网页内容抓取工具(Python开发的一个快速、高层次的屏幕和web抓取框架, )
优采云 发布时间: 2022-01-29 15:05网页内容抓取工具(Python开发的一个快速、高层次的屏幕和web抓取框架,
)
文章目录 Scrapy 架构流程
• Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。
• Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
• Scrap,意思是片段,这个Python爬虫框架叫做Scrapy。
优势
– 用户只需要自定义开发几个模块,就可以轻松实现爬虫,爬取网页内容和图片非常方便;
– Scrapy使用Twisted异步网络框架处理网络通信,加快网页下载速度,不需要实现异步框架和多线程等,并收录各种中间件接口,灵活满足各种需求
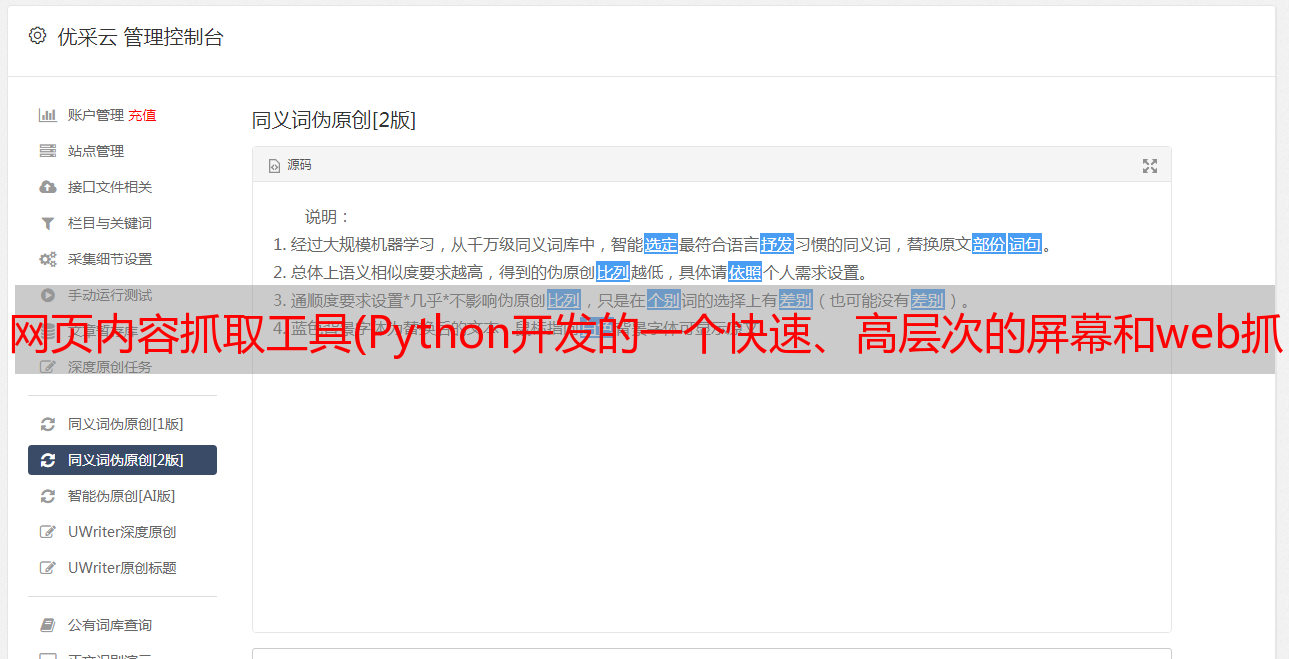
Scrapy主要包括以下组件:
• 引擎(Scrapy):
用于处理整个系统的数据流,触发事务(框架核心)
• 调度程序:
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被抓取的网站 URL 或链接)的优先级队列,它决定了下一个请求。爬行的
什么是网址,同时删除重复的网址
• 下载器:
用于下载网页内容并将网页内容返回给spider(Scrapy下载器建立在twisted的高效异步模型之上)
• 蜘蛛:
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
• 项目管道:
它负责处理爬虫从网页中提取的实体。主要功能是持久化实体,验证实体的有效性,去除不必要的信息。当页面被爬虫解析后,会被发送到项目流水线,数据会按照几个特定的顺序进行处理。
• 下载器中间件:
Scrapy 引擎和下载器之间的框架主要处理 Scrapy 引擎和下载器之间的请求和响应。
• 蜘蛛中间件:
Scrapy引擎和爬虫之间的一个框架,主要工作是处理蜘蛛的响应输入和请求输出
• 调度程序中间件:
Scrapy 引擎和调度器之间的中间件,从 Scrapy 引擎发送到调度器的请求和响应。
只有当调度器中没有请求时,整个程序才会停止。(注:对于下载失败的URL,Scrapy也会重新下载。)
Scrapy爬虫步骤
• 新项目(scrapy startproject xxx):
– 创建一个新的爬虫项目;
• 明确目标(写 item.py)
- 明确你想抢的东西;
• 制作蜘蛛 (spiders/xxspider.py)
– 创建爬虫并开始爬取网页;
• 存储爬虫 (pipelines.py)
– 设置管道来存储爬取的内容;
官方文档
用scrapy改写四大名作的爬取
1、从命令行创建一个scrapy项目
scrapy 启动项目 scrapyproject
scrapy.cfg 项目配置文件
setting.py 爬虫的设置文件
spiders目录用于编写爬虫解析的一些代码
items.py 存储数据格式信息
pipelines.py 定义了项目的存储方式
项目创建后,会有提示:
您可以使用以下方法启动您的第一个蜘蛛:
cd scrapyproject
scrapy genspider example # 创建爬虫
在 spiders 目录中会出现一个爬虫示例,
2、编写蜘蛛解析数据
scrapy shell + url #进入交互界面
它将显示一些可以使用的命令
view(response) # 在浏览器中查看响应是否是我们需要的
通过xpath语法找到响应中需要的内容,验证是否正确,然后写入爬虫文件
您可以将要使用的信息封装在元信息元中并直接使用。
蜘蛛/book.py
1import scrapy
2from scrapy import Request
3"""
4Scrapy爬虫流程:
5 1. 确定start_urls起始URL
6 2. 引擎将起始的URL交给调度器(存储到队列, 去重)
7 3. 调度器将URL发送给Downloader,Downloader发起Request从互联网上下载网页信息(Response)
8 4. 将下载的页面内容交给Spider, 进行解析(parse函数), yield 数据
9 5. 将处理好的数据(items)交给pipeline进行存储
10
11下载图书到本地修改的内容:
12 1). 请求图书详情页parse(self, response)函数的修改-ScrapyProject/ScrapyProject/spiders/book.py
13 2). 对章节详情页进行解析parse_chapter_detail函数的修改-ScrapyProject/ScrapyProject/spiders/book.py
14 3). 将采集的数据存储到文件中, pipeeline组件-ScrapyProject/ScrapyProject/pipelines.py
15 4). 设置文件中启动pipeline组件-ScrapyProject/ScrapyProject/settings.py
16"""
