集搜客网页抓取软件(集搜客的工作原理和待抓网址的安装方式介绍)
优采云 发布时间: 2021-12-27 23:09集搜客网页抓取软件(集搜客的工作原理和待抓网址的安装方式介绍)
关于鹅
我们先截取官网的一些介绍,先了解一些概念,以后看会容易一些。采集
客户组成结构
Gooseeker 由服务器和客户端组成。服务器用于存储规则和线索(要抓取的URL),MS用于制定网络爬取规则,DS计数器用于采集
网页数据。
极手客的工作原理 用MS手手制定规则后,规则会保存在极手客的服务器中,样本URL将作为线索(要抓取的URL)存储在服务器中。PS:规则虽然保存在服务器中,但可以随时查看和修改。DS点数机采集数据,是利用制定好的规则采集要爬取的URL的网页数据的过程。详情请参考DS计数机如何采集数据一文。如果采集成功,会在本地文件夹DataScraperWorks中生成结果文件。如果是层级规则,除了生成结果文件外,捕获的URL会作为下一级规则中要捕获的URL存储在服务器中,并将在采集
数据时按顺序执行。也可以通过 DS 计数器添加要捕获的常规 URL。详情请参考如何添加新线索一文。安装
看完上面的概念,我们来安装一下。首先,gooseeker 作为 Firefox 插件运行。官网提供了两种安装方式(独立爬虫是测试版,暂时没有)——用firefox打包或者单独下载。官网下载地址推荐使用打包方式,因为firefox最新版本不支持单独安装(如果可以,欢迎面子)。安装完成后,我们打开firefox,可以看到又多了两个插件——一号和一号,现在就可以开始爬虫了。
利用
这里我们抓取豆瓣书的内容作为演示。我们将通过制定规则来抓取网站上的图书信息。首先,为了抓取网站上的图书信息,我们需要选择一个入口页面,然后一层一层的往下走,得到一个网内所有的图书信息,所以我们选择了豆瓣阅读标签,它有大量标签。通过点击这些标签,我们可以找到每个标签下的书籍列表,通过点击书籍的链接,我们可以得到我们需要的数据。下面,我们开始一步步进行:
抓取页面中的特定元素
先来了解一下魔说的操作。首先,从爬取网页元素的第一步开始。如果我们要制定采集
规则,那就打开魔说,可以看到下图。
广告优采云
,支持全网98%以上采集
,免费使用^优采云
,支持自动云端采集
,傻瓜式操作,无需编程^^自由易学,50W+用户的选择...
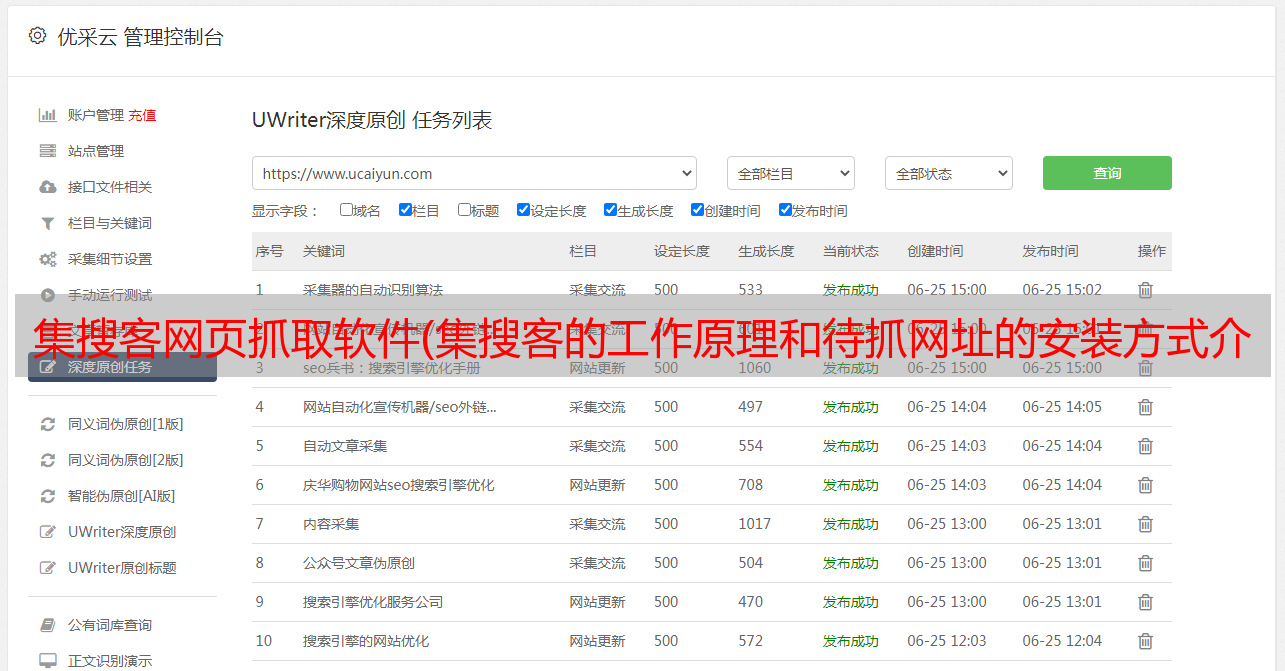
在框1中输入要获取的URL(这里我们输入“”),回车加载,到框2中获取当前规则集的主题名称,最后点击check按钮确认是否为可用的。
因为规则存储在 gooseeker 的服务器上,所以它们不需要与所有现有主题(包括其他用户的规则)重名
第二步,我们要在网页中选择需要的数据,点击工作台的“创建规则”选项卡,如下图:
广告每日免费在线学习doyoudo ps教程免费,国内品牌机构专业授课,O基础快速学习,1小时快速^^入门,7天doyoud...
