实时抓取网页数据( 大数据舆情系统对数据存储和计算系统会有哪些需求)
优采云 发布时间: 2021-12-19 03:00实时抓取网页数据(
大数据舆情系统对数据存储和计算系统会有哪些需求)
互联网的飞速发展促进了许多新媒体的发展。无论是知名大V、名人还是围观者,都可以用手机在微博、朋友圈或评论网站上发布动态,分享所见所想,让“人人有话筒”。 ” 无论是热点新闻还是娱乐八卦,传播速度都远超我们的想象。一条信息可以在短短几分钟内被数万人转发,数百万人阅读。海量信息是可以爆炸的,那么如何实时掌握信息并进行相应的处理呢?真的很难对付吗?今天,
大数据时代,除了媒体信息外,各个电商平台的产品订单和用户购买评论都会对后续消费者产生很大的影响。商家的产品设计师需要对各个平台的数据进行统计和分析,作为确定后续产品开发的依据。公司公关和营销部门也需要根据舆情做出相应的及时处理,而这一切也意味着将传统的舆情系统升级为大数据舆情采集和分析系统。细看大数据舆情系统,对我们的数据存储和计算系统提出以下要求:
本文主要提供架构设计。首先介绍当前主流的大数据计算架构,分析一些优缺点,然后介绍舆情大数据架构。
系统设计
需求分析
结合文章开头对舆情系统的描述,海量大数据舆情分析系统流程图大致如下:
图1 舆情系统业务流程
根据前面的介绍,舆情大数据分析系统需要两种计算。一是实时计算,包括实时提取海量网页内容、情感词分析、网页舆情结果存储等。另一种是离线计算。系统需要回溯历史数据,结合人工标注等方法优化情感词汇,对一些实时计算的结果进行修正。因此,在系统设计中,需要选择一个既可以进行实时计算又可以进行批量离线计算的系统。在开源大数据解决方案中,Lambda 架构可以满足这些需求。下面介绍一下 Lambda 架构。
Lambda 架构(维基)
图2 Lambda架构图
Lambda架构可以说是Hadoop、Spark系统下最火的大数据架构。这种架构的最大优点是支持海量数据批量计算处理(即离线处理),也支持流式实时处理(即热数据处理)。
它是如何实施的?首先,上游一般是kafka等队列服务,实时存储数据。Kafka队列会有两个订阅者,一个是全量数据,也就是图片的上半部分,全量数据会存储在HDFS这样的存储介质上。当离线计算任务到来时,计算资源(如Hadoop)会访问存储系统上的全量数据,执行全批量计算的处理逻辑。
map/reduce链接后,完整的结果会写入到Hbase等结构化存储引擎中,提供给业务方查询。队列的另一个消费者订阅者是流计算引擎。流计算引擎往往实时消费队列中的数据进行计算处理。比如Spark Streaming实时订阅Kafka数据,流计算的结果也写入结构化数据引擎。写入批量计算和流计算结果的结构化存储引擎就是上面注3所示的“Serving Layer”。该层主要提供结果数据的展示和查询。
在这套架构中,批量计算的特点是需要支持海量数据的处理,并根据业务的需要,关联一些其他的业务指标进行计算。批量计算的优点是计算逻辑可以根据业务需求灵活调整,计算结果可以重复计算,同一个计算逻辑不会多次变化。批量计算的缺点是计算周期比较长,难以满足实时结果的需求。因此,随着大数据计算的演进,提出了实时计算的需求。
实时计算是通过 Lambda 架构中的实时数据流来实现的。与批处理相比,增量数据流的处理方式决定了数据往往是新生成的数据,即热点数据。由于热数据的特性,流计算可以满足业务对计算的低时延需求。例如,在一个舆情分析系统中,我们往往希望可以从网页中检索舆情信息,并在分钟级得到计算结果,以便业务方有足够的时间进行舆情反馈。下面我们来具体看看如何基于Lambda架构的思想,实现一套完整的舆情大数据架构。
开源舆情大数据解决方案
