通过关键词采集文章采集api(DogUI上的数据就是单薄了很多,你知道吗?)
优采云 发布时间: 2022-01-16 22:22通过关键词采集文章采集api(DogUI上的数据就是单薄了很多,你知道吗?)
MySQL:通过Mybatis*敏*感*词*;
Redis:通过javassist增强RedisTemplate的方式;
跨应用调用:通过代理feign客户端,dubbo、grpc等方法可能需要通过*敏*感*词*;
http调用:通过javassist给HttpClient和OkHttp添加*敏*感*词*;
日志管理:通过plugin方式上报日志中打印的错误。
管理的技术细节这里就不展开了,主要是使用各种框架提供的一些接口,以及使用javassist进行字节码增强。
这些打点数据就是我们需要做统计的,当然因为打点有限,我们的tracing功能比专业的Traces系统要薄很多。
介绍
下面是DOG的架构图。客户端将消息传递给 Kafka,狗服务器使用消息。Cassandra 和 ClickHouse 用于存储。具体要存储的数据后面会介绍。
1、还有不使用消息中间件的 APM 系统。例如,在 Cat 中,客户端通过 Netty 连接到服务器以发送消息。
2、服务端采用Lambda架构模式。Dog UI 上查询的数据是从每个 Dog-server 的内存数据和下游存储的数据中聚合而成的。
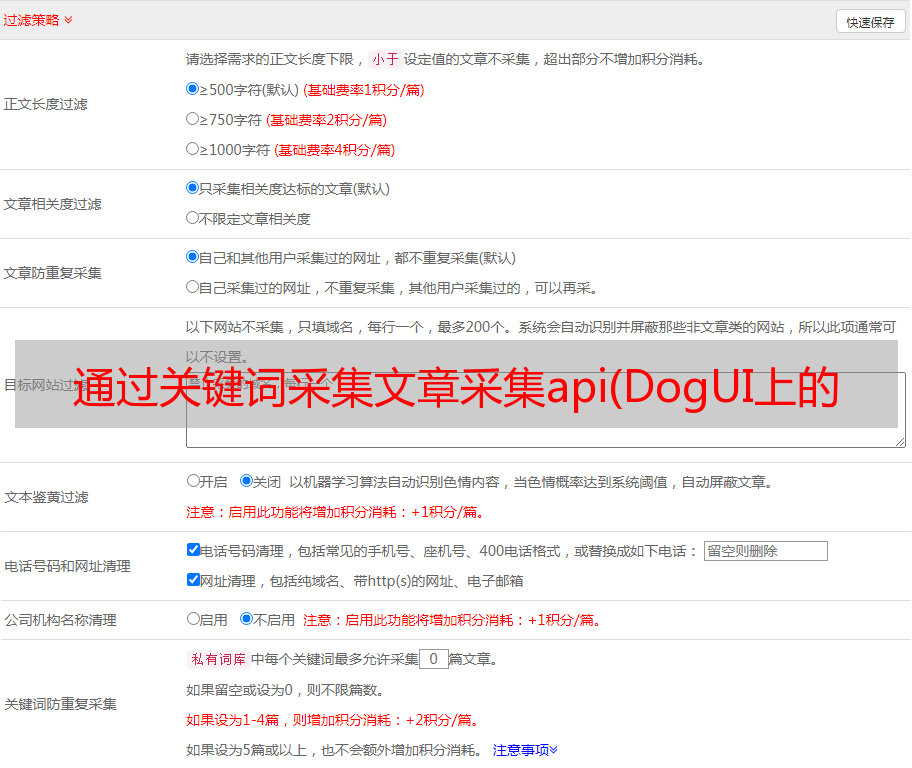
下面,我们简单介绍一下 Dog UI 上比较重要的一些功能,然后我们将分析如何实现相应的功能。
注:以下图片均为本人绘制,非实页截图,数值可能不准确
下图显示了一个示例交易报告:
当然,点击上图中的具体名称,以及下一级状态的统计数据,这里就不会有映射了。Dog一共设计了type、name、status三个属性。上两图中的最后一列是sample,它通向sample视图:
样本意味着抽样。当我们看到一个高故障率或者高P90的接口,你就知道有问题了,但是因为它只有统计数据,你不知道哪里出了问题。这时候,你需要一些样本数据。对于类型、名称和状态的不同组合,我们每分钟最多保存 5 个成功、5 个失败和 5 个处理缓慢的样本数据。
通过上面的trace视图,可以很快的知道是哪个环节出了问题。当然,我们之前也说过,我们的 Trace 依赖于我们埋点的丰富程度,但是 Dog 是一个基于 Metrics 的系统,所以它的 Traces 能力是不够的,但在大多数情况下,对于排查问题应该足够了。
对于应用程序开发人员,以下问题视图应该非常有用:
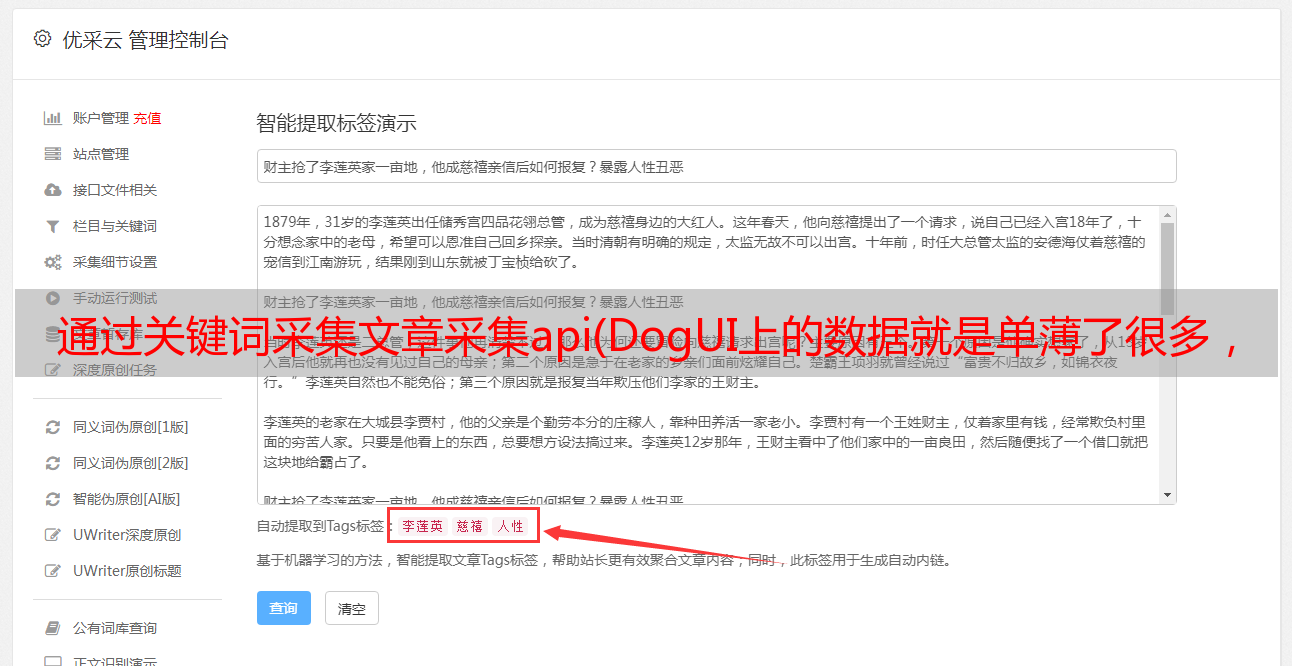
它显示了各种错误统计信息,并为开发人员提供了解决问题的示例。
最后简单介绍一下Heartbeat视图,它和前面的功能没有任何关系,而是大量的图表。我们有gc、heap、os、thread等各种数据,以便我们观察系统的健康状况。
本节主要介绍APM系统通常收录哪些功能。其实很简单,对吧?接下来,我们从开发者的角度来谈谈具体的实现细节。