17class BookSpider(scrapy.Spider):
18 # 爬虫的名称必须是唯一的
19 name = 'book'
20 base_url = 'http://www.shicimingju.com'
21 # 只能爬取的域名,可以注释起来
22 # allowed_domains = ['shicimingju.com']
23 # 起始的url地址, 可以指定多个, 有两种方式指定:
24 # 1). start_urls属性设置=[]
25 # 2). 通过start_requests生成起始url地址
26 start_urls = [
27 'http://www.shicimingju.com/book/sanguoyanyi.html',
28 'http://www.shicimingju.com/book/xiyouji.html',
29 'http://www.shicimingju.com/book/hongloumeng.html',
30]
31
32 def parse(self, response):
33 """
34 1). 如何编写好的解析代码呢? 使用Scrapy的交互式工具scrapy shell url
35 2). 如何处理解析后的数据? 通过yield返回解析数据的字典格式
36 3). 如何获取/下载小说章节详情页的链接并下载到本地?
37
38 """
39 # name = response.url.split('/')[-1]
40 # self.log('save file %s' % name)
41 # 获取所有章节的li标签
42 chapters = response.xpath('//div[@class="book-mulu"]/ul/li')
43 # 2). 遍历每一个li标签, 提取章节的详细网址和章节名称
44 for chapter in chapters:
45 detail_url = chapter.xpath('./a/@href').extract_first()
46 name = chapter.xpath('./a/text()').extract_first()
47 bookname = response.url.split('/')[-1].rstrip('.html')
48 # 将章节详情页的url提交到调度器队列, 通过Downloader下载器下载并交给
49 # self.parse_chapter_detail解析器进行解析处理数据。
50 yield Request(url=self.base_url + detail_url,
51 callback=self.parse_chapter_detail,
52 meta={
53 'name':name,
54 'bookname':bookname
55 })
56 # yield {
57 # 'detail_url': detail_url,
58 # 'name': name
59 # }
60
61 def parse_chapter_detail(self,response):
62 # 1). .xpath('string(.)')获取该标签及子孙标签所有的文本信息;
63 # 2). 如何将对象转成字符串?
64 # - extract_first()/get()-转换一个对象为字符串
65 # - extract()/get_all()-转换列表中的每一个对象为字符串
66 content = response.xpath('//div[@class="chapter_content"]').xpath('string(.)').extract_first()
67 yield {
68 'name': response.meta['name'], # 请求页面时会自动传递过来
69 'content': content,
70 'bookname': response.meta['bookname']
71 }
72
73
3、编写管道存储爬取的数据
在数据部分解析yield返回的数据,以item的形式传入管道,实现信息的持久化存储。
管道线.py
1import os
2class ScrapyprojectPipeline(object):
3 def process_item(self, item, spider):
4 """将章节内容写入对应的章节文件"""
5 dirname = os.path.join('books', item['bookname'])
6 if not os.path.exists(dirname):
7 os.makedirs(dirname)
8 filename = os.path.join(dirname,item['name'])
9
10 with open(filename, mode='w', encoding='utf-8') as f:
11 f.write(item['content'])
12 print('写入文件%s成功' % item['name'])
13 return item
14
15