通过这个流程图,我们了解到整个舆情系统的构建需要不同的存储和计算系统。对数据的组织和查询有不同的要求。基于业界开源的大数据系统,结合Lambda架构,整个系统可以设计如下:
图3 开源舆情架构图
1. 系统最上游是分布式爬虫引擎,根据爬取任务对订阅网页的原创内容进行爬取。爬虫会实时将爬取到的网页内容写入Kafka队列。进入Kafka队列的数据会根据上述计算需求实时流入流计算引擎(如Spark或Flink),也会持久化存储在Hbase中进行全量处理。数据存储。全量网页的存储,可以满足网页爬取和去重,批量离线计算的需要。
2. 流计算会提取原创网页的结构,将非结构化的网页内容转化为结构化数据并进行分词,如提取页面的标题、作者、摘要等,对文本进行分词和抽象的内容。提取和分词结果会写回Hbase。经过结构化提取和分词后,流计算引擎会结合情感词汇分析网页情感,判断是否有舆情。
3. 流计算引擎分析的舆情结果存储在Mysql或Hbase数据库中。为了方便搜索和查看结果集,需要将数据同步到Elasticsearch等搜索引擎,方便属性字段的组合查询。如果是重大舆情时间,需要写入Kafka队列触发舆情警报。
4. 全量结构化数据会定期通过Spark系统离线计算更新情感词汇或接受新的计算策略重新计算历史数据以修正实时计算的结果。
开源架构分析
上面的舆情大数据架构,通过Kafka对接流计算,Hbase对接批量计算实现了Lambda架构中的“批量查看”和“实时查看”,整个架构比较清晰,可以很好的满足线上和离线 两种类型的计算需求。但是,将该系统应用到生产中并不是一件容易的事,主要有以下几个原因:
整个架构涉及到很多存储和计算系统,包括:Kafka、Hbase、Spark、Flink、Elasticsearch。数据将在不同的存储和计算系统中流动。在整个架构中运行和维护每个开源产品是一个很大的挑战。任何一款产品或产品之间的通道出现故障都会影响整体舆情分析结果的及时性。
为了实现批量计算和流计算,原创网页需要分别存储在Kafka和Hbase中。离线计算消费HBase中的数据,流计算消费Kafka中的数据。这会带来存储资源的冗余,也会导致需要维护两套计算逻辑,会增加计算代码的开发和维护成本。
舆情的计算结果存储在Mysql或Hbase中。为了丰富组合查询语句,需要将数据同步并内置到Elasticsearch中。查询时,可能需要结合Mysql和Elasticsearch的查询结果。这里没有跳过数据库,结果数据直接写入Elasticsearch等搜索系统中,因为搜索系统的实时数据写入能力和数据可靠性不如数据库。行业通常将数据库和搜索系统集成在一起,集成系统兼具数据库和搜索系统的优点,但是两个引擎之间的数据同步和跨系统查询给运维和维护带来了很多额外的成本。发展。
全新大数据架构 Lambda plus
通过前面的分析,相信大家都会有一个疑问。有没有一种简化的大数据架构可以满足Lambda对计算需求的假设,同时减少存储计算和模块的数量?
Linkedin 的 Jay Kreps 提出了 Kappa 架构。Lambda和Kappa的对比可以参考文末文档。详细的比较这里就不展开了。简单来说,为了简化两个存储,Kappa取消了全量数据存储。通过将它们保存在 Kafka 中,对于较长的日志,当需要回溯重新计算时,再次从队列头部订阅数据,所有存储在 Kafka 队列中的数据再次在流中处理。这种设计的好处是解决了维护两套存储和两套计算逻辑的痛点。缺点是队列能保留的历史数据毕竟有限,没有时间限制很难回溯。
分析到此,我们沿用Kappa对Lambda的改进思路,更远的思考:如果有存储引擎,不仅可以满足数据库的高效写入和随机查询,还可以像队列服务一样,满足第一—— in first-out, yes 不是可以结合Lambda和Kappa架构来创建Lambda plus架构吗?