*敏*感*词*模型
每个人都是开发者,所以我会更直接。下图描述了客户端的数据模型:
对于Message来说,用于统计的字段有type、name、status,所以我们可以根据type、type+name、type+name+status这三个维度进行统计。
Message中的其他字段:timestamp表示事件发生的时间;如果成功为假,该事件将被计入问题报告;数据不具有统计意义,仅对链路跟踪和故障排除有用;businessData 用于向业务系统上报业务数据,需要手动管理,然后用于业务数据分析。
Message 有两个子类 Event 和 Transaction。不同的是Transaction有一个duration属性,用来标识事务需要多长时间。可以用于max time、min time、avg time、p90、p95等,而event指的是发生了某事发生的时候,只能用来统计发生了多少次,没有概念的时间长度。
Transaction有一个属性children,可以嵌套Transaction或者Event,最后形成一个树形结构进行trace,后面会介绍。
下表显示了一个虚线数据的示例,更直观:
只是几件事:
类型为URL、SQL、Redis、FeignClient、HttpClient等数据,属于自动跟踪的范畴。通常,在APM系统上工作的时候,一定要完成一些自动埋点工作,这样应用开发者不用做任何埋点工作就可以看到很多有用的数据。Type=Order 像最后两行一样属于人工埋藏的数据。
打点需要特别注意类型、名称和状态的维度的“爆炸”。它们的组合太多会消耗大量资源,并且可能直接拖累我们的Dog系统。type的维度可能不会太多,但是我们可能需要注意开发者可能会滥用name和status,所以一定要进行normalize(比如url可能有动态参数,需要格式化)。
表中最后两项是开发者手动埋藏的数据,通常用于统计具体场景。比如我想知道某个方法是怎么调用的,调用次数,耗时,是否抛出异常,输入参数,返回值。等待。因为自动埋点是业务不想关闭的冷数据,开发者可能想埋一些自己想统计的数据。
当开发者手动埋点时,也可以上报更多业务相关的数据。请参阅表格的最后一列。这些数据可用于业务分析。比如我是一个支付系统,通常一个支付订单涉及到很多步骤(国外支付和你平时使用的微信和支付宝略有不同)。通过上报各个节点的数据,我终于可以在Dog上使用bizId串起整个链接,在排查问题时非常有用(我们做支付业务的时候,支付成功率并没有大家想象的那么高,而且节点很多可能有问题)。
客户设计
上一节介绍了单条消息的数据,本节介绍其他内容。
首先我们介绍一下客户端的API使用:
上面的代码说明了如何使用嵌套的事务和事件。当最外层的Transaction在finally代码块中调用finish()时,树的创建就完成了,消息就被传递了。
我们交付给 Kafka 的不是 Message 实例,因为一个请求会产生很多 Message 实例,但应该组织成一个 Tree 实例以便以后交付。下图描述了 Tree 的各种属性:
树的属性很好理解。它持有对根事务的引用,并用于遍历整个树。另外,需要携带机器信息messageEnv。
treeId应该有保证全局唯一性的算法,简单介绍Dog的实现:$-$-$-$。
下面简单介绍几个tree id相关的内容。假设一个请求从A->B->C->D经过4个应用,A是入口应用,那么会有:
1、总共有 4 个 Tree 对象实例将从 4 个应用程序交付给 Kafka。跨应用调用时,需要传递treeId、parentTreeId、rootTreeId三个参数;
2、一个应用的treeId是所有节点的rootTreeId;
3、B应用的parentTreeId就是A的treeId,同理C的parentTreeId就是B应用的treeId;
4、跨应用调用时,比如从A调用B时,为了知道A的下一个节点是什么,在A中提前为B生成treeId,B收到请求后,如果找到A 已经为它生成了一个treeId,直接使用那个treeId。
大家也应该很容易知道,通过这些tree id,我们要实现trace的功能。
介绍完树的内容后,我们来简单讨论一下应用集成解决方案。
集成无非是两种技术。一种是通过javaagent。在启动脚本中,添加相应的代理。这种方式的好处是开发者无意识,运维级别可以做到。当然,如果开发者想要手动做一些嵌入,可能需要给开发者提供一个简单的客户端jar包来桥接代理。
另一种是提供jar包,开发者可以引入这个依赖。
这两种方案各有优缺点。Pinpoint 和 Skywalking 使用 javaagent 方案,Zipkin、Jaeger 和 Cat 使用第二种方案,Dog 也使用手动添加依赖项的第二种方案。
一般来说,做Traces的系统会选择使用javaagent方案,因为这类系统代理已经完成了所有需要的埋点,没有应用开发者的感知。
最后简单介绍一下Heartbeat的内容。这部分其实是最简单的,但是可以制作很多五颜六色的图表,实现面向老板的编程。
前面我们介绍过Message有两个子类Event和Transaction。这里我们添加一个子类 Heartbeat 来报告心跳数据。
我们主要采集thread、os、gc、heap、client的运行状态(生成了多少棵树、数据大小、发送失败次数)等。同时我们也提供api供开发者自定义数据进行上报. 狗客户端会启动一个后台线程,每分钟运行一次心跳采集程序,上报数据。
介绍更多细节。核心结构是一个Map\,key类似于“os.systemLoadAverage”、“thread.count”等。前缀os、thread、gc等实际上是用于页面上的分类,后缀为显示的折线图的名称。
关于客户,这就是我在这里介绍的全部内容。其实在实际的编码过程中,还是有一些细节需要处理的,比如树太大怎么办,比如没有rootTransaction的情况怎么处理(开发者只叫了Dog. logEvent(...)),比如如何在不调用finish的情况下处理内部嵌套事务等。
狗服务器设计
下图说明了服务器的整体设计。值得注意的是,我们这里对线程的使用非常克制,图中只有3个工作线程。
