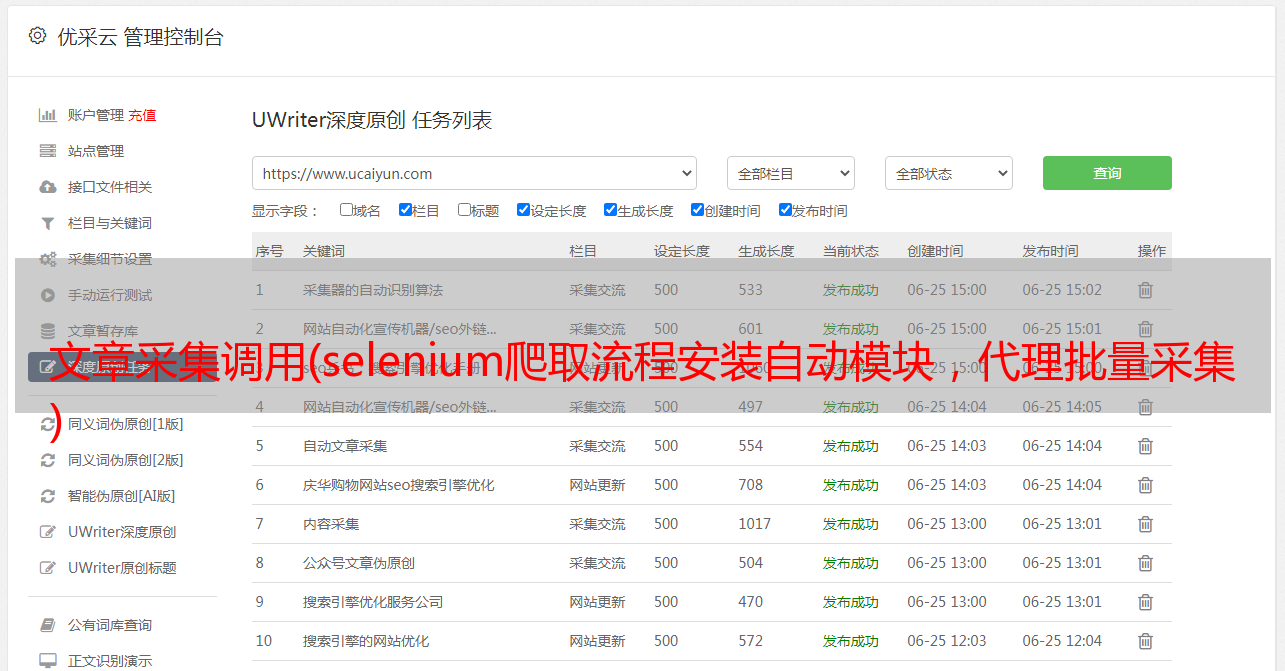
文章采集调用(selenium爬取流程安装自动模块,代理批量采集 )
优采云 发布时间: 2022-02-01 07:02文章采集调用(selenium爬取流程安装自动模块,代理批量采集
)
硒爬行过程
安装python selenium自动模块,使用selenium中的webdriver驱动浏览器获取cookies登录微信公众号后台;
使用webdriver功能需要安装对应浏览器的驱动插件。
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。
微信公众号登录地址:
微信公众号文章的接口地址可以在微信公众号后台创建,可以从超链接函数中获取:
搜索公众号名称
获取要爬取的公众号fakeid
选择要爬取的公众号,获取文章的接口地址
文章列表翻页和内容获取