首先我们需要新建一个排序框,这里命名为“category”,然后点击2号框,那么html中这部分内容的dom结构就会显示在最上面MDS。我们可以选择需要的内容,添加到排序框,具体操作方法是:右键-内容映射-新建爬取内容,取一个字段名即可,如下图,我们分别映射url和name到分拣箱:
学习广告程序开发难吗?学习程序开发通常需要120天,你可以完全掌握。
上图中,除了标注的映射,可以看到我还画了两个圆圈,分别圈出了重点内容和下级线索。关键内容是为爬虫进行采集提供一个判断标记,对肯定会出现在页面上的内容进行检查。下一章会讲解下层的线索,先卖掉吧~
第三步,使用sample copy 在第二步中,我们只是在第一个标签中选择了我们需要的数据。整个页面中还有许多其他标签。这时候就需要用到sample copy函数,具体流程如下:
广告新手怎么学ps?新手教程ps教程自学网
首先,单击“类别”排序框。在样本副本管理中,选中“启用”。然后,点击刚才的第一个节点“BL”,取其网页标签(取与其他节点平行的图层标签);然后,右击标签--sample copy mapping--第一个,让橙色标记的sample 1显示位置;最后,对第二个节点执行相同的操作,并将其映射到第二个示例。
验证规则的正确性
广告ps免费教程,0基础小班教学,真实项目实战教学,ps免费教程,120天从小到大!
完成第三步后,我们点击“验证”按钮即可知道规则是否正确。如果正确,就会显示粉红色箭头所指的xml内容。可以对比一下网页中的标签,应该都爬下来了。最后一定要记得保存!!!点击绿色方框~
使用计数机
我们刚刚制定了一套简单的规则,你可以使用计数机抓取对应URL上的数据。进入点钞机有两种方式:
一种是使用木座站右侧保存按钮的抓取数据,另一种是使用firefox界面上的图标
广告PS使用教程,0基础小班教学,真实项目实战教学,PS使用教程,120天从童年到大咖!
打开点钞机,可以看到已经制定的规则。如果没有,在搜索栏中输入*进行搜索,即可全部显示!我们右击规则,可以看到图中的菜单: 抓取网页:顾名思义,就是抓取规则中的线索(即url)。浏览主题:点击没有效果,看不清楚。统计线索:显示不同状态的线索数量。这些状态包括(待抓取、已抓取)(中、规则不适用、超时、抓取错误、抓取完成)管理线索:添加线索、激活失败线索、激活所有线索、取消所有线索所有标签的名称和链接,但是我们实际需要的数据并不是这些,所以我们需要进入它的下一层。以标签“东野圭吾”为例~首先,我们打开这个页面:
学习python爬虫的难点是什么?就业前景如何?Python人才缺口近30万成为下一个紧缺的IT金领
和上一章一样,我们新建一个主题名,然后配置规则。从这个页面,我们可以看到它与上一页类似。我们需要的是每本书的标题和链接。通过上一章的那些步骤就可以完成了。那么,既然这个页面的URL要从上层爬取,那我们应该怎么做才能把两层连接起来呢?在上一章中,我们检查了 URL 中的低级线索。如果勾选,则采集
到的数据将作为下一级线索(url)进行爬取。很多网站上的url都是相对路径,不过没关系,gooseeker会自动帮我们补全,所以我们的操作还是挺简单的。. 我们先把刚才做的规则保存起来,然后打开上一章保存的规则。如何打开它?