新架构可以在Lambda的基础上改进以下几点:
在支持流计算和批量计算的同时,可以复用计算逻辑,实现“一套代码,两类需求”。
统一存储全量历史数据和在线实时增量数据,实现“一存两算”。
为了方便舆情结果的查询需求,“批量查看”和“实时查看”的存储不仅可以支持高吞吐量实时写作,还可以支持多字段组合搜索和全文检索恢复。
综上所述,整个新架构的核心是解决存储问题,以及如何灵活连接计算。我们希望整个程序类似于以下架构:
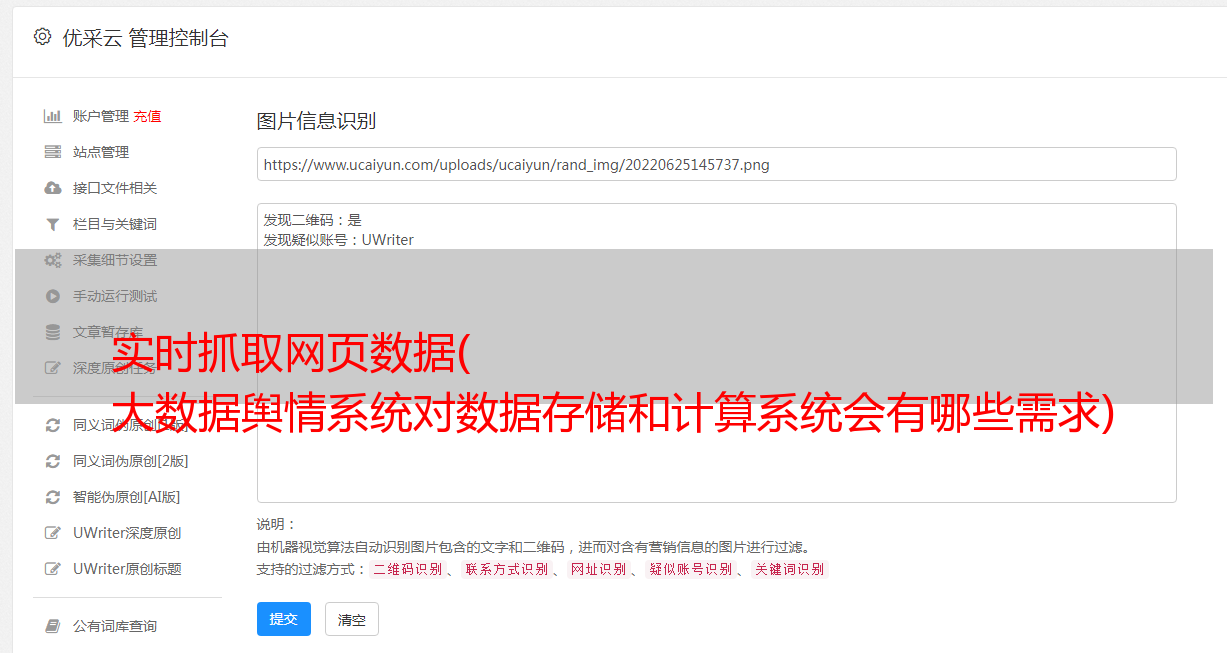
图 4 Lambda Plus 架构
数据流实时写入分布式数据库。借助数据库查询能力,可以轻松将全量数据接入批量计算系统进行离线处理。
数据库支持通过数据库日志接口增量读取,并结合流计算引擎实现实时计算。
批计算和流计算的结果回写到分布式数据库中。分布式数据库提供丰富的查询语义,实现计算结果的交互查询。
在整个架构中,存储层通过结合数据库主表数据和数据库日志来替代大数据架构中的队列服务。计算系统选择自然支持batch和stream的计算引擎,如Flink或Spark。这样,我们不仅可以像 Lambda 那样进行历史数据回溯,还可以像 Kappa 架构那样进行一套逻辑来存储和处理两类计算任务。我们将这样一套架构命名为“Lambda plus”,下面详细介绍如何在阿里云上搭建这样一套大数据架构。
云舆情系统架构
在阿里云众多的存储和计算产品中,为了满足上述大数据架构的需求,我们选择了两款产品来实现整个舆情大数据系统。存储层使用阿里云自研的分布式多模型数据库Tablestore,计算层使用Blink实现流一体和批量计算。
图5 云舆情大数据架构
在存储层面,这个架构都是基于Tablestore的。一个数据库解决不同的存储需求。根据之前舆情系统的介绍,网络爬虫数据的系统流程会有四个阶段:原创网页内容、网页结构化数据、分析规则。元数据和舆情结果,舆情结果索引。
我们利用Tablestore的宽行和无模式特性将原创网页和网页结构化数据合并为一个网页数据。网页数据表和计算系统通过Tablestore新的功能通道服务连接起来。通道服务基于数据库日志,按照数据写入的顺序存储数据的组织结构。正是这个特性,让数据库具备了排队和流式消费的能力。这使得存储引擎既可以随机访问数据库,也可以按写入顺序访问队列,也满足了上面提到的集成Lambda和kappa架构的需求。分析规则元数据表由分析规则和情感词汇组层组成,
计算系统采用阿里云实时流计算产品Blink。Blink 是一款支持流计算和批量计算的实时计算产品。并且类似于Tablestore,它可以轻松实现分布式横向扩展,让计算资源随着业务数据的增长而灵活扩展。使用Tablestore+Blink的优势如下:
Tablestore与Blink深度集成,支持源表、维度表、目的表。无需为业务中的数据流开发代码。
整个架构大大减少了组件数量,从开源产品的6~7个组件减少到2个。Tablestore和Blink都是零运维的全托管产品,可以实现非常好的横向灵活性,没有业务扩张高峰。压力大大降低了大数据架构的运维成本。
业务侧只需要关注数据处理逻辑,Blink中已经集成了与Tablestore的交互逻辑。
在开源方案中,如果数据库源想要连接实时计算,还需要写一个队列,让流计算引擎消费队列中的数据。在我们的架构中,数据库既是数据表,也是实时增量数据消费的队列通道。大大简化了架构的开发和使用成本。
流式批处理集成,实时性在舆情系统中很重要,所以我们需要一个实时计算引擎,而Blink除了实时计算,还支持Tablestore数据的批处理,在低峰期业务的,往往也需要批量处理一些数据作为反馈结果写回Tablestore,比如情感分析反馈。所以一套架构可以同时支持流处理和批处理更好。一套架构的优势在于一套分析代码既可以用于实时流式计算,也可以用于离线批处理。
整个计算过程会产生实时的舆情计算结果。通过Tablestore与函数计算触发器的对接,实现重大舆情事件预警。Tablestore和函数计算做了增量数据的无缝对接。通过在结果表中写入事件,您可以通过函数计算轻松触发短信或电子邮件通知。完整的舆情分析结果和展示搜索使用Tablestore的新功能多索引,彻底解决了开源Hbase+Solr多引擎的痛点:
运维复杂,需要有hbase和solr两个系统的运维能力,还需要维护数据同步的链接。
Solr 数据一致性不如Hbase。Hbase 和 Solr 中数据的语义并不完全相同。另外,Solr/Elasticsearch 很难做到像数据库一样严格的数据一致性。在一些极端情况下,可能会出现数据不一致的情况,开源解决方案很难实现跨系统的一致性比较。
查询接口需要维护两套API。Hbase客户端和Solr客户端都需要用到。不在索引中的字段需要主动对照Hbase进行检查,不太好用。
参考
Lambda 大数据架构:
Kappa大数据架构:
Lambda 和 Kappa 架构比较:
【编辑推荐】
你只知道熊猫吗?数据科学家不容错过的 24 个 Python 库(第 1 部分)。在 Fedora 上构建 Jupyter 和数据科学环境。基于Python语言的大数据搜索引擎。使用 Python 加速数据分析的 10 个简单技巧。分布式文件服务器。你还在手工搭建分布式文件服务器吗?一步一步来试试Docker镜像