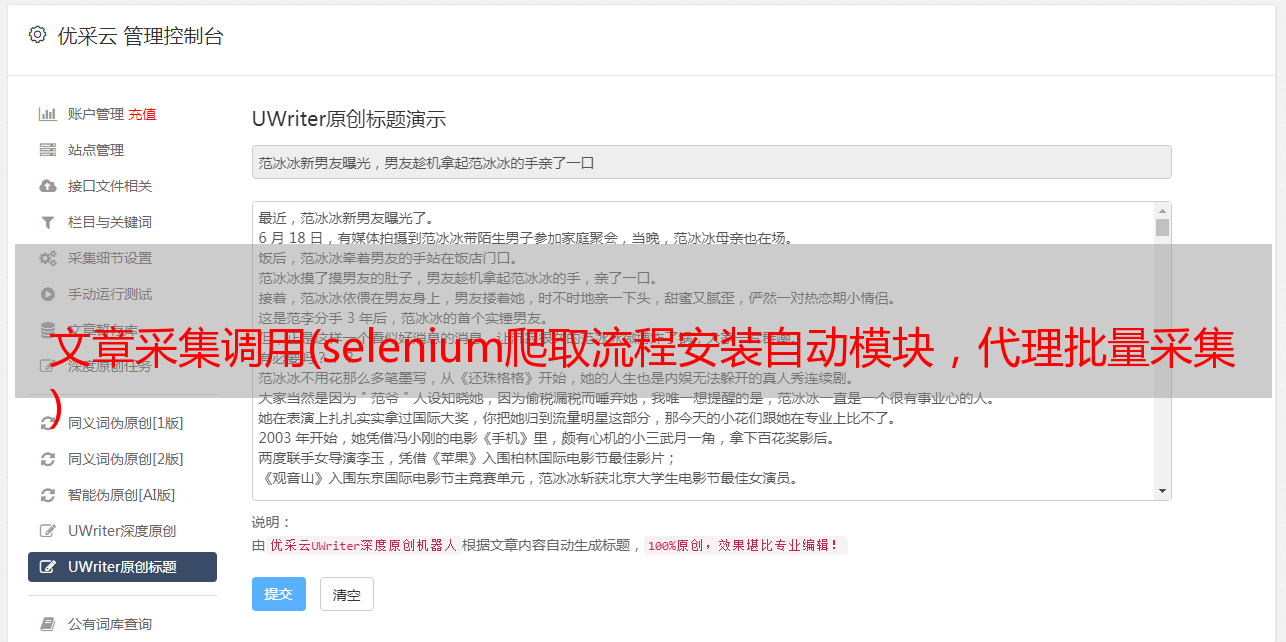
AnyProxy 代理批量采集
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。
2、微信个人账号:采集的内容,不仅需要微信客户端,采集还需要微信个人账号。
3、本地代理服务器系统:将公众号历史消息页面中的文章列表通过Anyproxy代理服务器发送到自己的服务器。
4、文章列表分析存储系统,分析文章列表并构建采集队列,实现批量采集内容。
Fiddler 设置代理并抓包
通过捕获和分析多个账户,可以确定:
_biz:这个14位的字符串是每个公众号的“id”,可以从搜狗的微信平台获取。
uin:与访客相关,微信ID
key:与访问的公众号相关
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
潜在问题:
如果只是想爬文章内容,貌似没有访问频率限制,但是如果想爬读点赞数,一定频率后返回值会变空。
付费平台
例如,如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
3 项目步骤
3.1基本原则
目标爬取微信平台网站收录大部分优质微信公众号文章,会定期更新。经过测试,发现对爬虫更加友好。
1、网站页面排版和排版规则,不同公众号以链接中的账号区分
公众号采集下的2、文章也有定时翻页:id号每翻一页+12
所以过程思路是
获取预查询微信公众号ID(不是直接显示的名字,而是信息名片中的ID号,一般由数字和字母组成)
请求一个html页面判断公众号是否被更改收录
如果没有收录,页面显示结果为:404 页面不存在,可以直接用正则表达式匹配提示信息
正则匹配查找目标公众号的最大页数收录文章
解析请求的页面,提取 文章 链接和标题文本
保存信息提取结果
调用pdfkit和wkhtmltopdf转换网页
3.2环境
win10(64位)
蜘蛛(蟒蛇3.6)
安装转换工具包 wkhtmltopdf
要求
pdf工具包
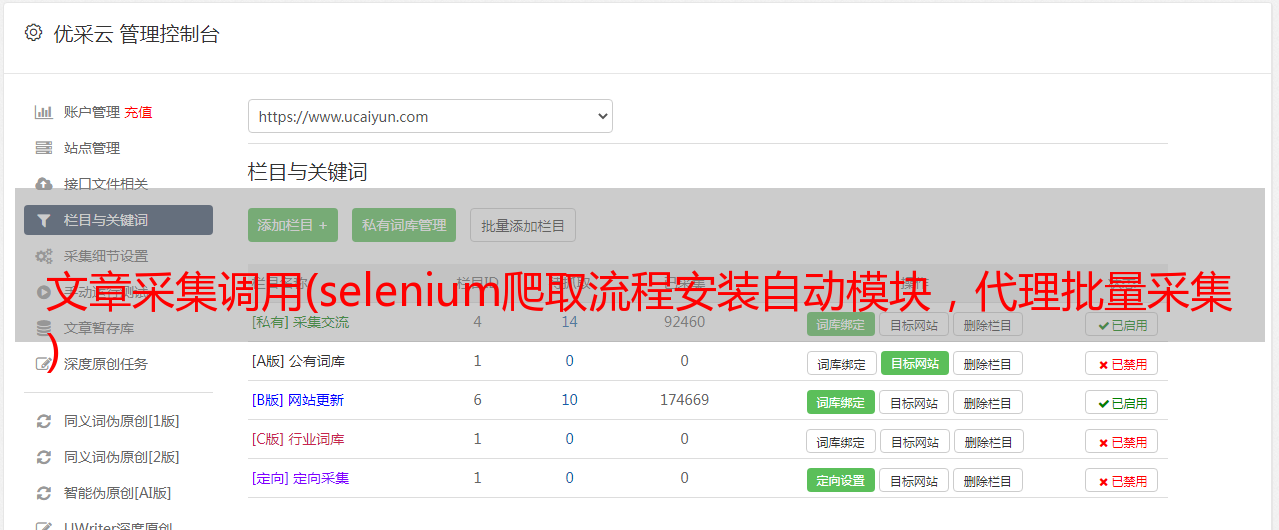
3.3 公众号信息检索
通过向目标url发起requset请求,获取页面的html信息,然后调用正则方法匹配两条信息
1、公众号是否存在
2、如果存在,最大文章收录页数是多少
当公众号存在时,直接调用request解析目标请求链接。
注意目标爬虫网站必须添加headers,否则会直接拒绝访问
3.4 正则解析、提取链接和文章标题
以下代码用于从 html 文本中解析链接和标题文本信息
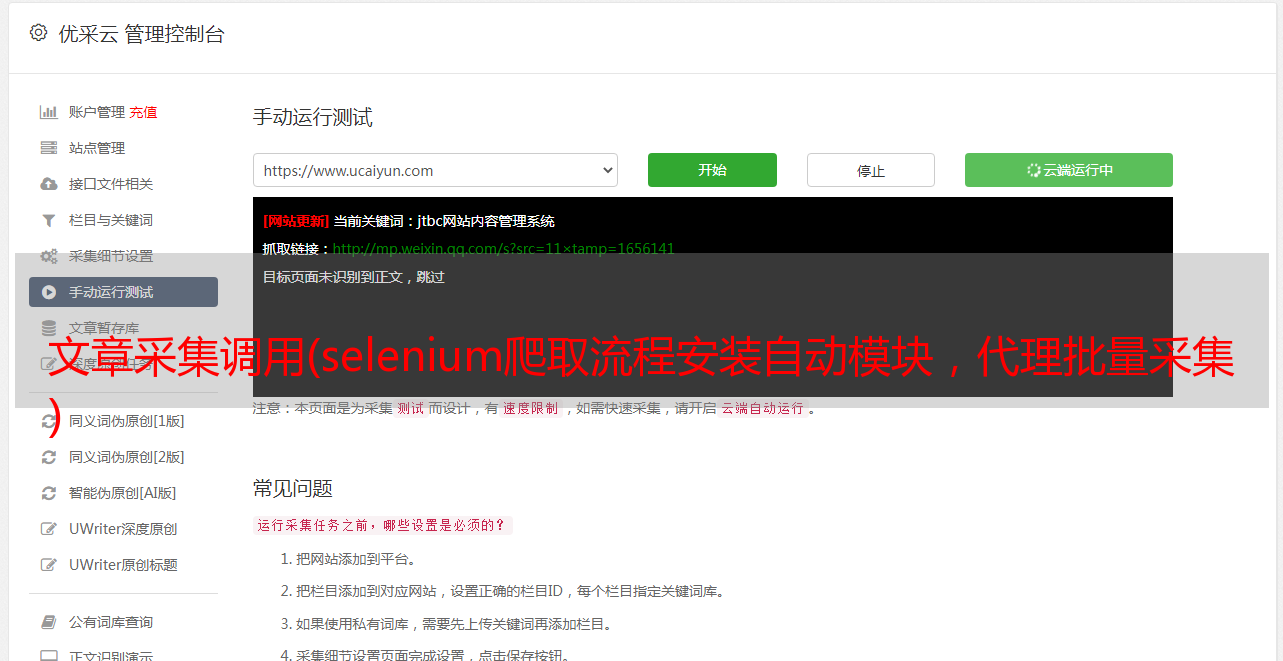
3.5 自动跳转页面
下面的代码通过循环递增赋值来改变url中的页码参数
3.6去除标题中的非法字符
