动态网页抓取(来源百度百科动态网页的特点及特点)
优采云 发布时间: 2022-01-14 23:14动态网页抓取(来源百度百科动态网页的特点及特点)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。版权归原作者所有。如有任何问题,请及时联系我们进行处理。
欢迎关注小编,除了分享技术文章,还有很多福利,私信学习资料可领取,包括但不限于Python实战演练、PDF电子文档、采访集锦、学习资料、等等。
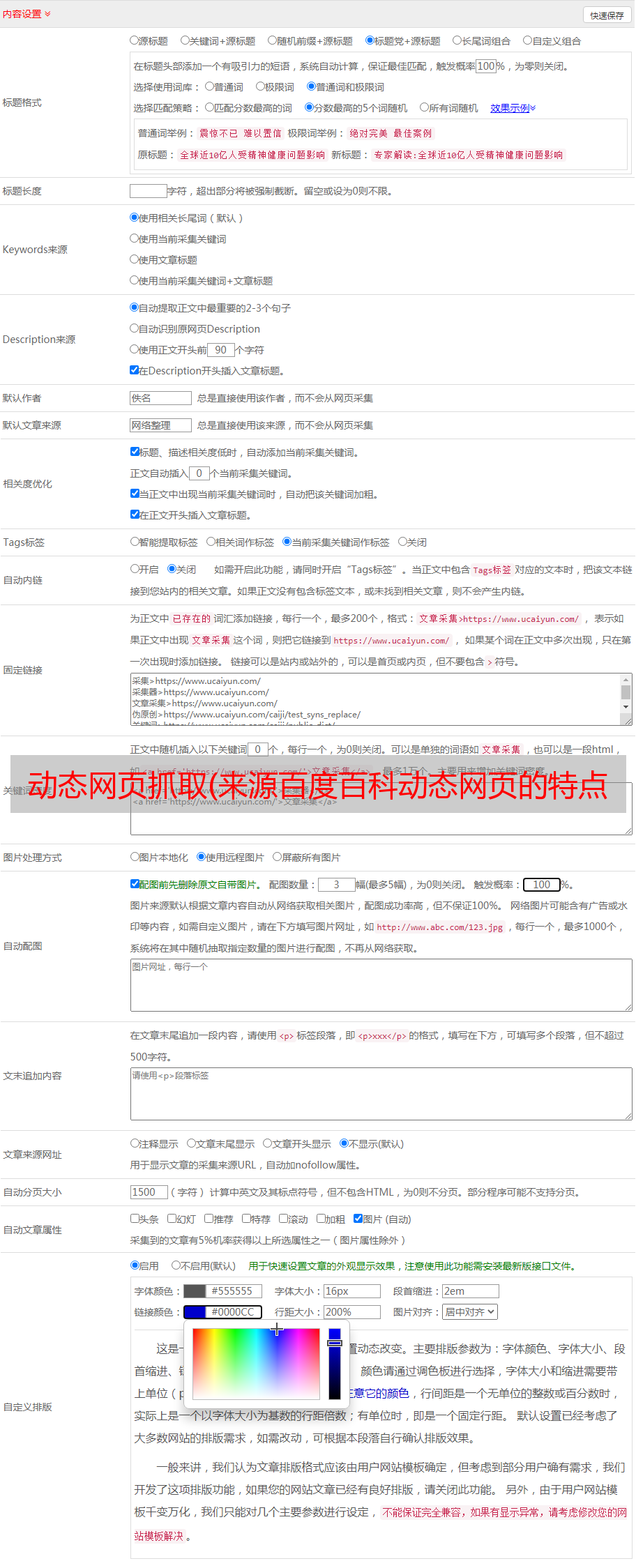
一、什么是动态网页
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量减少、内容更新快、可以完成的功能多等特点。
二、什么是 AJAX
随着人们对动态网页加载速度的要求越来越高,AJAX技术应运而生,成为众多网站的首选。AJAX 是一种用于创建快速和动态网页的技术,它通过在后台与服务器交换少量数据来实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三、如何爬取AJAX动态加载的网页
1. 解析接口
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它悄悄加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站难以解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但已经被广泛的用户爬取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。特点:代码比较简单,爬取速度慢,ip容易被封.
项目实践
*敏*感*词*历年公开的*敏*感*词*信息和执行信息等。
它看起来像这样:
然后,第一页就成功获取了
接下来我加了一个for循环,想花几分钟把网站2164页的32457个*敏*感*词*公告的数据提取到excel中。
那么,就没有了。看完前面的理论部分,你也应该知道这是一个AJAX动态加载的网页。无论您如何点击下一页,网址都不会改变。不信,点进去给你看,左上角的url像山一样耸立在那里:
一、解析接口
在这种情况下,让我们启动爬虫的正确姿势,首先使用解析接口的方法来编写爬虫。
首先,找到真正的请求。右键查看,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。是的,就是这么简单,真正的请求隐藏在里面。
让我们仔细看看这个jsp,简直是宝藏。有一个真实的请求url,一个请求方法post,Headers,和Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数。pagesnum参数不代表页数!我们尝试点击翻页,发现只有pagesnum参数会改变。
既然已经找到了,就赶紧抓起来吧。
构造一个真实的请求并添加Headers。
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,使用post方法请求网页数据。这里注意对返回的数据进行解码,编码为'gbk',否则返回的数据会乱码!此外,我还添加了异常处理优化,以防止意外发生。
构建parse_page函数,解析返回的网页数据,用Xpath提取所有字段内容,保存为csv格式。
最后,遍历页数,调用函数。OK完成!
让我们看看最终的结果:
综上所述,对于AJAX动态加载的网络爬虫,一般有两种方式:解析接口;硒。建议解析接口。如果解析了json数据,那就更好的爬取了。真的没有办法使用 Selenium。

