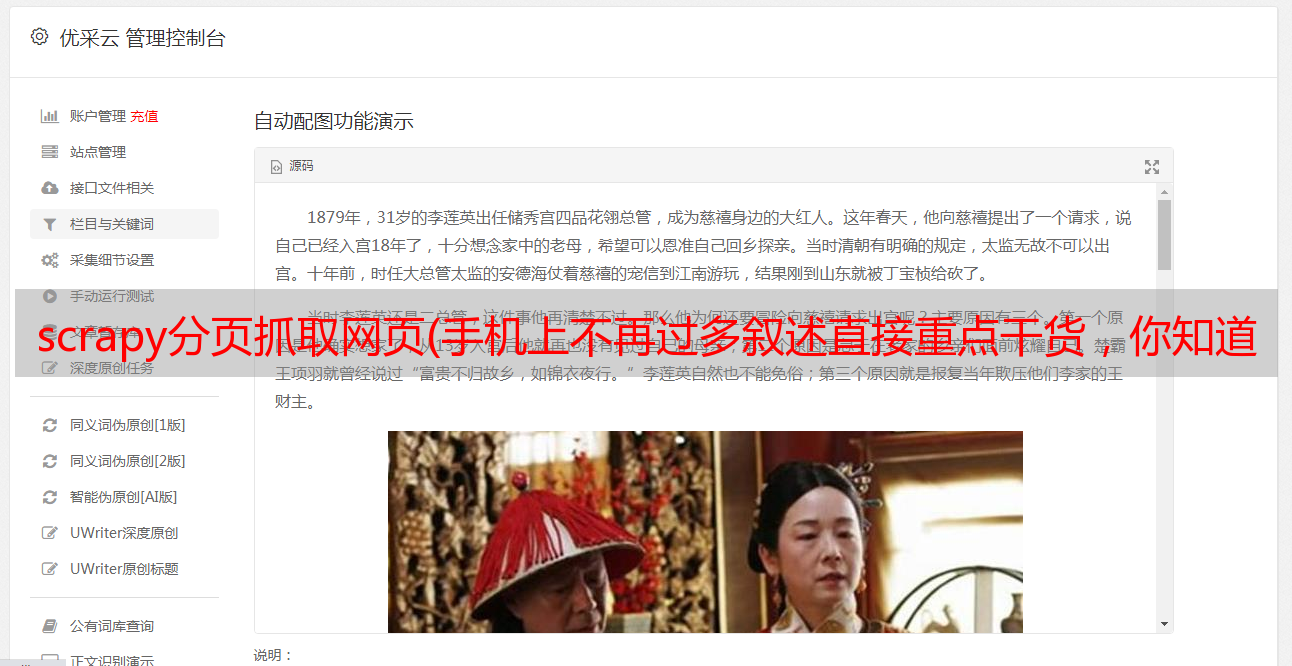
scrapy分页抓取网页(手机上不再过多叙述直接重点干货,你知道吗?)
优采云 发布时间: 2022-01-21 13:21scrapy分页抓取网页(手机上不再过多叙述直接重点干货,你知道吗?)
如果手机显示的验证码有误,请分享到QQ或其他地方,在电脑上查看!!!
python可以做的事情有很多,这里就不过多描述了,重点说干货。
在开始使用爬行动物之后,我们有两条路可以走。
一是继续深入学习,以及一些设计模式的知识,加强Python相关知识,自己造轮子,继续给自己的爬虫添加分布式、多线程等功能扩展。另一种方法是学习一些优秀的框架。先熟悉这些框架,保证自己能应付一些基本的爬虫任务,也就是所谓的温饱问题解决,然后再深入学习其源码等知识进一步加强。
就个人而言,前一种方法实际上是自己造轮子。前人其实已经有了一些比较好的框架,可以直接使用,但是为了能够更深入的学习,对爬虫有更全面的了解,还是自己动手吧。后一种方法是直接使用前人写过的比较优秀的框架,好好利用。首先,确保你能完成你想要完成的任务,然后深入研究它们。对于第一个,你越是探索自己,你对爬行动物的了解就会越透彻。二是用别人的,方便你,但你可能没有心情去深入研究框架,你的思维可能会受到束缚。
. . .
接触过几个爬虫框架,其中Scrapy和PySpider比较好用。个人觉得pyspider更容易上手,更容易操作,因为它增加了WEB界面,写爬虫快,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy 定制化程度高,比 PySpider 低。它适合学习和研究。有很多相关的知识要学,但是非常适合自学分布式和多线程。
从爬虫的基本需求来看:
1.抢
py 的 urllib 不一定是要使用的,而是要学习的,如果你还没用过的话。
更好的替代方案是第三方、更用户友好和成熟的库,例如 requests。如果pyer不理解各种库,学习是没用的。
抓取基本上是拉回网页。
再深入一点,你会发现你要面对不同的网页需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookie跟随问题、多线程和多进程爬取、多节点爬取、爬取调度、资源压缩等一系列问题。
所以第一步就是把网页拉回来,慢慢的你会发现各种问题需要优化。
2.存储
捕获的数据一般会用一定的策略保存,而不是直接分析。个人认为更好的架构应该是分析和捕获分离,更加松散。如果每个环节都有问题,它可以隔离另一个环节可能出现的问题。检查或更新和发布。
那么,如何保存文件系统、SQLorNOSQL数据库、内存数据库是本环节的重点。
你可以选择保存文件系统启动,然后用一定的规则命名。
3.分析
对网页进行文本分析,是提取链接还是提取文本,总之看需求,但必须要做的是分析链接。
您可以使用最快和最优化的方法,例如正则表达式。
然后将分析结果应用到其他链接:)
4.显示
如果一堆事情都做完了,根本没有输出,怎么体现价值。
所以找到好的展示元件,展示肌肉也是关键。
如果你想写爬虫是为了做一个站,或者是分析某个东西的数据,别忘了这个链接,这样可以更好的把结果展示给别人。
前言
其实写这篇MongoDB体验的初衷和我当年整理的js脑图比较一致,而且确实,就我个人而言,还是希望在每个时间段输出一些整理好的东西,分享给有需要的人他们。
这一系列的题目和我现在写的yc(一个花哨的节点开发平台)是一样的。架子很大,但我会继续写。希望有兴趣的同学多多关注。
介绍
本文介绍了一些涉及文档、集合和数据库的基本概念,以及一些基本操作。
那么MongoDB有什么用呢?事实上,关键词 仍然是 NoSQL
安装
本文只介绍mac上的安装,可戳:官方文档,本文不做过多描述,只是提醒需要手动创建数据目录,其功能后面会介绍。
基本概念
文档
我们先来看一个我们熟悉的js中的对象:
shell
{"name" : "yaochun" , "company" : "wandoujia" , "group" : "w3cplus" , "job" : "fe"}
其实这也是MongoDB中的核心概念:document
它是一个键值对,但有一些独特的特点:
一、这个键值对是有序的:
shell
{ "name" : "yaochun" , "company" : "wandoujia" }
{ "company" : "wandoujia" , "name" : "yaochun" }
所以上面两个文件是不一样的。
二、key是字符串,不能有\0, . 和 $ 有特殊含义,_ 的开头是保留的
三、该值可以是双引号字符串或其他几种数据类型。
四、类型和大小写敏感:
shell
{ "name" : "yaochun" , "company" : "wandoujia" , "age" : 50 }
{ "company" : "wandoujia" , "name" : "yaochun" , "age" : "50" }
所以上面两个文件也不同。
五、文档中的key不能重复,否则视为非法。
集合实际上是一组文档。
命名集合也有规则:
不能为空字符串
也不能有 \0 字符
不能以某些系统集合的保留前缀开头,例如 system.