首先是Kafka Consumer线程,负责批量消费消息。它使用 kafka 集群中的 Tree 实例。接下来,考虑如何处理它。
这里,我们需要对树状结构的消息进行扁平化,我们称这一步为deflate,并做一些预处理,形成如下结构:
接下来,我们将 DeflateTree 分别传递给两个 Disruptor 实例。我们将 Disruptor 设计为单线程生产和单线程消费,主要是出于性能考虑。
消费者线程根据 DeflateTree 的属性使用绑定的 Processor 进行处理。比如DeflateTree中的List problmes不为空,ProblemProcessor是自己绑定的,所以需要调用ProblemProcessor进行处理。
科普时间:Disruptor是一个高性能队列,性能优于JDK中的BlockingQueue
这里我们使用了 2 个 Disruptor 实例,当然我们可以考虑使用更多的实例,这样每个消费者线程就绑定到更少的处理器上。
我们在这里将处理器绑定到 Disruptor 实例。其实原因很简单。出于性能原因,我们希望每个处理器仅在单个线程中使用它。单线程操作可以减少线程切换带来的开销,可以充分利用系统。缓存,在设计处理器时,不要考虑并发读写的问题。
这里要考虑负载均衡的情况。有些处理器消耗CPU和内存资源,必须合理分配。压力最大的任务不能分配给同一个线程。
核心处理逻辑在每个处理器中,负责数据计算。接下来,我将介绍每个处理器需要做的主要内容。毕竟能看到这里的开发者,应该对APM数据处理真的很感兴趣。
事务处理器
事务处理器是系统压力最大的地方。负责报表统计。虽然 Message 有两个主要子类 Transaction 和 Event,但在实际的树中,大多数节点都是事务类型数据。
下图是事务处理器内部的主要数据结构。最外层是时间。我们在几分钟内组织它。当我们坚持时,它也以分钟为单位存储。
第二层的HostKey代表了哪个应用程序和来自哪个IP的数据,第三层是类型、名称和状态的组合。最里面的统计是我们的数据统计模块。
此外,我们还可以看到这个结构会消耗多少内存。其实主要看我们的类型、名字、状态的组合,也就是会不会有很多的ReportKey。也就是我们在谈客户管理的时候,要避免维度爆炸。
最外层的结构代表时间的分钟表示。我们的报告是按每分钟统计的,然后持久化到 ClickHouse,但是我们的用户在看数据的时候,并不是每分钟都看到的。,所以你需要做数据聚合。下面显示了如何聚合这两个数据。当组合很多数据时,它们的组合方式相同。
仔细想想,你会发现前面数据的计算是可以的,但是P90、P95、P99的计算是不是有点骗人?事实上,这个问题真的是无解的。我们只能想出一个合适的数据计算规则,然后再想这个计算规则,计算出来的值可能就差不多可用了。
此外,还有一个细节问题。我们需要为内存中的数据提供最近 30 分钟的统计信息,只有超过 30 分钟的数据才从 DB 中读取。然后进行上述的合并操作。
讨论:我们能不能丢掉一部分实时性能,每分钟都持久化,读取的数据全部来自DB,这样可行吗?
