网站内容采集(互联网的数据千奇百怪,如何有效采集到想要的大数据?)
优采云 发布时间: 2021-12-25 20:07 网站内容
" rel="nofollow" target="_blank">采集
不知道什么时候开始的 大数据、大数据、大数据……大数据技术、大数据应用共享、大数据金矿、大数据下的智慧城市等等,都与数据有着密切的关系!
数据!它从哪里来的?
它来自以下几个方面:
1、 企业内部数据;
2、 外部采购的脱敏数据;
3、 终端设备的采集,其实可以看成是企业内部的数据;(音频、视频、图像等);
4、网络采集
(各大搜索引擎、微信、微博、各大电商平台、论坛帖子等)。
1、2、3的三个数据源就不强调了!在这里,我主要分享一下互联网数据采集过程中遇到的一些问题。
互联网上的数据如此陌生,如何才能有效地采集
到我们想要的数据呢?
互联网环境非常复杂。既然有人要采集
数据,网站服务器就会守护!是不是别人设置了门槛,我就不采集
数据了?俗话说,道高一尺,魔道高一尺!让我们一一看看吧!如果你想成功采集
你想要的数据,你必须从网站反爬策略开始。
策略一、访问频率
访问频率可以有效防止用户频繁访问或机器人抓取数据。这种方式最受欢迎的网站:赶集,58、各大电商平台,主要通过统计访问IP,达到一定的访问频率后,将采取以下措施:
1、 限制访问。几分钟就可以正常访问;
2、 直接返回错误页面。例如:404或其他异常页面;
3、 弹出验证码界面,验证您的身份。有关此类问题的详细信息,请参见“方法 2”。
对于1、2的两个措施,可以使用动态IP代理,在稍微增加用户访问时间的同时,降低单个IP访问的频率。
策略二、 验证码块
例如快递单号、搜狗微信、新浪微博等都会使用验证码来验证用户的访问身份。
公司的iRIS互联网非结构化数据采集平台为此类问题提供了全方位的解决方案。验证码识别率可达95%以上。欢迎联系我们!
策略三、用户代理
HTTP 协议请求头信息的一部分。为了防止采集程序通过模拟HTTP协议进行采集,大多数网站一般会通过User-Agent信息进行验证。因为一般的机器人不会设置User-Agent,当然User-Agent还有一个用途,可以用来设置对应的手机访问协议,模拟访问手机的网页。下次有机会再说!
知道了它们的原理,你只需要在HttpClient上设置User-Agent头信息,是不是很简单!
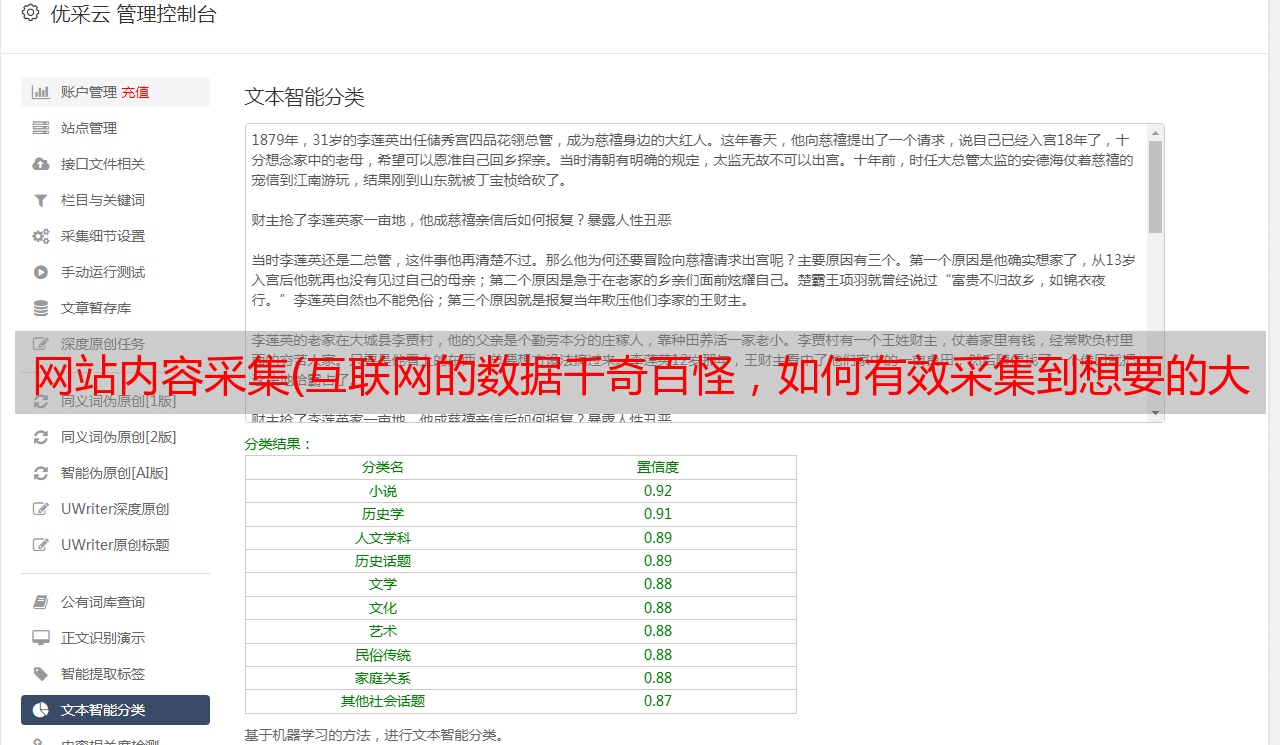
在大数据时代的环境下,数据分析所需的70%以上的数据分散在互联网的各个角落。我们如何快速采集
这些数据?换句话说,有没有现成的采集
工具?
北京爱迪特信息技术*敏*感*词*自主研发的iRIS互联网非结构化数据采集平台,操作界面可视化,操作简单,上手快捷,绝对让您惊喜连连!
文章为原创,欢迎采集
或采集
。如果你有大数据爱好者,欢迎一起讨论。
关于IDEADATA:IDEADATA 专注于从数据到信息的有效管理和应用。是领先的商业信息服务技术提供商,也是数据仓库和大数据技术与应用的先驱。
关注微信:IDEADATA大数据愿景
新浪微博:iDEADATA大数据愿景
公司官网:

