伪原创网站源码(算法研究中的四大挑战和六个解决思路(一))
优采云 发布时间: 2022-01-29 18:16伪原创网站源码(算法研究中的四大挑战和六个解决思路(一))
如今,算法非常重要。算法是现代数据采集、分析和挖掘网络的支柱,是人工智能和机器人技术发展的驱动力。从概念层面来说,所谓算法可以简单理解为逐步输入任务并输出结果的过程,但从实际操作来看,这个过程其实是非常复杂的。原因在于该算法在执行过程中有两个步骤,一个是将任务转换为一系列逻辑步骤,另一个是将逻辑步骤转换为计算机代码。
鉴于算法的重要性,社会学家也应该关注算法对社会发展的影响。那么我们应该如何正确理解算法呢?Rob Kitchin 的论文批判性地思考和研究算法提供了一个好主意。他提到了算法研究中的四大挑战和六个解决方案。本文将尝试从论文中得出一些结论。
1、算法研究的四大挑战
首先,让我们来看看挑战。如上所述,算法在概念上是线性的,可以理解为以逻辑有序的方式完成输入和输出。这样的说法,普通人是完全可以理解的。但在实际应用中并非如此。这有很多原因,包括法律/文化和技术。研究人员必须避免所有可能的原因或注意这些潜在的障碍。
基钦提出四点:
首先,算法不能将具体内容暴露给外界。算法通常是私有的。公司或政府创建并拥有它,具体机制不对外披露。因此,我们说它在“黑匣子”中。我们可以看到它们在现实中产生的效果(它们的输出),但看不到它们内部运作的机制(盒子里的东西)。这种“黑匣子”现象有其原因,有时只是为了保护创作者的知识产权,有时是为了让算法继续产生其效用。例如,谷歌一直担心,如果它公布了 Pagerank 算法的工作原理,人们会开始使用这些规则来欺骗并削弱算法的有效性。如果您想了解更多关于“黑匣子”的信息
其次,算法差异很大,并且与上下文密切相关。一个人可以从头开始编写一个简单的算法来完成一项任务。在这种情况下,编写的算法通常很容易分解和理解。实际上,最有趣且具有社会影响力的算法不是由一个人编写或从头开始编写的,而是由大型团队将现有解决方案和混乱的代码片段组合成一个完整的算法网络。结果是一个更难分解和理解的算法系统。
第三,算法是个体发生的和执行的。现代算法不仅与上下文相关,而且通常是自我进化的。这是一个有点行话的说法,源于生物学。在这里,它只是意味着没有一个算法是静态和不可变的。一旦它们被发布,人们经常修改它们以适应他们的需要。程序员在研究用户交互后相应地修改代码。他们经常尝试不同版本的算法来确定哪个是最好的。此外,一些算法具有自我学习和适应的能力。这种动态和发展的性质意味着它们很难学习和研究。在稍后的某个时间点,这个算法系统可能与您之前研究它时的不同。
第四,算法不受约束。一旦人们开始使用这些算法,它们通常会以不受控制的方式发展和变化。这种情况最明显的例子是当算法产生意想不到的结果或以意想不到的方式使用时。如果我们不能根据算法的过去使用和性能做出有效的猜测,我们将很难将其推广到未来的使用中。从这个角度来看,算法的这一特性成为研究它的一个挑战。
这四个问题也经常混杂在一起,给研究人员带来了额外的挑战。
2、算法研究的六种方法
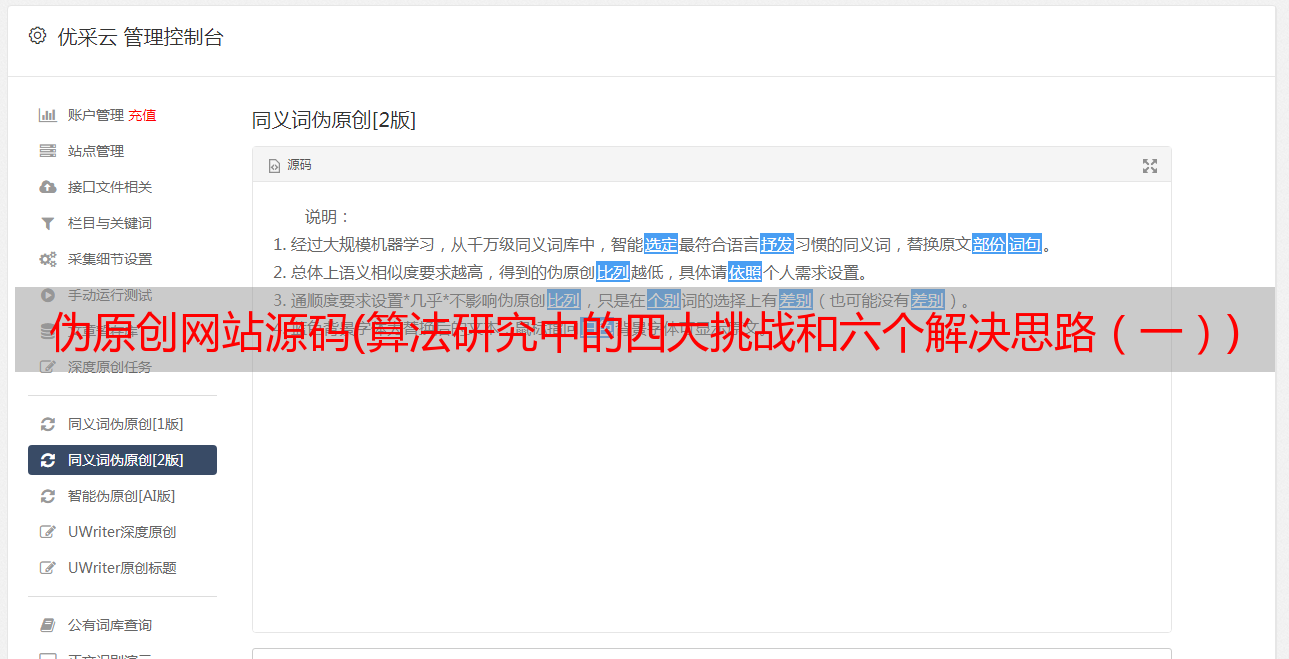
