seo优化搜索引擎工作原理( SEO实战密码之搜索引擎工作原理详解工作过程接下来的几节)
优采云 发布时间: 2021-12-24 04:21seo优化搜索引擎工作原理(
SEO实战密码之搜索引擎工作原理详解工作过程接下来的几节)
SEO实战密码搜索引擎工作原理详细搜索引擎工作过程很复杂下面几节我们简单介绍一下搜索引擎是如何实现页面排名的。这里介绍的内容相对于真正的搜索引擎技术来说只是小菜一碟,但是对于SEO人员来说已经足够了。搜索引擎的工作过程大致可以分为三个阶段: 1.爬行和爬行。搜索引擎蜘蛛通过链接访问网页,获取网页的HTML代码并将其存储在数据库中。2. 预处理索引程序对抓取的页面数据进行文本提取中文分词索引等处理准备排名程序调用3个排名用户输入关键词 排名程序调用索引库数据计算相关性后,然后按照一定格式公文格式IOU标准格式个人IOU标准格式个人IOU格式生成搜索结果页面一爬爬爬爬爬爬是第一步搜索引擎工作完成数据采集任务 1.蜘蛛搜索引擎用来抓取和访问页面的程序称为蜘蛛蜘蛛,也称为机器人搜索引擎。蜘蛛访问网站页面时,与普通用户使用的浏览器类似。蜘蛛程序发送页面访问请求,服务器返回HTML。代码蜘蛛程序将接收到的代码存储在原创页面数据库搜索引擎中。为了提高爬行和爬行速度,多个蜘蛛用于并发分发。爬虫在访问网站中的任何一个时,都会首先访问网站根目录下的robotstxt文件。如果robotstxt文件禁止搜索引擎爬取某些文件或目录蜘蛛,他们将遵守协议不爬取被禁止的URL。和浏览器一样,搜索引擎蜘蛛也有一个代理名称来表明他们的身份。查看特定代理名称的搜索引擎,以确定列出了常见的搜索引擎蜘蛛的名字·Baiduspiderhttpwwwbaiducomsearchspiderhtm百度蜘蛛·Mozilla50compatibleYahooSlurpChinahttpmiscyahoocomcnhelphtml雅虎中国雅虎蜘蛛的蜘蛛·Mozilla50compatibleYahooSlurp30httphelpyahoocomhelpusysearchslurp英语·Mozilla50compatibleGooglebot21httpwwwgooglecombothtmlGoogle蜘蛛·msnbot11httpsearchmsncommsnbothtm微软Bing蜘蛛蜘蛛··Sogouwebrobothttpwwwsogoucomdocshelpwebmastershtm07搜狗搜索引擎下面Sosospiderhttphelpsosocomwebspiderhtm蜘蛛, Mozilla50兼容YodaoBot10httpwwwyodaocomhelpwebmasterspider有道蜘蛛2。跟踪链接 为了在互联网上抓取尽可能多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面。它' 就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的由来。整个互联网是由彼此组成的。链接的网站和页面的组成。从理论上讲,蜘蛛可以从任何页面爬行,并通过链接访问互联网上的所有页面。当然是因为网站
在互联网的实际工作中,蜘蛛的带宽资源时间不是无限的,不可能爬满所有的页面。事实上,最大的搜索引擎只是爬取和收录互联网的一小部分。深度优先和广度优先通常是混合的。使用这种方法可以尽量*敏*感*词*称等级表 员工考核评分表 普通年金现值系数表 提交的网址蜘蛛根据重要性从地址库中提取要访问的网址,抓取页面后删除将要访问的URL中的URL 从地址库中删除,放入访问地址库中。大多数主流搜索引擎都提供了一个表单供站长提交网址,但这些提交的网址只存储在地址库中。收录 是否取决于页面的重要性 如何搜索引擎 收录 大部分页面都是蜘蛛通过链接本身获取的。可以说提交的页面基本没用了。搜索引擎更喜欢沿着链接本身发现新页面。文件存储搜索引擎蜘蛛抓取的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。每个 URL 都有一个唯一的文件编号。爬取时复制内容检测检测和删除复制内容通常在下面介绍的预处理过程中,但是现在蜘蛛在爬取和爬取文件时也会进行一定程度的复制内容检测,遇到非常低的权重网站 @网站上的转载或抄袭内容数量可能无法继续爬取。也就是说,有的站长在日志文件中发现了蜘蛛,但是页面从来没有真正被收录 第二个原因是预处理。在一些 SEO 材料中,预处理也称为索引,因为索引是预处理中最重要的步骤。搜索引擎蜘蛛抓取的原创页面不能直接用于查询搜索引擎数据库中的页面数。所有万亿级以上的用户都输入搜索词,依靠排名程序实时分析这么多页面。计算量太大,无法在一两秒内返回排名结果。因此,爬取的页面必须经过预处理成为最终的查询排名。预处理与爬行和爬行相同。用户在后台提前搜索时是感受不到这个过程的。目前的搜索引擎还是以文字内容为主。除了用户可以在浏览器上看到的可见文本,蜘蛛抓取的页面中的HTML代码中含有大量的HTML格式标签、JavaScript程序等,无法用于排名。首先要做的是从HTML文件中去除标签,并提取网页的文本内容,可用于排名处理。例如下面的HTML代码divide"post-1100"class"post-1100posthentrycategory-seo"divclass"posttitle"h2ahref今天愚人节哈"今天愚人节哈ah2" httpwww55likecomseoblog20100401fools-day"rel"b
PermanentLinkto 去掉 HTML 代码后,剩下的用于排名的文字就只有这一行了。今天愚人节,除了可见的文字,搜索引擎还会提取一些收录文字信息的特殊代码,比如Meta标签中的文字图片代替文字,文字Flash文件代替。文本链接、锚文本等。 2、中文分词是中文搜索引擎独有的一步。搜索引擎存储和处理页面,用户搜索基于单词。英语和其他语言单词高中英语3500词汇表和单词之间有一个空格。搜索引擎索引程序可以将句子直接划分为一组单词,中文单词和单词之间没有任何分隔符。一个句子中所有的词和词都连接在一起 搜索引擎首先要区分哪些字符构成一个词,哪些词本身就是一个词。例如,减肥方法将细分为减肥和方法。基本上有两种中文分词方法。一种是基于词典匹配,另一种是基于词典匹配的统计方法,是指将一段待分析的汉字与预先建立的词典中的一个词条进行匹配。将待分析的汉字字符串扫描到字典中已有的词条,将匹配成功或拆分出来。基于字典匹配的方法,一个词根据扫描方向可以分为正向匹配和反向匹配。根据匹配长度的优先级,可分为最大匹配和最小匹配。首先混合扫描方向和长度,可以生成正向最大匹配反向。不同的方法如最大匹配 字典匹配法计算简单,其准确率很大程度上取决于字典的完整性和更新性。统计分词法是指对大量文本样本进行分析,计算出一个词与一个词相邻出现的统计概率,相邻出现的几个字符越多,形成一个词的可能性就越大。 . 基于统计的方法的优点是对新词反应更快,也有利于消除歧义。字典匹配和基于统计的分词方法在实际使用中各有优缺点。分词系统是两种方法的混合,速度快,效率高,可以识别新词,消除歧义。中文分词的准确性往往会影响搜索引擎排名的相关性。例如,百度搜索引擎优化截图如图2-22所示。可以看出,百度将搜索引擎优化的这六个词视为一个词。图2-22 百度快照为搜索引擎优化的分词结果,谷歌搜索中相同的词如图2-23所示。快照显示谷歌对待它。为搜索引擎和优化分词为三个词 显然百度分词更合理。搜索引擎优化是一个完整的概念。当 Google 分词趋向于更详细的时候,图 2-23 展示了 Google 快照中显示的搜索引擎优化的分词结果。另一个比较明显的例子是谷歌搜索点石互动的四个词,如图2-24所示。快照显示,谷歌将其划分为点石。而中国SEO领域最知名的品牌点石互动三个字,显然没有进入谷歌的词典。图 2-24 谷歌快照展示了点石互动的分词结果。当你在百度上搜索点石互动时,你会发现百度江点。石互动一句话,即使在百度上搜索“点石会议”,也可以发现百度把“点石会议”当成一个词,如图2-25所示。上面的差异大概是部分关键词排名在不同搜索引擎中表现不同的原因之一。例如,百度更喜欢完全匹配页面上的搜索词,也就是说,在点石互动连续搜索这四个词时,完整的外观更容易在百度上获得好的排名。谷歌与此不同。它不需要完全匹配。有些页面有“点石”和“互动”两个词。在谷歌搜索点石互动时,该页面也可以获得很好的排名。搜索引擎的分词取决于词库的规模和准确度以及分词算法的质量,而不是页面本身。那么SEO人员对于分词能做的事情很少,唯一能做的就是用某种形式提示搜索引擎某个词应该被当作一个词来处理,尤其是当它可能造成歧义的时候,比如乘以页面标题。一级题库二元线性方程应用题Truth or Dare Exciting题出现在h1标签和黑体关键词如果页面是关于和服的内容,那么和服这两个词可以特别用黑体标出如果页面是关于化妆和服装的,可以用粗体标记服装这两个词,以便搜索引擎分析页面时,它会知道加粗的单词应该是一个单词 3. 停用词,无论是英文还是中文页面内容,都会有一些经常出现但对内容没有影响的词,比如ahhaya之类的感叹词,和副词如qu或介词这些词被称为停用词,因为它们对页面的主要含义影响不大。英文中常见的停用词有theaantoof等,如果页面是关于和服的内容,那么kimono这两个词可以专门用粗体标出。如果页面是关于化妆和服装的,可以将服装这两个词加粗,这样搜索引擎在分析页面时就会知道应该加粗。它是一个词 3. 停止词,无论是英文还是中文页面内容,会有一些经常出现但对内容没有影响的词,比如ahhaya等感叹词,以及qu或介词等副词,这些词被称为停用词,因为它们对页面的主要含义影响不大。英语中常见的停用词有 theaantoof 等。
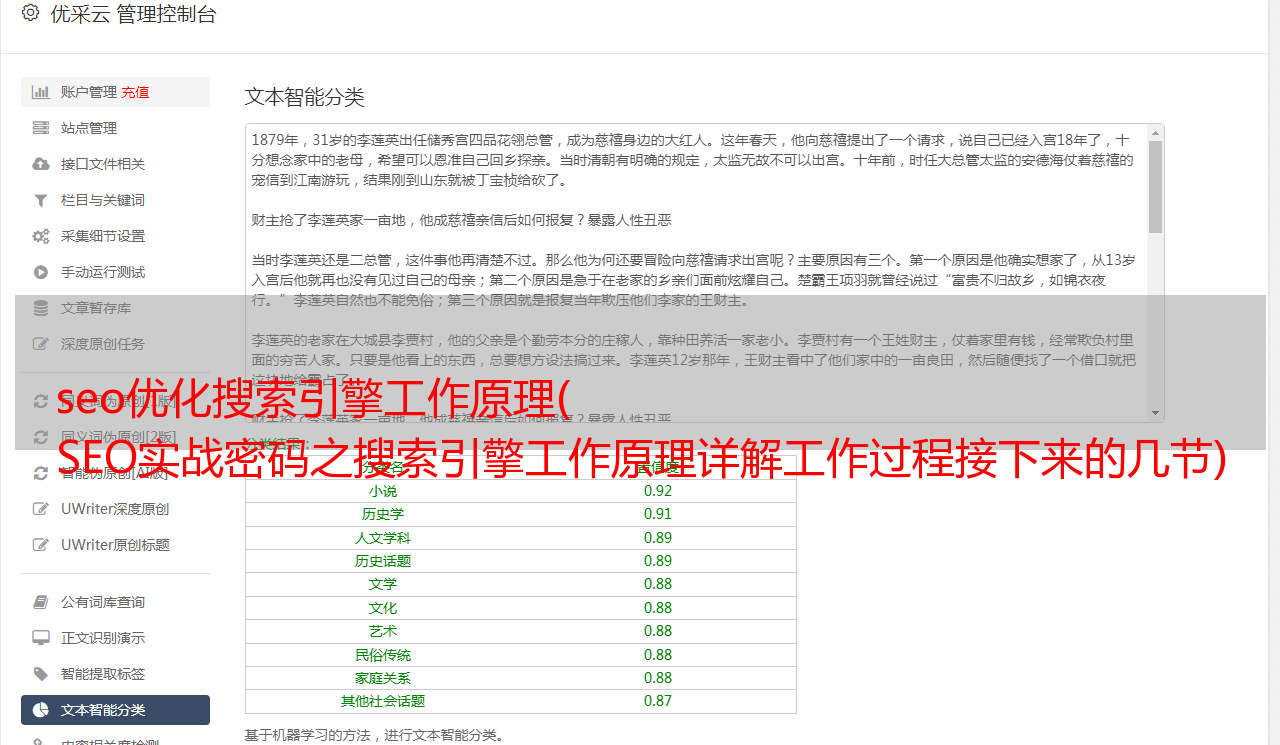
搜索引擎会在索引页面前去除这些停用词,使索引数据的主题更加突出,减少不必要的计算量4。消除噪音。大多数页面上都有一些对页面主题没有贡献的内容,例如版权声明文本导航栏广告等。以常见的博客导航为例,几乎每个博客页面都会出现文章分类历史档案等导航内容,但这些页面本身与分类历史中的词无关。这些关键词的用户搜索历史分类仅仅因为这些词出现在页面上并返回到博客帖子中是没有意义的,完全无关紧要。所以这些块都属于噪声。搜索引擎需要识别并消除这些噪音。在排名时,他们不使用噪音。去噪的基本方法是基于 HTML 标签对页面进行屏蔽。网站 上的大量重复块往往是噪音。页面去噪后,剩下的就是页面的主要内容了。重复数据删除搜索引擎也需要对页面进行重复数据删除。同一篇文章文章经常在不同的网站和同一个网站上重复。搜索引擎不喜欢这种重复。用户在前两页搜索*敏*感*词*内容,如果看到来自不同网站文章的同一篇文章,用户体验太差了,虽然所有内容相关的搜索引擎都希望只返回相同的内容文章@中的一篇文章> 所以在索引之前有必要识别和删除重复的内容。这个过程称为重复数据删除和重复数据删除。基本方法是计算页面特征关键词的指纹,也就是说从页面的主要内容中选择关键词中最有代表性的部分,也就是经常出现频率最高的关键词然后计算这些关键词的数字指纹。这里的关键词选择就是通过分词停止去词。在噪声之后,实验表明通常选择10个特征关键词可以达到比较高的计算精度,再选择更多的词对去重精度的提高贡献不大。典型指纹计算方法如MD5算法资料摘要算法第五版 该类指纹算法的特点是输入特征关键词 任何微小的变化都会导致计算出的指纹出现很大的差距。在了解了搜索引擎的去重算法之后,SEO人员应该知道,单纯的加地是要改变段落的顺序的。所谓的伪原创也逃不过搜索。引擎的去重算法无法因为这个操作改变文章关键词的特性,而搜索引擎的去重算法很可能不仅仅在页面层面,而是在段落层面。改变段落顺序不会让转载抄袭变成原创6。前向索引 前向索引也可以称为索引。经过文本提取、分词、去噪和去重后,搜索引擎获取唯一能反映页面主要内容的基于词的内容。然后搜索引擎索引程序就可以提取出来了。关键词根据分词程序,将页面转换成一组关键词,记录每个关键词在页面上的出现频率. 格式如出现在标题标签、加粗H标签锚文本等位置,如页面第一段等,这样每一页都可以记录为一串关键词集合,其中每个关键词的词频格式位置等权重信息也记录在搜索引擎索引程序中的页面和关键词构成词汇结构,存储在索引库中。简化的索引词汇表如表2-1所示。表2-1 简化的索引词汇结构。每个文件对应一个文件 ID。文件的内容是以关键词的字符串表示的集合,其实在搜索引擎索引库中关键词也被转换成了关键词的ID。这种数据结构称为前向索引7。倒排索引前向索引不能直接用于排序。假设用户搜索关键词2,如果只有前向索引,排序程序需要扫描索引库中的所有文件,找到收录关键词2的文件,然后才能继续。相关性计算等计算量不能满足实时返回排名结果的要求,所以搜索引擎会将正向索引数据库重组为倒排索引,并将文件到关键词的映射转换为关键词到文件的映射如表2-2所示。在倒排索引中,关键词是主键。每个 关键词 对应一系列文件。这出现在这些文件中。@关键词这样,当用户搜索某个关键词时,排序程序在倒排索引中定位这个关键词,可以立即找到收录这个关键词表的所有文件2-2 倒排索引结构 8. 链接关系计算 链接关系计算也是预处理中非常重要的部分。现在所有主流的搜索引擎排名因素都包括网页之间的链接流信息。搜索引擎在抓取页面内容后,必须预先计算页面上的哪些链接指向。每个页面上还有哪些其他页面以及用于链接的锚文本是什么?这些复杂的链接指向关系构成了网站和页面的链接权重。GooglePR 值是这种链接关系最重要的体现之一。其他搜索引擎虽然不叫,但也进行类似的计算
