使用新浪微博开放平台api同步微博内容至自己网站(关于新浪微博爬虫的一些事儿,你知道吗? )
优采云 发布时间: 2021-12-21 21:05使用新浪微博开放平台api同步微博内容至自己网站(关于新浪微博爬虫的一些事儿,你知道吗?
)
最近和孙承杰老师在NLP实验室做了一些事情。我打算结合新浪微博的用户数据,基于文章的“多标签分类”算法,看看实验的效果。于是找了一些关于新浪微博爬虫的资料,整理如下:
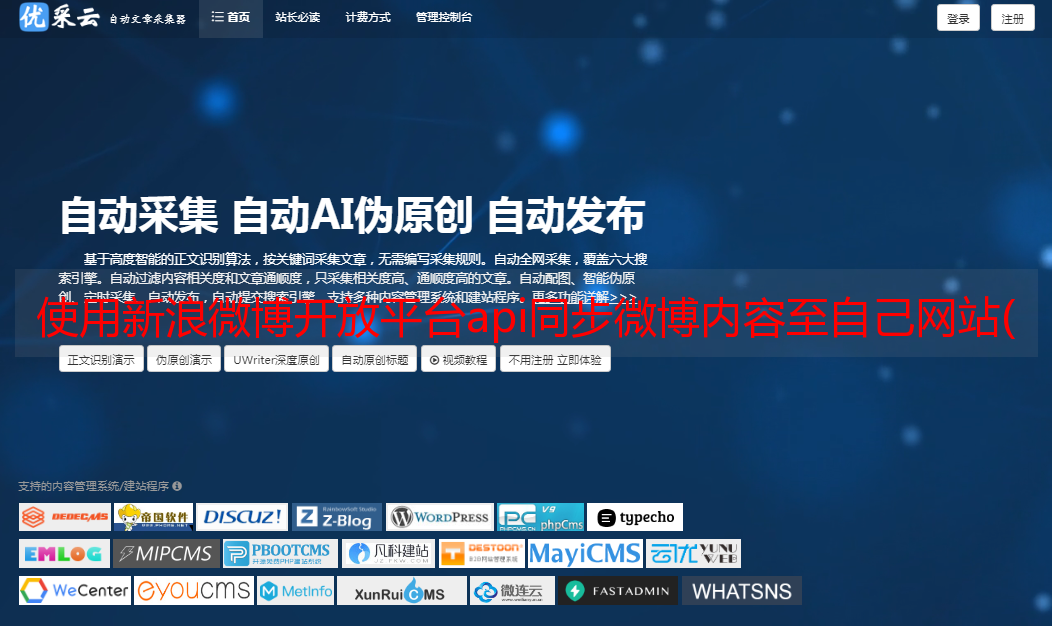
(一)模拟登录新浪微博(Python)(使用python程序获取cookie登录)
更新:如果只是写个小爬虫,访问需要登录的页面,使用填cookies的方法,简单粗暴有效。有关详细信息,请参阅:
模拟登录有时需要了解js加密(散列)方法、输入验证方法等,同一段代码很难一直有效。
文本:
PC登录新浪微博时,用户名和密码在客户端用js进行了预加密,POST前会GET一组参数,也是POST_DATA的一部分。这样就不能用通常的简单方法来模拟POST登录(如人人网)。
由于部分要使用的微博数据不方便通过API获取,所以还是要自己写一个小爬虫,模拟登录是必不可少的。想了想这件事,最后还是登录成功了。
1、在提交POST请求之前,需要GET获取两个参数。
地址为:(v1.3.18)
得到的数据中收录了“servertime”和“nonce”的值,是随机的,其他的值好像没什么用。
2、通过httpfox观察POST数据,参数比较复杂,其中“su”为加密用户名,“sp”为加密密码。“servertime”和“nonce”是从上一步获得的。其他参数不变。
username 经过了BASE64 计算: username = base64.encodestring( urllib.quote(username) )[:-1];
password 经过了三次SHA1 加密, 且其中加入了 servertime 和 nonce 的值来干扰。
即: 两次SHA1加密后, 将结果加上 servertime 和 nonce 的值, 再SHA1 算一次。
将参数组织好, POST请求。 这之后还没有登录成功。
POST后得到的内容中包含一句 location.replace("http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3%DC%C2%EB%B4%ED%CE%F3");
这是登录失败时的结果。登录成功后的结果类似,只是retcode的值为0,然后再次请求这个网址,这样就可以成功登录微博了。
记得提前构建缓存。
以下是完整代码(不做注释,一起来看看):
#! /usr/bin/env python
#coding=utf8
import urllib
import urllib2
import cookielib
import base64
import re
import json
import hashlib
cj = cookielib.LWPCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
postdata = {
\'entry\': \'weibo\',
\'gateway\': \'1\',
\'from\': \'\',
\'savestate\': \'7\',
\'userticket\': \'1\',
\'ssosimplelogin\': \'1\',
\'vsnf\': \'1\',
\'vsnval\': \'\',
\'su\': \'\',
\'service\': \'miniblog\',
\'servertime\': \'\',
\'nonce\': \'\',
\'pwencode\': \'wsse\',
\'sp\': \'\',
\'encoding\': \'UTF-8\',
\'url\': \'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack\',
\'returntype\': \'META\'
}
def get_servertime():
url = \'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=dW5kZWZpbmVk&client=ssologin.js(v1.3.18)&_=1329806375939\'