也不能收录 $
该集合中是否有任何数学子集?您可以使用 。来划分子集。
数据库
数据库实际上是由多个集合组成的。数据库相对独立,存储在不同的文件中。
命名数据库也有规则:
不能为空字符串
也不能有\0、$类似这些字符
小写
最多 64 个字节
因为数据库名最终会变成文件系统文件,所以命名有一定的限制。
保留数据库名词:
行政
当地的
配置
数据类型简介
其实你发现没有,文档的结构和我们常用的 JSON 差不多。MongoDB中有哪些数据类型?
空值
shell
{ "freetime" : null }
日期
shell
{ "date" : new Date() }
大批
例子:
shell
{ "keywords" : [ "yaochun" , "wandoujia" , "w3cplus" ] }
嵌入文档
例子:
shell
{ "info" : {"yaochun" , "company" : "wandoujia" , "group" : "w3cplus" } }
实际上,该文档收录一个文档
常规的
例子:
shell
{ "name" : /yaochun/i }
代码
例子:
shell
{ "code" : function() {/*..*/} }
其他基本比较如:布尔、字符串等这里不介绍。
基本操作
一般包括:插入、更新、删除和查询
插入
例子:
shell
//welcome to join us: http://www.wandoujia.com/joindb.wandoujia.fe.insert({ "name" : "yourname" })
其实从上面的例子中就可以很直观的看出插入:
也使用插入
insert方法中传入的其实是一个文档
没有主键吗?默认情况下,MongoDB 插入会在文档中添加一个 _id。
删除
示例 1:
shell
db.book.mongodb.remove()
这意味着我已经删除了图书集合的子集合mongodb中的所有文档,但是子集合mongodb本身还在,索引也会保留。
示例 2:
shell db.book.mongodb.remove({ "part" : "primary" })
在这里,将一个文档传递给删除操作以进行查询和过滤。只有符合条件的文件才会被删除。
这意味着我删除了书籍集合的 mongodb 子集合中的所有主要部分。
查询
在初级教程中,我们简单地看一下基本的查询方法,在中级教程中,我们将全面学习。
示例 1:
shell //欢迎加入我们:db.wandoujia.jobs.find()
示例 2:
shell //欢迎加入我们:db.wandoujia.jobs.find({ "category", "fe" , "level" : 2 })
从上面的例子可以看出,最基本的查询可以使用find找到
而find可以传递参数,比如一个或几个文档来指定查询条件。
多维查询
寻找
前面我们简单介绍了find的第一个参数,其实就是一个文档,作为过滤条件
示例 1:
shell
//welcome to join us: http://www.wandoujia.com/joindb.wandoujia.jobs.find()
示例 2:
shell
//welcome to join us: http://www.wandoujia.com/joindb.wandoujia.jobs.find({"category", "fe" , "level" : 2})
所以实际上在我们的日期查询中,对于返回的查询结果,有一些无用的键值是需要指定或者过滤掉的。如何处理?
示例 1:
shell
db.wandoujia.jobs.find({} , {"category" : 1, "base" : 1})
示例 2:
shell
db.wandoujia.jobs.find({} , {"level" : 0})
在上面的段落中,我们实际上看到:
find 可以指定第二个参数
只能返回第二个参数document中指定的字段,其中对应的值为1
消除查询结果中某个键的转换,并将对应的值设置为0。
这样做的好处是非常明显的:
减少数据的大小
保存传输的数据量
客户端还可以减少解码文档的时间和内存消耗
查询条件
其实为了达到精准定位,我们会指定一些查询条件,比如:
=
!=
那么MongoDB中使用的这些比较运算符是什么?