由于互联网上的页面和链接数量庞大,PR在不断更新,因此链接关系和PR的计算需要很长时间。PR和链接分析有专门的章节。特殊文件处理 除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDFWordWPSXLSPPTTXT 文件等,我们经常在搜索结果中看到这些文件类型,但目前的搜索引擎无法处理它们。图片和视频 Flash 等非文本内容无法执行脚本和程序。尽管搜索引擎在识别图像和从Flash中提取文本内容方面取得了一些进展,但离直接读取图像和视频并从Flash内容中返回结果的目标还很远。对于图像和视频,内容的排名往往是基于与之相关的文本内容的详细信息。您可以参考下面的集成搜索部分。三个排名由搜索引擎蜘蛛抓取页面索引程序计算。倒排索引计算完成后,搜索引擎就可以随时处理用户搜索了。用户填写搜索框关键词后,排名程序调用索引库数据计算排名并展示给用户。排名过程与用户直接交互。搜索词处理 搜索引擎收到用户输入的搜索词后,需要对搜索词进行一些处理,才能进入排名过程。搜索词处理包括以下几个方面:1 中文分词与页面索引相同。搜索词也必须是中文分词。查询字符串Convert to word-based 关键词 组合分词原理与页面分词相同。2 停止词与索引时相同。搜索引擎还需要去除搜索词中的停用词,以最大限度地提高排名相关性和效率。3 指令处理查询后,搜索引擎默认的处理方式是使用关键词之间的逻辑,也就是说当用户搜索减肥方法时,程序分词是减肥和方法。当搜索引擎排序时,它默认为用户寻找同时收录减肥和方法的页面,只收录减肥但不收录方法或只收录方法不收录减肥的页面被认为不符合搜索条件。当然,这只是解释原理的非常简化的说法。其实我们还是会看到只有关键词的一部分,另外,用户输入的搜索结果中还可能收录一些加号、减号等高级搜索命令。搜索引擎需要相应地识别和处理它们。高级搜索命令后面有详细说明。4 如果用户输入了明显的错误单词或英文单词拼写错误,则更正拼写错误。搜索引擎将提示用户使用正确的单词或拼写,如图 2-26 所示。图 2-26 输入错误拼写的更正。5 集成搜索触发某些搜索词将触发集成搜索。比如名人名字经常触发图片和视频内容,时下热门话题和容易触发的信息内容。在搜索词处理阶段还需要计算哪些词触发哪个集成搜索。文件匹配搜索词处理后,搜索引擎得到关键词的基于词的集合。文件匹配阶段是查找所有收录关键词的文件。索引部分中提到的倒排索引使文件匹配。可以快速完成如表2-3所示。表2-3 倒排索引快速匹配文件。假设用户搜索关键词2关键词7排名程序,只要在倒排索引中找到关键词2和关键词7字样,就可以找到所有页面收录这两个词的。经过简单的计算,可以找到同时收录关键词2和关键词7的所有页面文件。1和文件63。发现初始子集的选择收录所有关键词
选择页面特征的初始子集。初始子集有多少万,可能更多的*敏*感*词*的文本。5。排名过滤和调整。选择匹配文件的子集并计算相关性后,就确定了总体排名。之后,搜索引擎可能会有一些过滤算法来稍微调整排名。最重要的过滤是对一些涉嫌作弊的页面进行处罚。正常的权重和相关性计算排在第一位,但搜索引擎的惩罚算法可能会在最后一步将这些页面移到后面。一个典型的例子是百度的11位谷歌的减6减30减950等算法6。排名显示,所有排名程序在排名确定后都调用了原页面的title标签。页面上会显示描述标签快照日期等数据。有时搜索引擎需要动态生成页面摘要,而不是调用页面本身的描述标签。7、搜索缓存用户搜索到的关键词很大一部分是重复的。根据28定律,20个搜索词占总搜索次数的80次。根据长尾理论,最常见的搜索词不会占到多达 80 个,但通常有一个。搜索词头部相对较大的部分占了所有搜索次数的很大一部分,尤其是在有热点新闻的时候,每天可能有数百万人搜索完全相同的关键词8。查询并点击日志搜索用户的IP地址搜索关键词