因为windows下的file命令,有些字符不能使用,所以需要使用正则剔除
itle = re.sub('[/:*?"|]', '', info.loc[indexs]['title'])
3.7将html转换为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“link”、“title”、“date”
然后调用pdfkit函数转换生成的PDF文件
3.7将html转换为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“link”、“title”、“date”
然后调用pdfkit函数转换生成的PDF文件
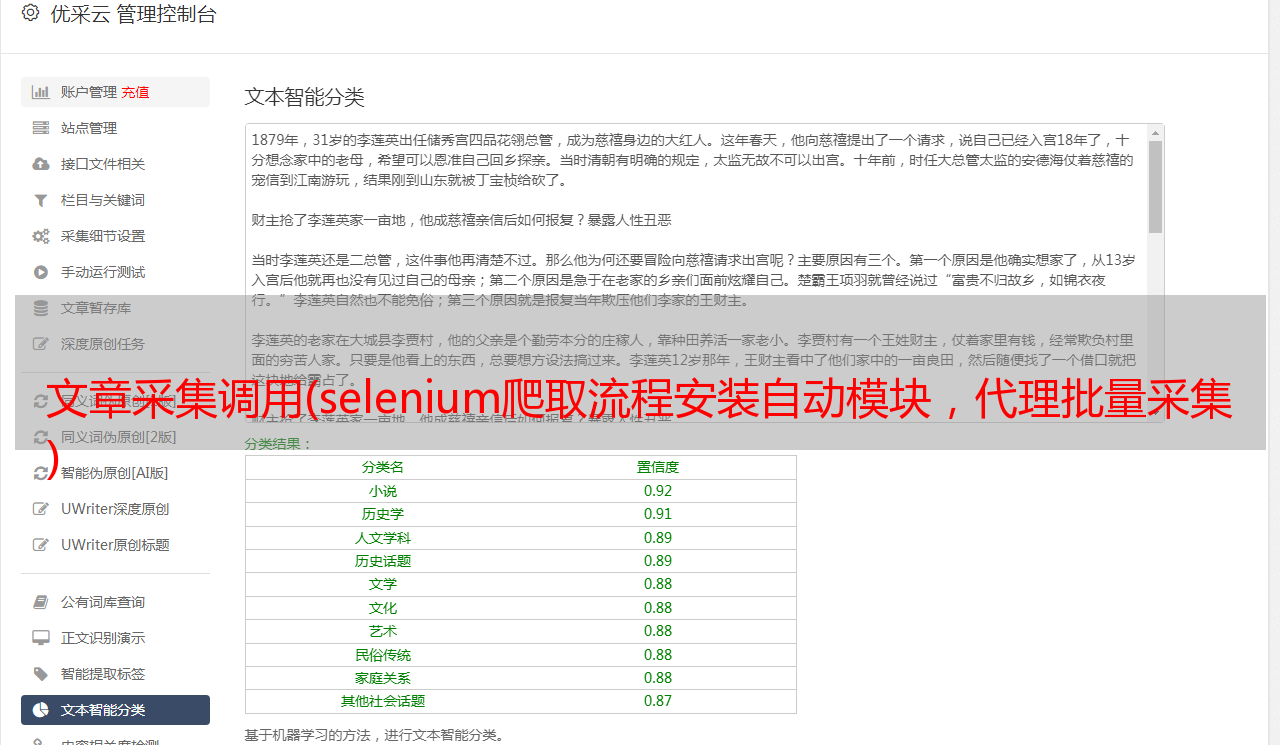
3.8 生成的 PDF 结果
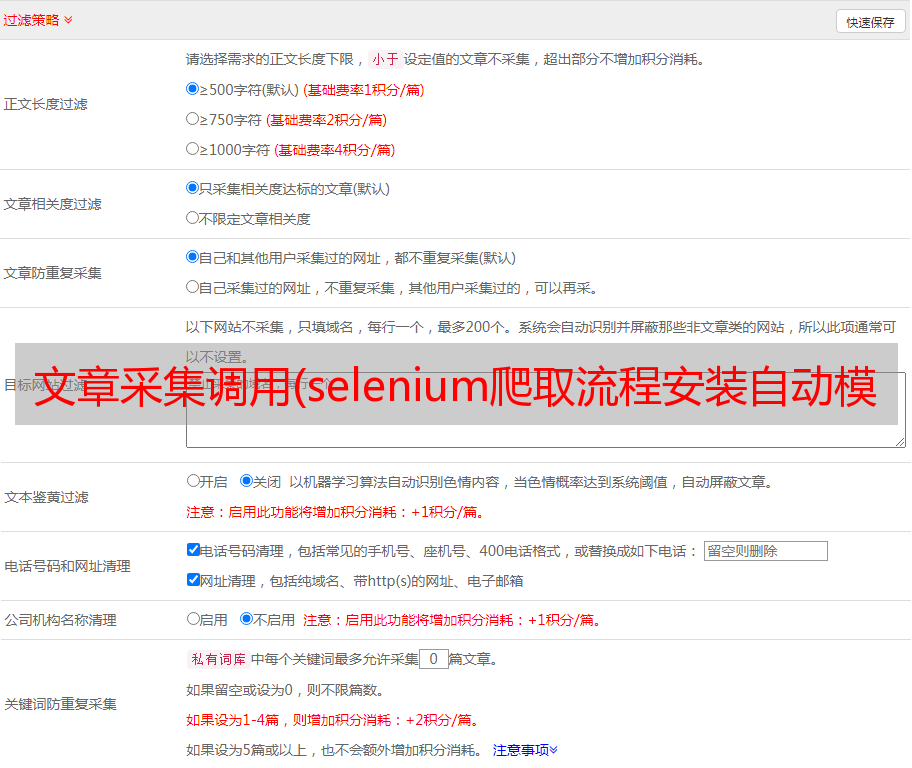
4 结果显示