动态网页抓取( 私信小编007或者01即可获取数十套PDF或者零基础入门资料一套)
优采云 发布时间: 2022-01-30 03:16动态网页抓取(
私信小编007或者01即可获取数十套PDF或者零基础入门资料一套)
写在前面的话
夜凉如水,夜空下,秋叶翩翩起舞。
天桥下,五彩缤纷的灯火一望无际,人来人往的十字路口,繁华热闹的城市。
我需要看看这位年轻女士的照片,感受这个世界的温柔。
私信编辑007或01获取几十套PDF或一套零基础的入门资料!
一.思路分析
根据爬行动物的基本规则:
1.寻找目标
2.获取目标
3.处理目标内容以获取有用信息
行动
1.我们的目标是:
这个网站是论坛式的网站,分为几类。无论如何,尝试各种*敏*感*词*。
我们的目标是找到这些(采集的)(隐藏的)移动(行进的)图片(self)的(self)、地面(electrical)地址(brain)。
2.看看各个模块的url,有什么规则?
是的,没错,如果您以访问者的身份访问,每个模块的 URL 将如下所示:
开始使用
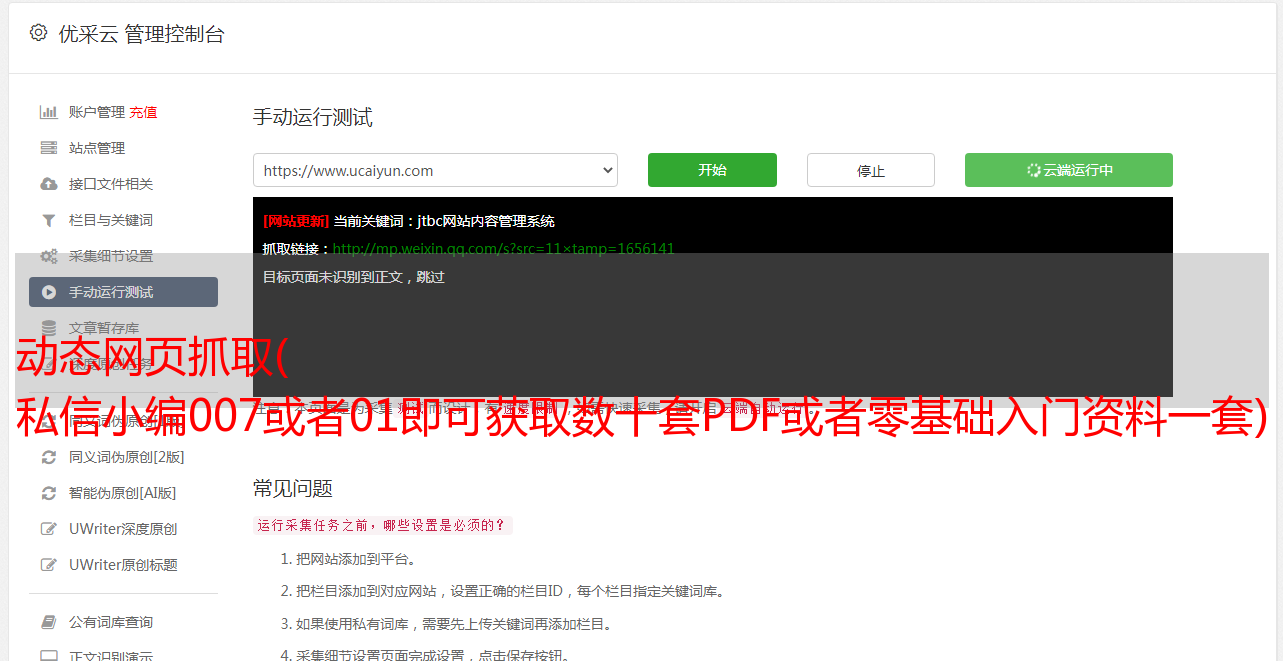
1.获取入口页面内容
即根据传入的URL,获取整个页面的源码
这里我们使用 webdriver 和 PhantomJS 之类的模块,为什么?因为网页是动态加载的,所以可以爬取的数据是满的。
2.获取页码
这里的页码处理使用了一个模板pq,它使用PyQuery来查找我们需要的元素。处理起来感觉更好,非常方便。
同时,这里的处理有点意思。如果你观察这个页面,你会发现每个模板的页码上下都有一个,然后
我这里截图了,因为我们只需要页码
3-6 一起说一下步骤3到6
其实就是根据页数进行遍历,得到每一页的内容
然后获取每一页的所有图片地址
在获取每个页面的内容时,需要重新组装页面地址。
有了新地址就可以得到当前页面的内容,进行数据处理得到每张图片的地址列表
得到图片列表后,再次解析得到每张图片的URL
将图像保存在本地,并将数据写入数据库
其实大致的内容到这里就讲完了。我们可以将本论坛各个模块的*敏*感*词*保存在本地,同时将数据存入数据库。
数据库过滤
把数据放入数据库后,想到直接调用数据库就可以保存图片了
(为什么会有这个想法,因为我发现如果直接在主程序中存储图片,运行太慢,不如把所有数据都放到数据库中,然后专门调用数据库存储图片)
但是这里有个问题,数据里面有很多内容,然后我们发现很多内容都是重复的,所以我们需要对数据库进行去重
关于去重的内容,其实我之前已经写过文章(我写那个文章的时候,这个爬虫已经完成了~)
主要思想是对某个元素的数量进行操作。pymongo中有一个方法可以统计指定元素的个数。如果只有一个当前元素,那没关系。如果它不是元素,则将其删除。
核心代码如下:
读取数据库中的内容并存储图片
数据去重后,再次存储图片就方便多了。
图片删除后,无需再次运行。核心代码如下:
完整代码
01_get_gif_url.py
02_delete_repeat_url_in_mongodb.py
谢谢阅读!!!