data = urllib2.urlopen(url).read()
p = re.compile(\'\((.*)\)\')
try:
json_data = p.search(data).group(1)
data = json.loads(json_data)
servertime = str(data[\'servertime\'])
nonce = data[\'nonce\']
return servertime, nonce
except:
print \'Get severtime error!\'
return None
def get_pwd(pwd, servertime, nonce):
pwd1 = hashlib.sha1(pwd).hexdigest()
pwd2 = hashlib.sha1(pwd1).hexdigest()
pwd3_ = pwd2 + servertime + nonce
pwd3 = hashlib.sha1(pwd3_).hexdigest()
return pwd3
def get_user(username):
username_ = urllib.quote(username)
username = base64.encodestring(username_)[:-1]
return username
def login():
username = \'你的登录邮箱\'
pwd = \'你的密码\'
url = \'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.3.18)\'
try:
servertime, nonce = get_servertime()
except:
return
global postdata
postdata[\'servertime\'] = servertime
postdata[\'nonce\'] = nonce
postdata[\'su\'] = get_user(username)
postdata[\'sp\'] = get_pwd(pwd, servertime, nonce)
postdata = urllib.urlencode(postdata)
headers = {\'User-Agent\':\'Mozilla/5.0 (X11; Linux i686; rv:8.0) Gecko/20100101 Firefox/8.0\'}
req = urllib2.Request(
url = url,
data = postdata,
headers = headers
)
result = urllib2.urlopen(req)
text = result.read()
p = re.compile(\'location\.replace\(\'(.*?)\'\)\')
try:
login_url = p.search(text).group(1)
#print login_url
urllib2.urlopen(login_url)
print "登录成功!"
except:
print \'Login error!\'
login()
(二)模拟登录新浪微博(直接填写Cookie)
之前写过一个模拟登录新浪微博,使用POST用户名/密码参数(加密)并保存Cookies来模拟登录。
一般情况下,为了保证安全,网站会定期更新登录细节,比如修改参数名,更新加密(散列)算法等,所以模拟登录的代码肯定会周期性的失败,但是如果网站 没有进行大的更新,稍微修改一下还是可以使用的。此外,验证码的处理难度更大。虽然该程序在一定程度上可以识别验证码字符,但目前还很难找到一个简单通用的验证码识别程序。
很多豆友反映,他们需要模拟登录新浪微博来抓取数据。事实上,对于一般的微博数据获取,比如用户信息、微博内容等,使用微博开放平台API是更明智的选择:速度更快,并且在网页处理上节省大量精力。对于没有对API开放的数据,我们再采用模拟登录的方式。
熟悉网络的朋友只要定期维护模拟登录的代码就可以成功登录微博。如果你不是很熟悉,其实可以用更幼稚的方法来解决:直接将Cookie发送到新浪微博,实现模拟登录。
1. 获取饼干
这很简单。您可以通过Chrome浏览器的“开发者工具”或火狐浏览器的“HTTPFOX”等插件直接查看您的新浪微博cookies。(注意:不要泄露这个私人Cookie!)
