="color: #000000;">来分析一下,可以想象会干扰到我们的文字分析,这就是为什么需要去掉html标签,只分析文本以减少干扰。
基于网页分析的文本提取算法
回顾上面的网页分析,如果按照文本密度提取文本,那么编写一个算法,可以从过滤html标签后的文本中找到文本的起止行号,以及文本之间的文本行号是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文字密度远高于非正文部分。根据这个特性,我们可以很容易地实现算法,即根据阈值(发音:yu)值来分析文本的位置。
那么需要解决一些问题:
阈值的确定可以通过统计分析得到一个较好的值。在实际处理过程中,我发现这个值是180比较合适,也就是在分析文本的时候,如果分析出来的文本超过180,那么就可以认为达到了body部分。
然后是如何分析的问题。这实际上是比较容易确定的。逐行分析的效果肯定不好。如果在逐行分析的过程中分析多行,效果会更好。也就是说,一次分析5行左右,把字符加起来,看看是否达到了设定的阈值。如果达到,则认为已进入文本部分。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
<p>int preTextLen = 0; // 记录上一次统计的字符数量(lines就是去除html标签后的文本,_limitCount是阈值,_depth是我们要分析的深度,sb用于记录正文)int startPos = -1; // 记录文章正文的起始位置for (int i = 0; i < lines.Length - _depth; i++){ int len = 0; for (int j = 0; j < _depth; j++) { len += lines[i + j].Length; } if (startPos == -1) // 还没有找到文章起始位置,需要判断起始位置 { if (preTextLen > _limitCount && len > 0) // 如果上次查找的文本数量超过了限定字数,且当前行数字符数不为0,则认为是开始位置 { // 查找文章起始位置, 如果向上查找,发现2行连续的空行则认为是头部 int emptyCount = 0; for (int j = i - 1; j > 0; j--) { if (String.IsNullOrEmpty(lines[j])) { emptyCount++; } else { emptyCount = 0; } if (emptyCount == _headEmptyLines) { startPos = j + _headEmptyLines; break; } } // 如果没有定位到文章头,则以当前查找位置作为文章头 if (startPos == -1) { startPos = i; } // 填充发现的文章起始部分 for (int j = startPos; j