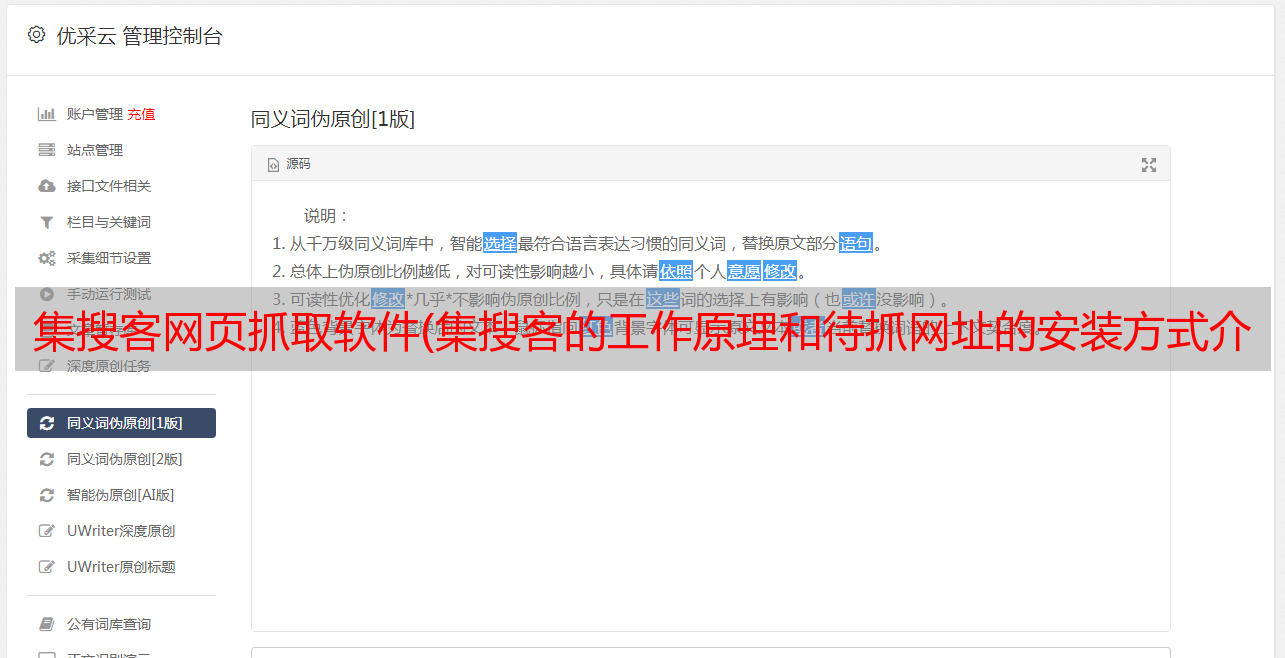
在继续此步骤之前,请确保已保存当前规则!然后我们点击工作台的“搜索规则”选项卡,填写搜索我们所有的规则,找到上一章制定的规则,右键--加载,然后点击木祖师台上面的文件- 后续分析
那么,我们就可以修改这条规则了!
广告ps使用教程,在线学习ps使用教程/平面设计/后期修图教程,零设计基础快速入门^^3秒注册会员免费在线学习,快速提升ps...
我们点击“Crawler Route”选项卡。因为之前检查过下级线索,所以在操作区下方的框中已经有线索1了。我们需要将二级规则的主题名称填入目标主题名称*中,然后保存,这样两组规则就连接起来了。
爬取分层网页时,需要先爬取上层,然后将得到的下层URL自动添加到第二层要爬取的线索中。关于换页,我们继续回到第二套规则。我们爬取到的标签东野圭吾被分成了很多页,如下图所示: 我们需要在规则中加入换页操作,否则只能爬取第一页的数据。
广告python网络爬虫工具免费教程下载+0元直播课,进*敏*感*词*流学习,快速上手精通,^^推荐就业,轻松进名企,选...
图中粉色箭头表示我们需要操作的内容和顺序。左边的蓝色框需要注意,不要搞错,否则右边框中的文字不会出现!点击新建,这样就会生成线索 2 勾选Continuous Grab 取选中的标记线索,点击网页中的“下一页”选项卡,在dom结构中找到它的text属性,右键-线索映射-标记映射。完成以上步骤后,标记值和标记位置编号就会有对应的值。完成这些步骤后,我们还没有定义翻页,还缺少一个重要的链接!完成标记映射后,要映射线索位置,选择收录
标记标记的范围进行映射。
广告无需下载,永久免费专业在线免费ps,支持多人实时协作,支持多种格式导入导出设计文件,原生代码注释,永久历史版本...
首先我们选中整个翻页模块(一般左手点击几下就可以选中),然后上面的dom结构跳转到div节点,我们直接右键it-clue mapping-positioning - -线索2,保存在最后~我们可以在网页中抓取该书的书名、出版信息、豆瓣评分、内容介绍和书籍封面。操作和上一张类似,就不说了,但是最后一张图呢?爬行呢?让我们来看看
下载图片和普通文本数据有两个区别:一是要在那里检查,二是需要把图片的src属性映射到字段
官网教程很多,本文只介绍一些常用的功能,如果有进一步的需求,可以
[1] 集搜客的工作原理 [2] 不懂的请看这里![3] 如何从多层次网页采集数据——以京东商品信息采集为例 [4] 如何翻页抓取 获取网页数据——以采集天猫搜索列表为例 [5] 如何采集一边抓取网页一边下载图片