比如Chrome查看cookie(快捷键F12可以调出chrome开发者工具)
镀铬饼干
镀铬饼干
2. 提交Cookie作为访问微博的header参数
headers = {\'cookie\': \'你的 cookie\'}
req = urllib2.Request(url, headers=headers) #每次访问页面时,带上headers参数
r = urllib2.urlopen(req)
具体代码见:
(三)多蠢的cookie问题,最后还是自己解决了...
我不太了解HTTP中的协议和东西,但我知道有这样的东西。是时候阅读《HTTP 权威指南》这本书了,以免...
同学说可以用cookies登录人人网、微博什么的,他是网络安全高手,黑客类,我这方面菜鸟,所以很想试试。
网上找了很多资源,包括模拟登录新浪微博(直接填写Cookie)
我知道在哪里可以找到 cookie,就像这样(我使用 chrome)
点击进去,它看起来像这样
不,这个想法是灵活的。肯定是打开方式不对……所以,打开F12,打开浏览器控制台,查看网络页面,像这样:
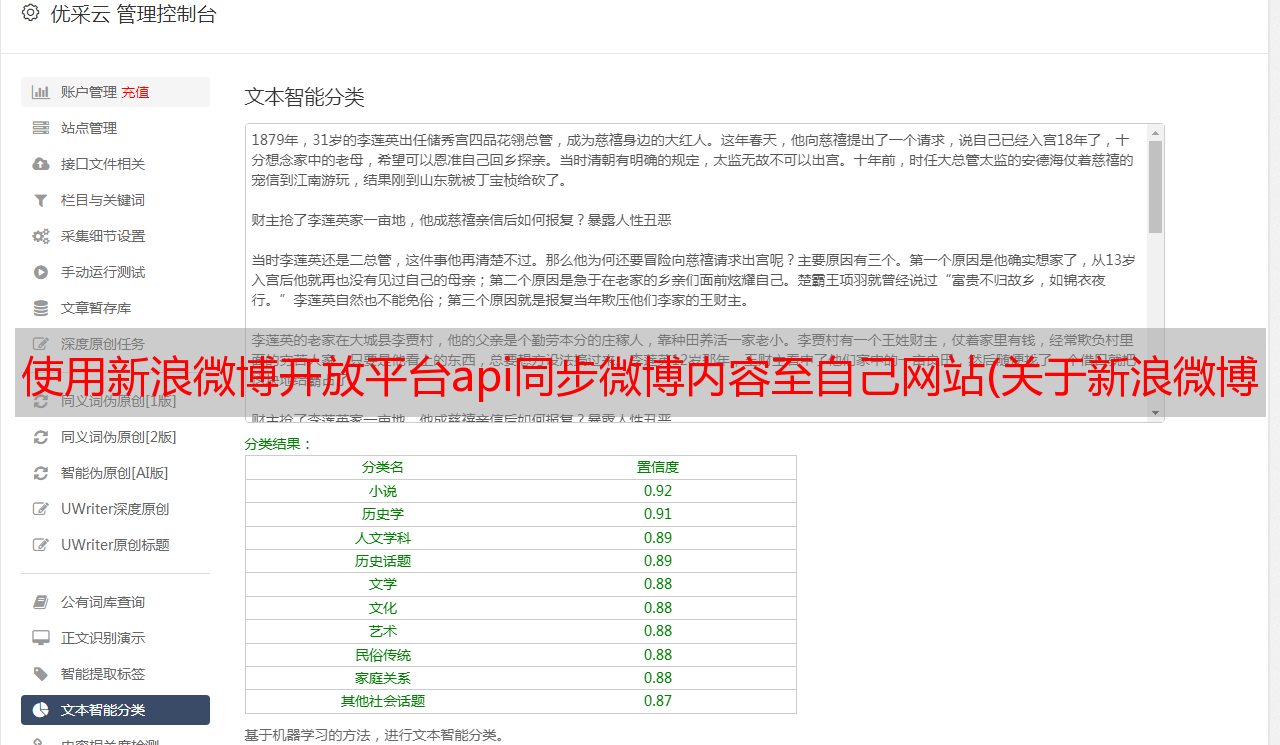
赶快去地址输入网址吧!!我们会发现很多东西经过
看到了,是蓝色的东西,复制粘贴,粘贴到代码里,就好了
最后,抓取ajax
(四)使用python实现新浪微博爬虫
接下来考虑爬取微博内容的实现。
这时,我遇到了困难。当我抓取指定网址的微博时,最初只显示了15条。后者是延迟显示(在ajax中称为延迟加载?)。也就是说,当滚动条第一次拖到底部时,会显示第二部分,然后再拖到底部,会显示第三部分。此时,一个页面的微博就完成了。因此,要获取一个微博页面的所有微博,需要访问该页面3次。创建getWeiboPage.py文件,对应代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib
import urllib2
import sys
import time
reload(sys)
sys.setdefaultencoding(\'utf-8\')
class getWeiboPage:
body = {
\'__rnd\':\'\',
\'_k\':\'\',
\'_t\':\'0\',
\'count\':\'50\',
\'end_id\':\'\',
\'max_id\':\'\',
\'page\':1,
\'pagebar\':\'\',
\'pre_page\':\'0\',
\'uid\':\'\'
}
uid_list = []
charset = \'utf8\'
def get_msg(self,uid):
getWeiboPage.body[\'uid\'] = uid
url = self.get_url(uid)
self.get_firstpage(url)
self.get_secondpage(url)
self.get_thirdpage(url)
def get_firstpage(self,url):
getWeiboPage.body[\'pre_page\'] = getWeiboPage.body[\'page\']-1
url = url +urllib.urlencode(getWeiboPage.body)