$lt
$lte
$gt
$gte
$ne
我们直接看一个例子:
shell
//比如我们找工作有的人只看2级到3级的
db.wandoujia.jobs.find({"level" , {"$gte" : 2, "$lte" : 3})
这里我们传递一个嵌入的文档来查找,内部文档的key是$gte和$lte
示例 2:
shell
//比如我们找工作有的人不看帝都的
db.wandoujia.jobs.find({"base" , {"$ne" : "beijing"})
这里,$ne 表示不等于
所以粗略的规则:
$lt、$lte、$gt、$gte 和 $ne 都以 $ 开头,这也验证了为什么我们在命名别人时不建议使用 $。
$lt、$lte、$gt、$gte、$ne 一般在内部文档中。
管理 MongoDB
其实读了很多之后,一定更愿意自己动手,实践这些操作。
启动
通常,它作为网络服务器运行,客户端可以连接到该服务器。
命令行
shell
./mongod
我这里没有指定任何参数,其实是从
shell
./mongod -h
控制台会打印一堆帮助命令,还有很多,这里只提几个:
可以指定数据目录。默认为 /data/db(在根目录下)。每个 mongod 实例都需要一个单独的数据目录。并且当mongod启动时,会在数据中创建一个mongod.lock文件,防止其他mongod进程使用这个数据目录。
有兴趣的可以自己打开对应的数据目录查看。
--logpath 和 --logappend

可以指定日志输出的路径,最好配合logappend。在大多数情况下,我们仍然希望保留原创日志并添加它而不是覆盖它。
-f可以指定某个配置文件来加载命令
编写配置文件有什么要求吗?
shell# config by yaochun 2013-08-07 pm 07:10logpath = mongodb.log
当然,还有很多其他有用的设置,比如:
等等,如果你需要的话,你可以直接进入 -h 中的说明。
MongoDB客户端
服务器启动后,我们需要一个客户端来操作,那么这个客户端是什么?
看图,我们在命令行输入如下命令:
shell
./mongo
是MongoDB的shell,也是js的shell,可以完成与MongoDB实例的交互
注:其实如果只是想体验一下js shell的改造,可以输入:
shell
./mongo --nodb
这样,它就不会连接到数据库。
默认会自动连接服务器的test数据库,并将这个数据库连接赋值给全局db变量
如图所示:
当然,如果你想要帮助文档来查看那里有哪些命令,你可以输入:
shell
help
如图所示:

常用:
show dbs
返回所有当前数据库名称
如图所示:

show collections
返回当前数据库中的所有集合(注意:它收录 system.* 本系统的集合)
use wandoujia
比如我现在默认在test数据库,现在想切换到wandoujia数据库
如图:db.fe
这样就可以访问上面输入的玩豆家数据库的fe集合了。
外壳执行插入
shell
use wandoujia
db.fe.insert({ "name" : "yourname" })
这样一来,玩豆家数据库的fe集合中就多了一份文档。
shell 执行查询
shell
db.fe.find()
将返回一个收录刚刚插入的文档的集合。
外壳执行更新
shell
db.fe.update( { "name" : "yourname" }, { "name" : "yourname", "recommender" : "yaochun" })
update至少接受两个参数,第一个是资格对应的文档,第二个是新文档。
经过测试,你会发现这个更新其实是第二个直接覆盖第一个的新文档。当然也可以先定义一个变量,这样更新的时候可以修改那个变量,然后传给update。你不需要这样写。
外壳执行删除
shell
db.fe.remove({ "recommender" : "yaochun" })
强大的聚合工具
其实简单来说就是:统计一些集合中的文档个数
数数
返回集合中的文档数
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count()
例如,我知道 fe-team 的人数如何?
shell//比如现在wandoujia一共的员工数目db.wandoujia.staff.count({ "category" : "fe" })
以上内容是我最近使用MongoDB的一些经验。如果有不准确的地方,希望大家多多指点。如果您有相关经验,请在下面的评论中与我们分享。
知乎爬取用户信息的思路
首先,我们应该找到一个帐户。这个账号的人数和关注人数都比较多。就是下图中金字塔顶端的那个人。被关注人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,爬取整个知乎的所有信息@> 以这种递归方式。帐户信息。整个过程用下面两张图表示:


爬虫分析流程
我们在这里寻找的账户地址是:
我们抓到的大V账号的主要信息是:

接下来,我们需要获取关注列表和该账号的关注列表

这里我们需要通过抓包分析来分析这些列表的信息和用户的个人信息