不,因为我们的数据是从kafka消费的,有一定的滞后性。如果我们在一分钟开始时将数据持久化一分钟,我们可能会在稍后收到上一次的消息。这种情况无法处理。
比如我们要统计最后一小时,那么每台机器获取30分钟的数据,从DB获取30分钟的数据,然后合并。
这里值得一提的是,在交易报告中,count、failCount、min、max、avg是比较容易计算的,但是P90、P95、P99其实并不好计算,我们需要一个数组结构,记录这一分钟内所有事件的时间,然后计算,我们这里用的是Apache DataSketches,非常好用,这里就不展开了,有兴趣的同学可以自己看看。
此时,您可以考虑一下 ClickHouse 中存储的数据量。app_name、ip、type、name、status的不同组合,每分钟一个数据。
样品处理器
示例处理器使用来自放气树中列表事务和列表事件的数据。
我们还按分钟采样,最后每分钟采样,对于类型、名称和状态的每种组合,采集 最多 5 次成功、5 次失败和 5 次慢处理。
相对来说,这还是很简单的,其核心结构如下:
结合Sample的功能更容易理解:
问题处理器
在进行 deflate 时,所有成功 = false 的消息都将放入 List problmes 以进行错误统计。
Problem的内部数据结构如下:
如果你看这张图,你其实已经知道该怎么做了,所以我就不啰嗦了。我们每分钟保存 5 个 treeId 的样本。
顺便提一下Problem的观点:
关于持久化,我们将其存储在 ClickHouse 中,其中 sample 用逗号连接到一个字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
心跳处理器
Heartbeat 处理 List 心跳的数据。顺便说一句,在正常情况下,一棵树中只有一个 Heartbeat 实例。
前面我也简单提到过,Heartbeat 中用来显示图表的核心数据结构是 Map。
采集到的key-value数据如下:
前缀是分类,后缀是图的名称。客户端每分钟采集数据进行报告,然后可以制作很多图表。例如下图展示了堆分类下的各种图:
Heartbeat处理器要做的事情很简单,就是数据存储。Dog UI 上的数据直接从 ClickHouse 读取。
heartbeat_data的列如下:
消息树处理器
我们之前已经多次提到过 Sample 的功能。这些采样数据帮助我们还原场景,这样我们就可以通过trace视图来追踪调用链。
做上面的trace view,我们需要所有上下游树的数据,比如上图就是3个树实例的数据。
正如我们之前在介绍客户端时所说,这些树是由父treeId和根treeId组织的。
要做到这一点,我们面临的挑战是我们需要保存全部数据量。
你可以想想这个问题。为什么我们需要保存全部数据?如果我们直接保存采样的数据不是更好吗?
这里我们使用 Cassandra 的功能。Cassandra在这种kv场景下性能非常好,运维成本非常低。
我们使用treeId作为主键,并添加一列数据。它是整个树的实例数据。数据类型是blob。我们先做gzip压缩,然后扔给Cassandra。
业务处理器
我们在介绍客户端的时候说过,每条Message都可以携带Business Data,但只有应用开发者手动埋藏的时候。当我们发现有业务数据时,我们会做另一件事,就是将这些数据存储在 ClickHouse 中进行业务分析。
我们其实不知道应用开发者会在什么场景下使用它,因为每个人负责不同的项目,所以我们只能做一个通用的数据模型。
回头看这张图,在BusinessData中,我们定义了更通用的userId和bizId,我们认为可能会用到每一个业务场景。userId不用说,bizId可以用来记录订单id、支付订单id等。
然后我们提供三个String类型的列ext1、ext2、ext3和两个数值类型的列extVal1和extVal2,可以用来表达你的业务相关参数。
当然,我们的处理也很简单。将这些数据存储在 ClickHouse 中就足够了。表中主要有这几列:
这些数据对于我们的Dog系统来说肯定是不熟悉的,因为我们不知道你在表达什么业务。类型、名称和状态由开发人员自己定义。我们不知道 ext1、ext2 和 ext3 分别是什么意思。,我们只负责存储和查询。
这些业务数据非常有用,基于这些数据,我们可以做很多数据报表。因为本文讨论的是APM,所以这里不再赘述。
其他
ClickHouse 需要批量编写,否则肯定是不可持续的。通常,一个批次至少有 10,000 行数据。
我们在 Kafka 层控制它。app_name + ip 的数据只会被同一个 dog-server 消费。当然,这并不意味着多个狗服务器消费时会出现问题,但写入ClickHouse的数据会更准确。许多。
还有一个关键点。我们说每个处理器都是单线程访问的,但是有一个问题,那就是Dog UI的请求呢?这里我想了一个办法,就是把请求放到一个Queue中,Kafka Consumer的线程会消费,它会把任务丢给两个Disruptor。例如,如果这个请求是一个交易报告请求,那么其中一个 Disruptor 消费者会发现这是他们想要做的,并且会执行这个任务。
概括
如果你知道 Cat,你可以看到 Dog 在很多地方与 Cat 有相似之处,或者只是说“复制”。我们也考虑过直接使用Cat或者在Cat的基础上做二次开发。
但是看了Cat的源码后,我放弃了这个想法。仔细想了想,正好借用了Cat的数据模型,然后我们自己写一套APM也不难,于是有了这个项目。
写的需要,很多地方重要的我都避而远之,因为这不是源码分析文章,细节就不多说了,主要是给读者一个全貌,读者可以大致思考哪些需要处理通过我的描述,需要写哪些代码,然后当我表达清楚。
欢迎您提出自己的问题或想法。如果有不明白的地方或者我有错误和遗漏的地方,请指正~