req = urllib2.Request(url)
result = urllib2.urlopen(req)
text = result.read()
self.writefile(\'./output/text1\',text)
self.writefile(\'./output/result1\',eval("u\'\'\'"+text+"\'\'\'"))
def get_secondpage(self,url):
getWeiboPage.body[\'count\'] = \'15\'
# getWeiboPage.body[\'end_id\'] = \'3490160379905732\'
# getWeiboPage.body[\'max_id\'] = \'3487344294660278\'
getWeiboPage.body[\'pagebar\'] = \'0\'
getWeiboPage.body[\'pre_page\'] = getWeiboPage.body[\'page\']
url = url +urllib.urlencode(getWeiboPage.body)
req = urllib2.Request(url)
result = urllib2.urlopen(req)
text = result.read()
self.writefile(\'./output/text2\',text)
self.writefile(\'./output/result2\',eval("u\'\'\'"+text+"\'\'\'"))
def get_thirdpage(self,url):
getWeiboPage.body[\'count\'] = \'15\'
getWeiboPage.body[\'pagebar\'] = \'1\'
getWeiboPage.body[\'pre_page\'] = getWeiboPage.body[\'page\']
url = url +urllib.urlencode(getWeiboPage.body)
req = urllib2.Request(url)
result = urllib2.urlopen(req)
text = result.read()
self.writefile(\'./output/text3\',text)
self.writefile(\'./output/result3\',eval("u\'\'\'"+text+"\'\'\'"))
def get_url(self,uid):
url = \'http://weibo.com/\' + uid + \'?from=otherprofile&wvr=3.6&loc=tagweibo\'
return url
def get_uid(self,filename):
fread = file(filename)
for line in fread:
getWeiboPage.uid_list.append(line)
print line
time.sleep(1)
def writefile(self,filename,content):
fw = file(filename,\'w\')
fw.write(content)
fw.close()