挑战存在,但是算法的社会和技术重要性使得研究它们成为必要。研究人员如何理解算法结构的复杂性和上下文性质以及用法?单一的研究方法永远无法解决,我们可能需要使用多种方法的组合。
Kitchin 的论文确定了六种可能的方法,每种方法都有优点和缺点。我将在下面简要描述它:
1. 研究伪代码和源代码:第一种方法最明显,它研究构建算法的代码。正如我在之前的文章中所讨论的,这包括两点:首先,“伪代码”,它是一组形式化的人类语言规则,用于翻译任务(伪代码遵循一些编程语言约定,但目标是供人类阅读)。第二,“源代码”,即翻译人类语言规则集的计算机语言。同时研究两者有助于研究人员了解算法的工作原理。对于这种方法,Kitchin 提出了三个更明确的变体:
这些方法的问题:代码经常分散,需要大量的翻译工作;研究人员需要一些技术专长;只关注代码意味着丢失了有关算法结构和用法的上下文信息。
2. 反身代码生成:第二种方法涉及坐下来,勾画出如何自己将任务转化为代码。Kitchin 将其称为“自动民族志”,这听起来很贴切。这种自动民族志或多或少有用。理想情况下,研究人员应密切反映将任务翻译成规则集计算机语言的过程,并在考虑各种社会、法律和技术框架的情况下规划如何进行。这些都有明显的局限性,因为这个过程是主观的,容易出现个人偏见和缺点。但它可以很好地补充其他研究方法。
3.逆向工程:这第三种方法需要一些解释。如上所述,研究人员面临的障碍之一是许多算法都是“黑匣子”。这意味着为了找出算法是如何工作的,你必须逆向在黑匣子中完成的工程。您需要研究算法的输入和输出,并可能添加不同输入的实验。人们经常在谷歌的页面排名上这样做,经常使他们自己的页面在搜索结果中更高。这种方法也有明显的局限性,即对算法运算的理解不完整、不完善。
4. 采访编程团队并了解人类构造:第四种方法在纠正以前方法中缺乏上下文方面大有帮助。这种方法遵循编程团队构建算法来采访他们,或者仔细观察他们(使用文化人类学)。这种方法有助于研究人员确定算法构建背后的原因,以及影响工程决策的社会文化原因。访问这样一个编程小组可能很困难,但 Kitchin 指出,一位名叫 Takhteyev 的研究人员曾在他自己的一个开源小组中工作。
5.解开完整的社会技术组合:用有些晦涩的术语描述第五种方法。所谓的“社会技术组合”汇集了塑造算法构建的所有法律、经济、制度、技术、政府、政治和其他因素。采访编程团队并对他们进行人种学研究可以帮助理解其中一些因素,但如果我们想完全解开它们(当然,我们无法完全理解一种现象),还需要了解更多。Kitchin 认为,对协作报告、法律框架、政府政策文件、财务、关键权力人物传记和其他类似材料的研究有助于促进此类研究。
6.研究算法在现实世界中的工作方式:这是另一种显而易见的方法。与其关注算法是如何产生的,哪些因素影响算法的产生,不如研究算法在现实世界中的效果。例如,它如何影响用户?会有什么意想不到的后果?有多种研究方法可以促进这种研究。用户体验、用户访谈和用户的人体结构都是可能的方法。好的研究着眼于算法如何改变用户行为以及用户可能会抵制或破坏算法预期功能的方式(例如,用户试图“玩”谷歌的 Pagerank)。
当然,没有一种方法足以解决问题,它们需要结合使用。然而,这些情况总是让人想起盲人摸象的古老故事。当每个人都在触摸大象的不同部位时,他们都在研究同一个潜在的物体。

